
一、测试概述
本次压测旨在验证基于Ceph存储集群在GPU服务器高负载场景下的性能表现,涵盖顺序读写、随机读写、高并发IOPS及延迟控制等多个维度。测试采用fio工具,模拟多种I/O模式,评估存储系统的吞吐量、IOPS与延迟表现。
二、硬件配置概述
1. Ceph存储节点(3台)
- CPU:SR660V2 5318Y × 2
- 内存:256GB
- 数据盘组合:
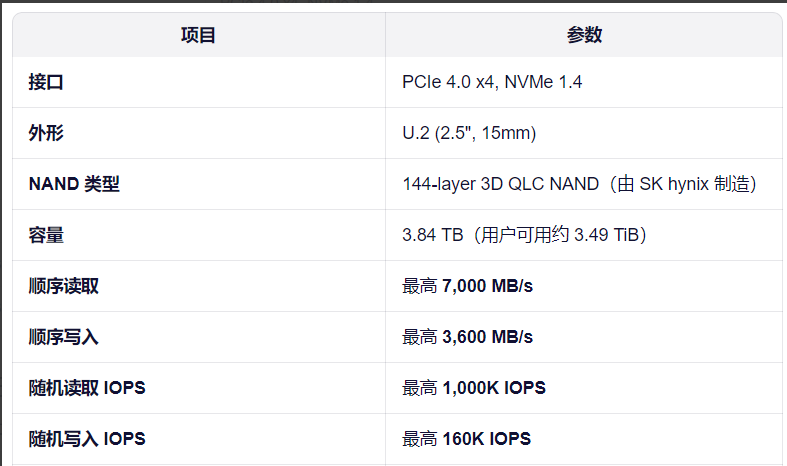
- 4 × 3.84TB NVMe U.2(PCIe 4.0, QLC NAND)
- 网络:双口100G网卡
2. GPU客户端服务器
- CPU:Intel Xeon Platinum 8558,192核
- 内存:2TB
- 网络:400Gbps网卡
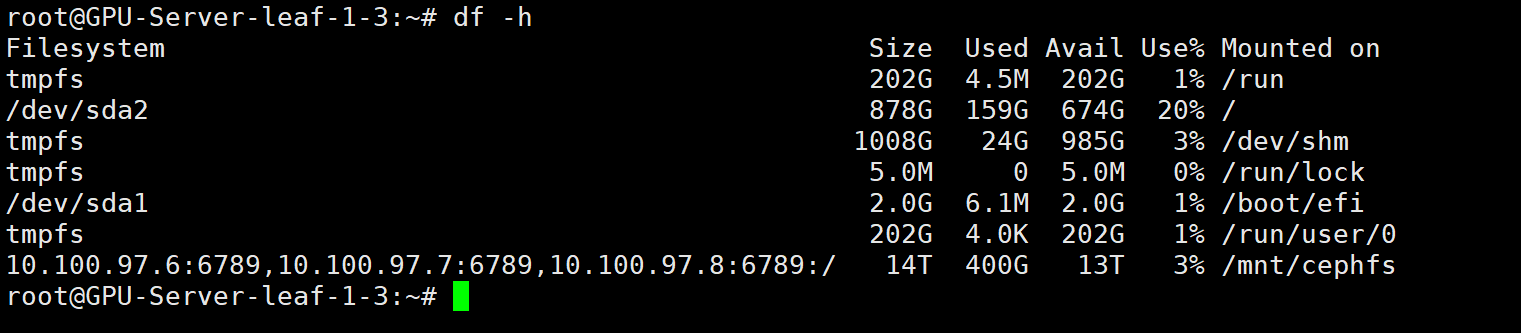
- CephFS挂载点:容量14TB
# CPU
CPU(s): 192
On-line CPU(s) list: 0-191
Vendor ID: GenuineIntel
Model name: INTEL(R) XEON(R) PLATINUM 8558
CPU family: 6
Model: 207
Thread(s) per core: 2
Core(s) per socket: 48
# 内存
root@GPU-Server-leaf-1-3:~# free -h
total used free shared buff/cache available
Mem: 2.0Ti 16Gi 1.9Ti 23Gi 23Gi 1.9Ti
# 网卡速率
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Advertised FEC modes: RS
Speed: 400000Mb/s
Duplex: Full
Auto-negotiation: on
Port: FIBRE
PHYAD: 0
Transceiver: internal
Supports Wake-on: d
Wake-on: d
Link detected: yes
三、吞吐量压测
4M顺序写-吞吐
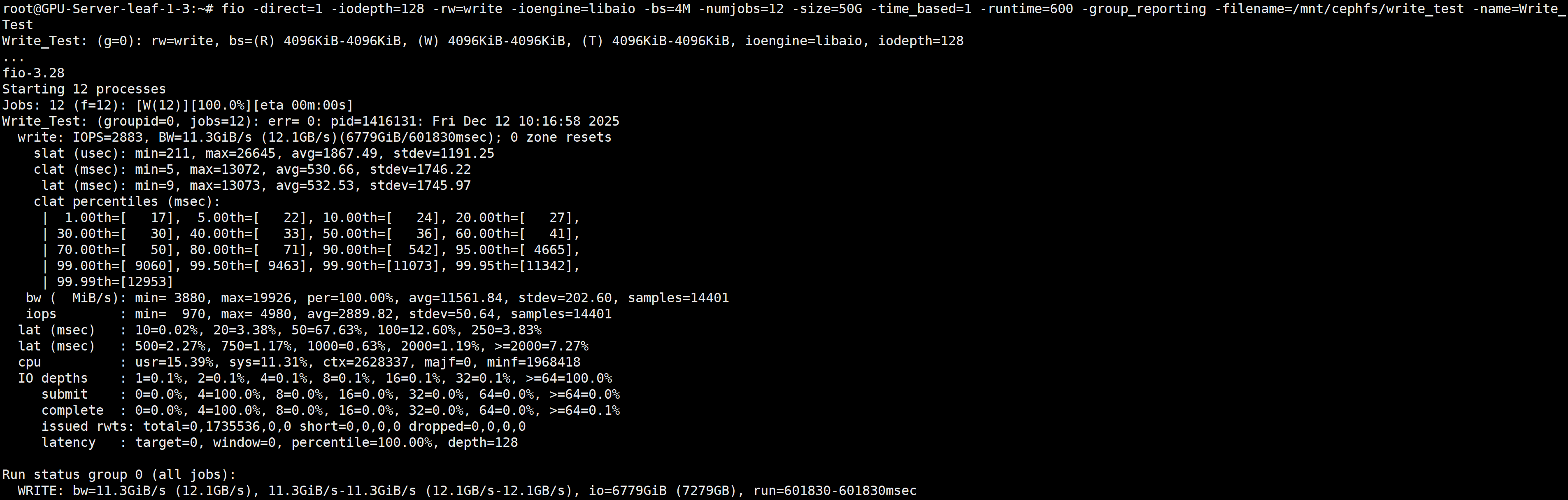
fio -direct=1 -iodepth=128 -rw=write -ioengine=libaio -bs=4M -numjobs=12 -size=50G -time_based=1 -runtime=600 -group_reporting -filename=/mnt/cephfs/write_test -name=Write_Test
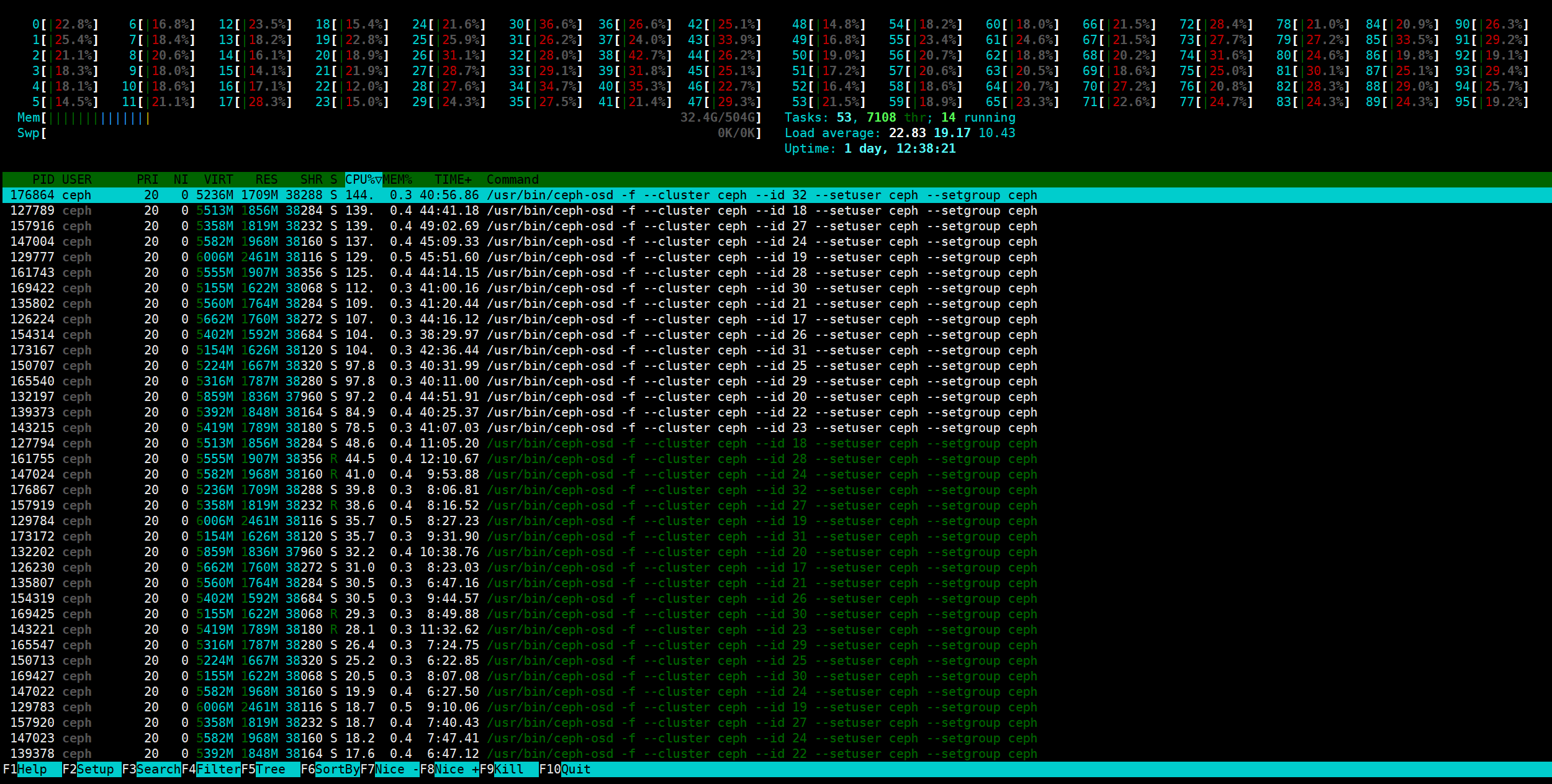
CPU/内存使用率
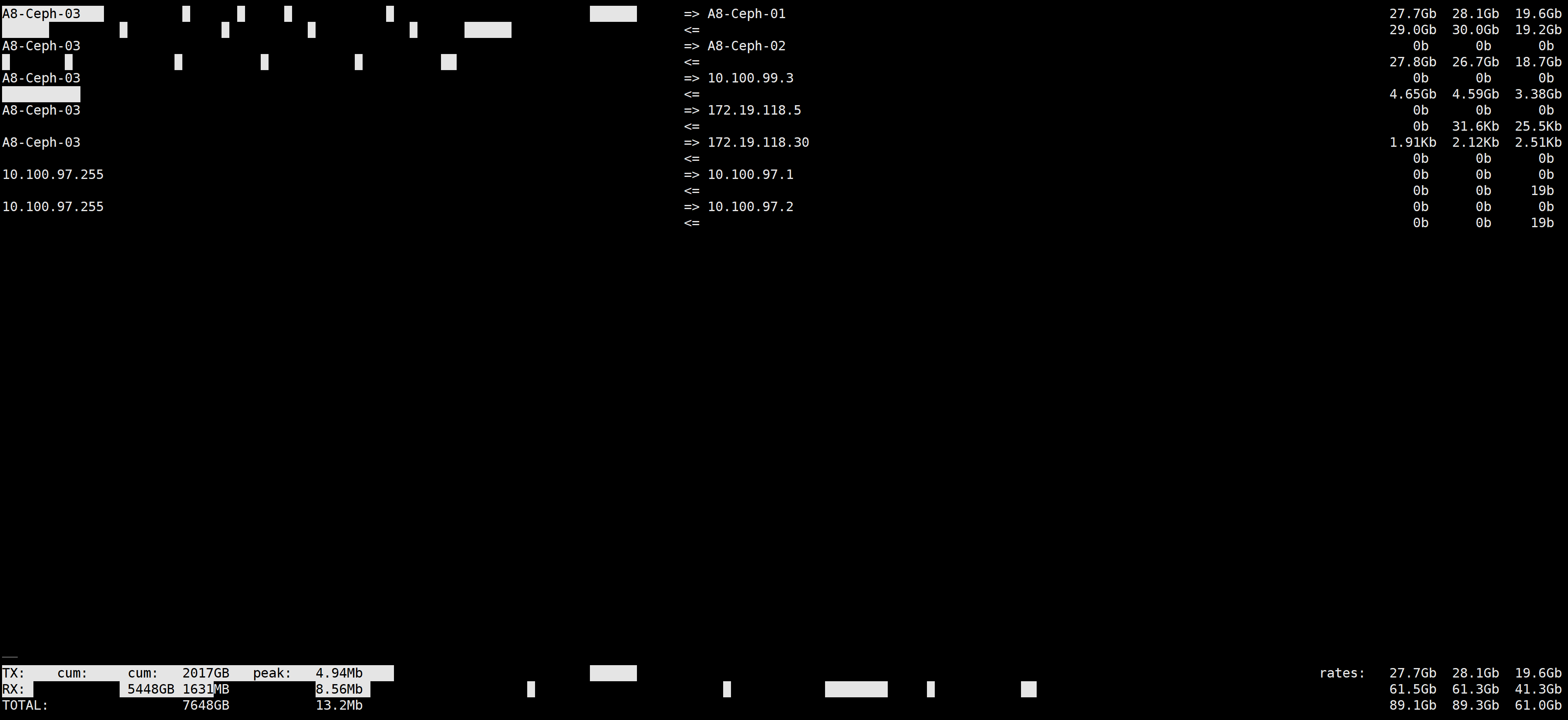
网卡速率
磁盘使用率

吞吐量 11.3GiB/s 延迟 532ms/s
4M顺序读-吞吐
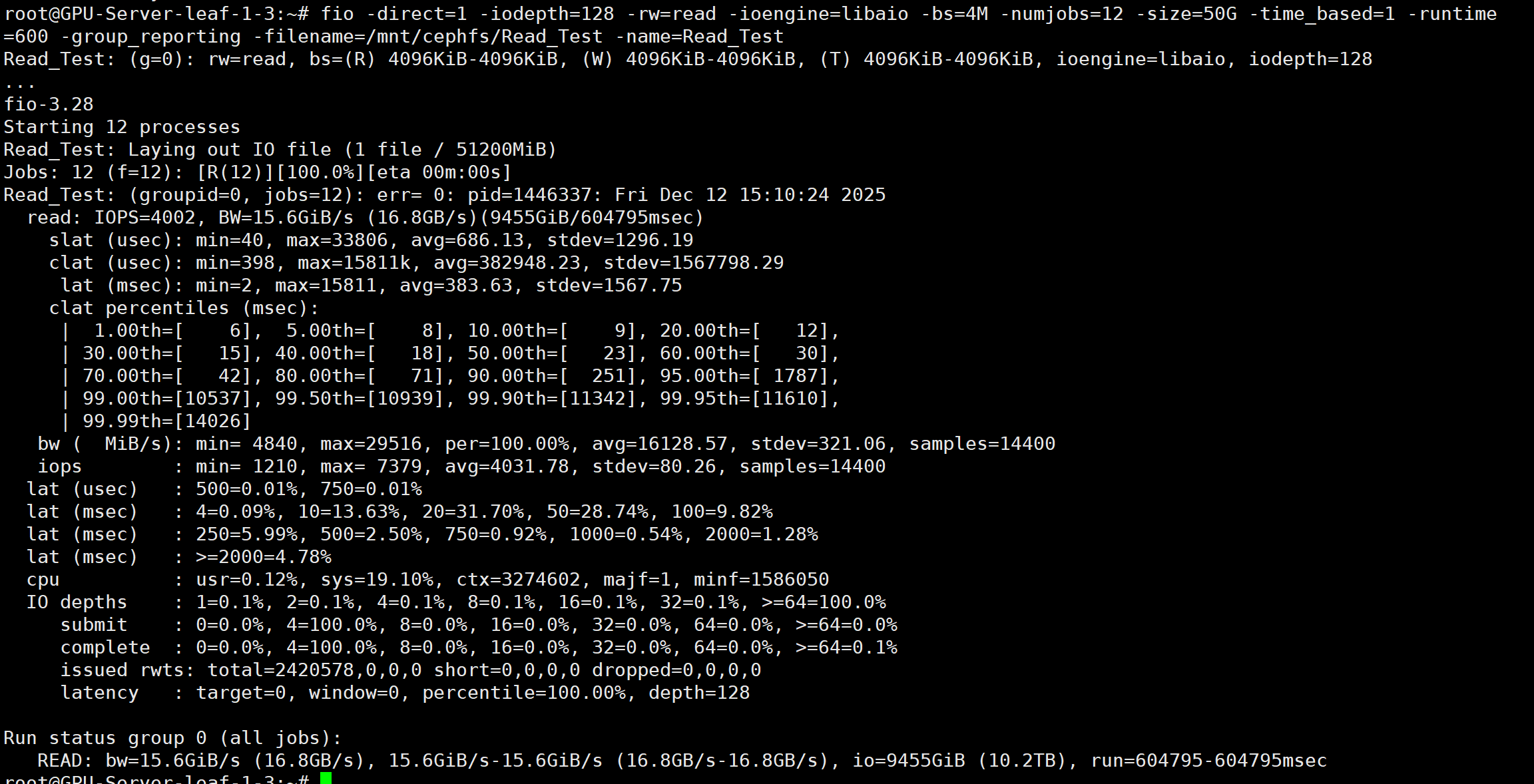
fio -direct=1 -iodepth=128 -rw=read -ioengine=libaio -bs=4M -numjobs=12 -size=50G -time_based=1 -runtime=600 -group_reporting -filename=/mnt/cephfs/Read_Test -name=Read_Test
吞吐量 15.6GiB/s 延迟383ms/s
4M顺序读写-吞吐
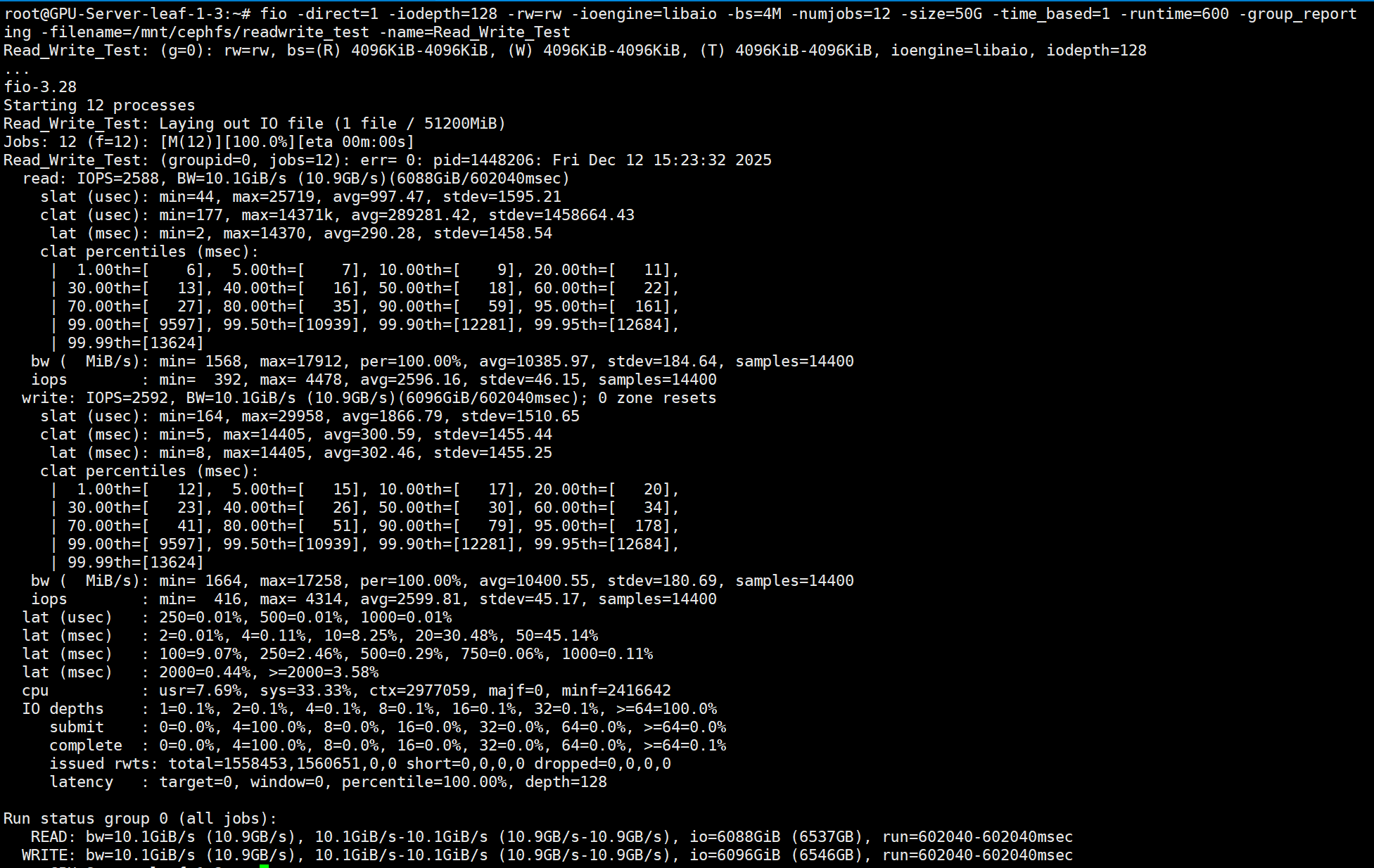
fio -direct=1 -iodepth=128 -rw=rw -ioengine=libaio -bs=4M -numjobs=12 -size=50G -time_based=1 -runtime=600 -group_reporting -filename=/mnt/cephfs/readwrite_test -name=Read_Write_Test
读写吞吐量 10.1GiB/s 延迟290-302ms
四、IOPS压测
<5ms延迟 4K 随机写-IOPS
# numjobs=4
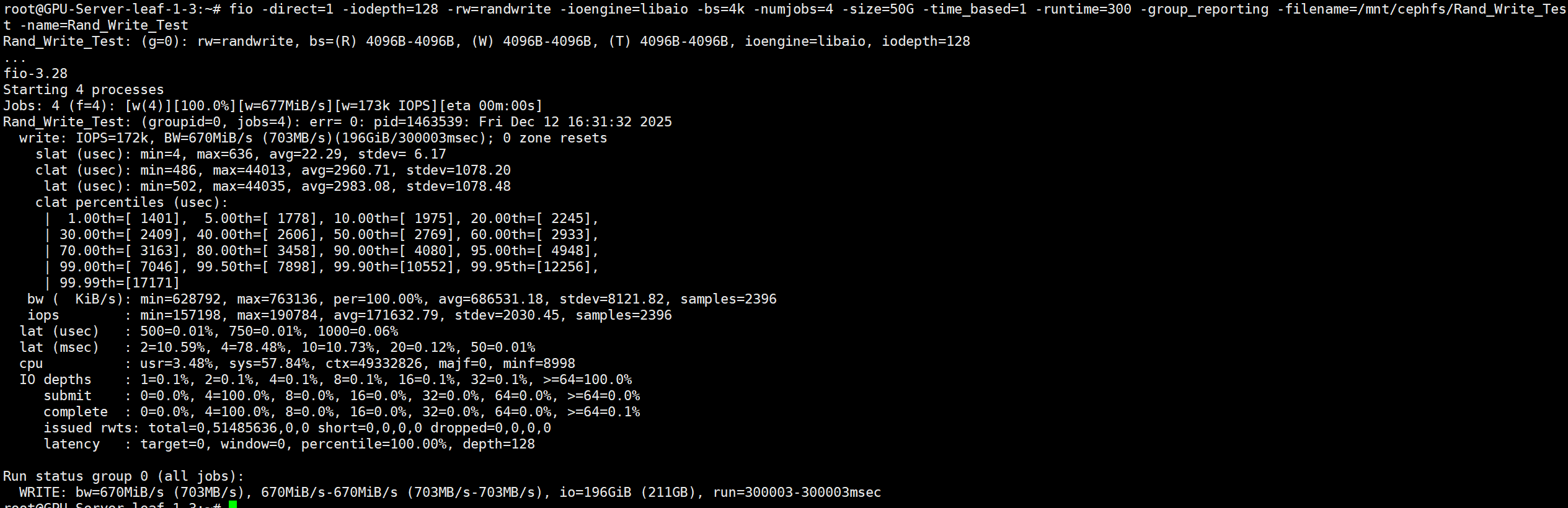
fio -direct=1 -iodepth=128 -rw=randwrite -ioengine=libaio -bs=4k -numjobs=4 -size=50G -time_based=1 -runtime=300 -group_reporting -filename=/mnt/cephfs/Rand_Write_Test -name=Rand_Write_Test
IOPS 172K/s 延迟3ms/s
- 平均延迟 (
lat avg) 3ms - 延迟分布 (
95.00th) 95%请求<5ms - 平均IOPS 172K/s
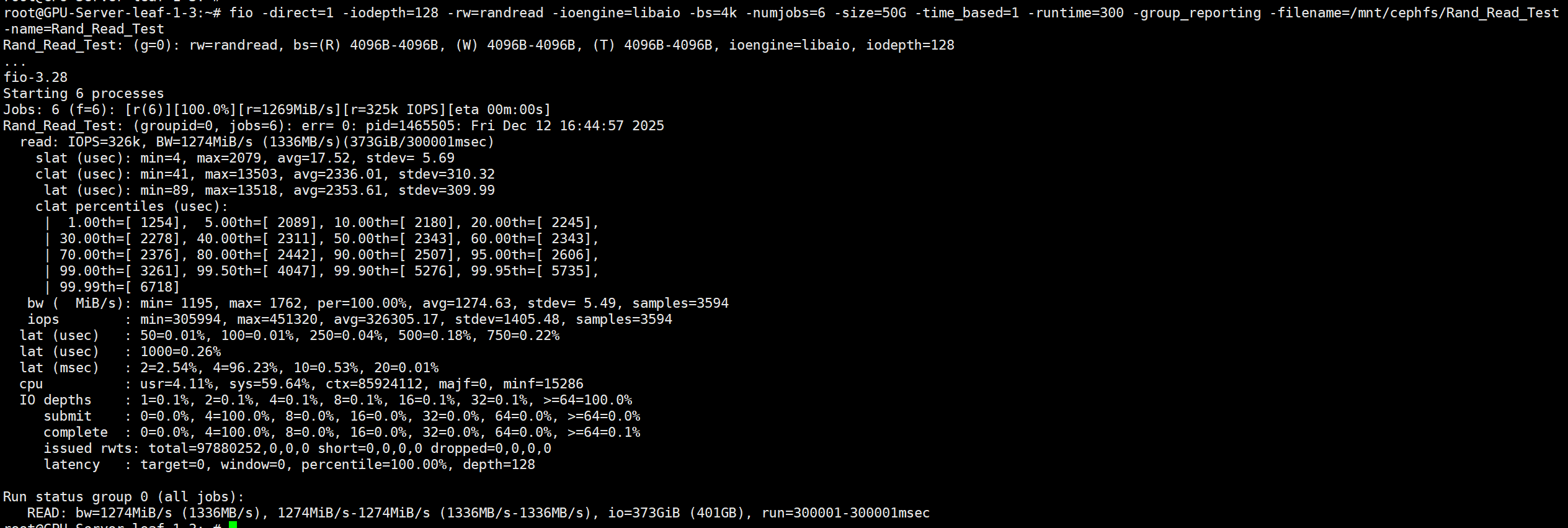
<5ms延迟 4k 随机读-IOPS
# numjobs=6
fio -direct=1 -iodepth=128 -rw=randread -ioengine=libaio -bs=4k -numjobs=6 -size=50G -time_based=1 -runtime=300 -group_reporting -filename=/mnt/cephfs/Rand_Read_Test -name=Rand_Read_Test
IOPS 326K/s 延迟2.4ms/s
- 平均延迟 (
lat avg) 2.4ms - 延迟分布 (
99.90th) 99.9%请求<5.3ms - 平均IOPS 326K/s
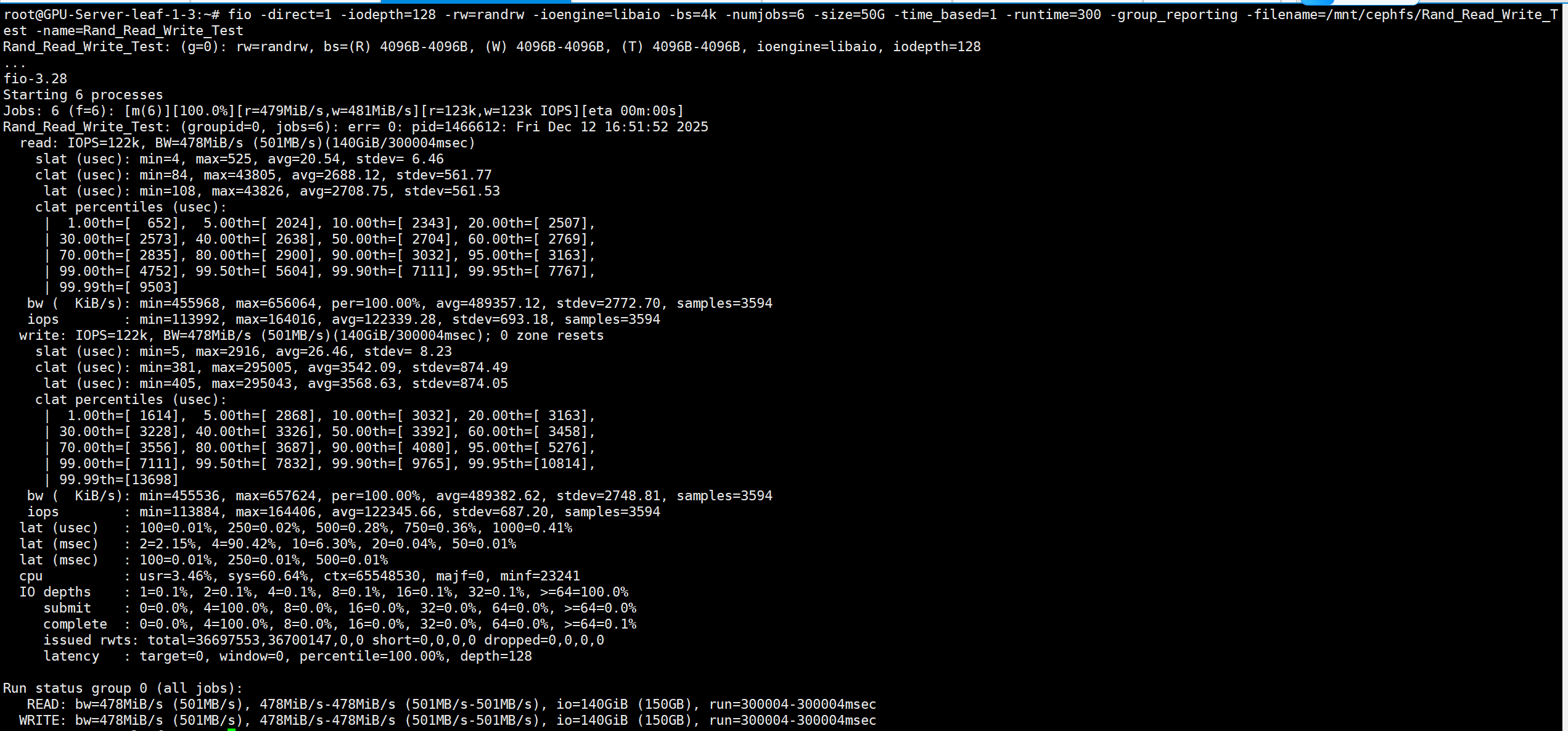
<5ms延迟 4k 随机读写-IOPS
# numjobs=6
fio -direct=1 -iodepth=128 -rw=randrw -ioengine=libaio -bs=4k -numjobs=6 -size=50G -time_based=1 -runtime=300 -group_reporting -filename=/mnt/cephfs/Rand_Read_Write_Test -name=Rand_Read_Write_Test
读写IOPS 122K/s
- 读平均延迟 (
lat avg) 2.7ms - 写平均延迟 (
lat avg) 3.5ms - 读延迟分布 (
99.00th) 99%请求<5ms - 写延迟分布 (
95.00th) 95%请求<5.3ms - 平均IOPS 122K/s
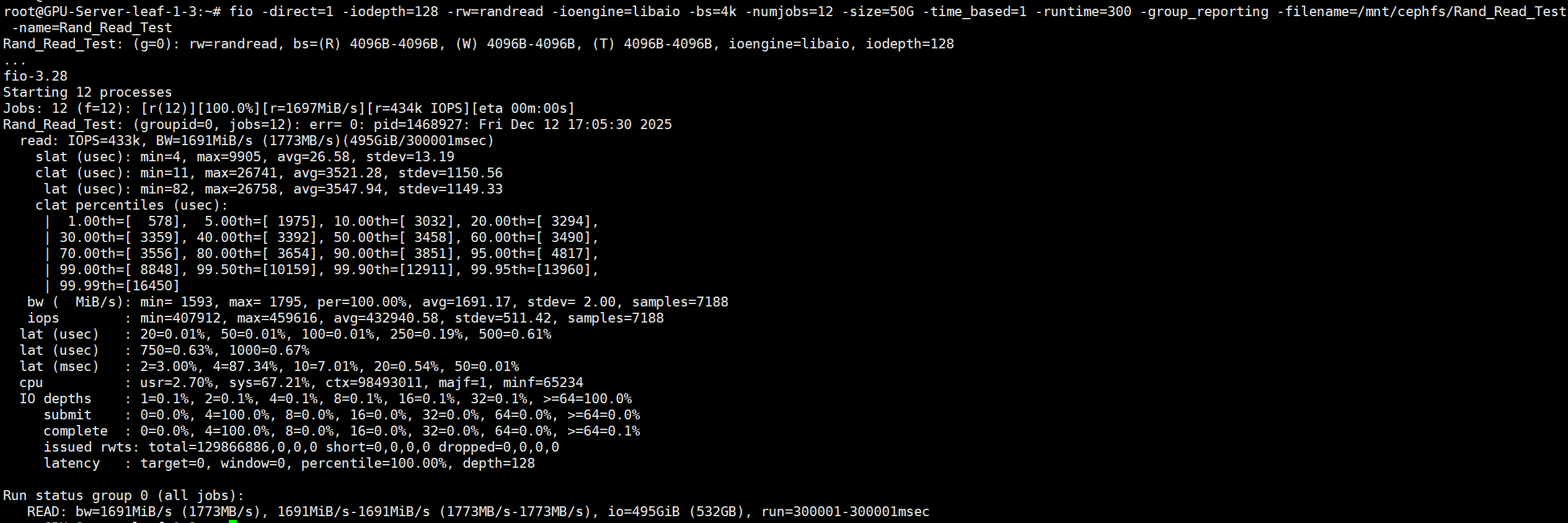
<10ms延迟 4k随机读IOPS
# numjobs需要逐步增加,找到<10ms的极限值。numjobs=12
fio -direct=1 -iodepth=128 -rw=randread -ioengine=libaio -bs=4k -numjobs=8 -size=50G -time_based=1 -runtime=300 -group_reporting -filename=/mnt/cephfs/Rand_Read_Test -name=Rand_Read_Test
IOPS 433K/s 延迟3.5ms/s
- 平均延迟 (
lat avg) 3.5ms - 延迟分布 (
99.50th) 99.5%请求<10.2ms - 平均IOPS 433K/s
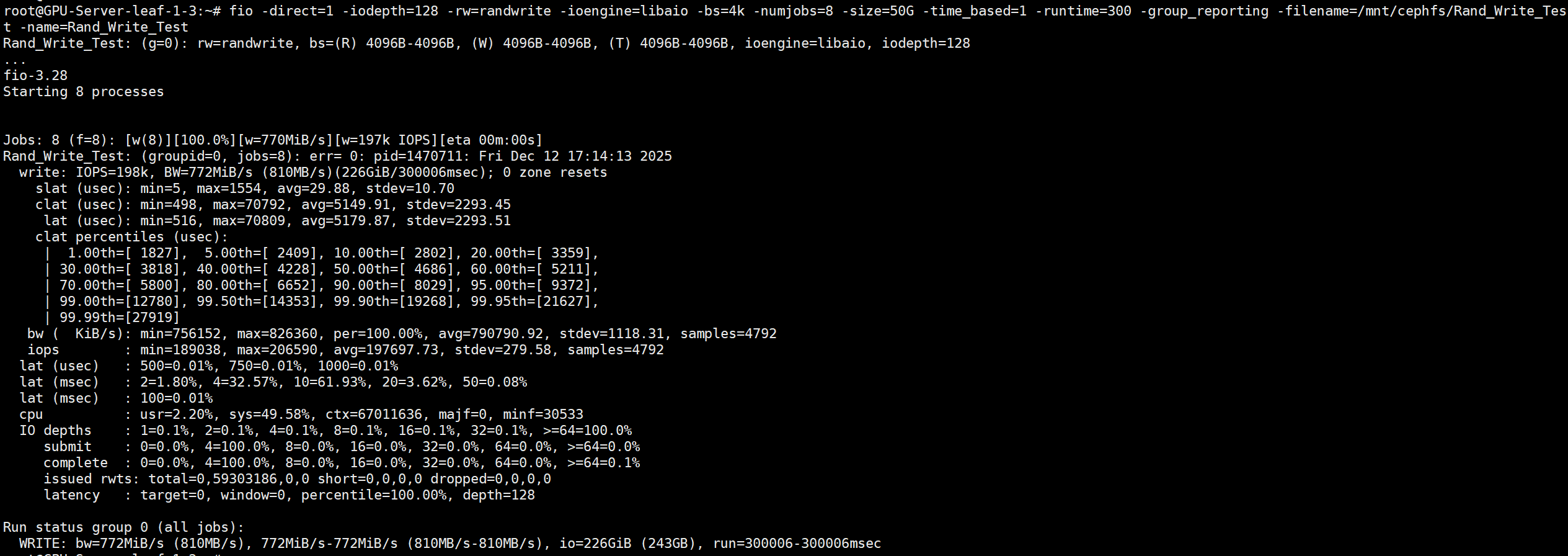
<10ms延迟 4k随机写IOPS
# numjobs需要逐步增加,找到<10ms的极限值。numjobs=8
fio -direct=1 -iodepth=128 -rw=randwrite -ioengine=libaio -bs=4k -numjobs=8 -size=50G -time_based=1 -runtime=300 -group_reporting -filename=/mnt/cephfs/Rand_Write_Test -name=Rand_Write_Test
IOPS 198K/s 延迟5.2ms/s
- 平均延迟 (
lat avg) 5.2ms - 延迟分布 (
95.00th) 95%请求<9.4ms - 平均IOPS 198K/s
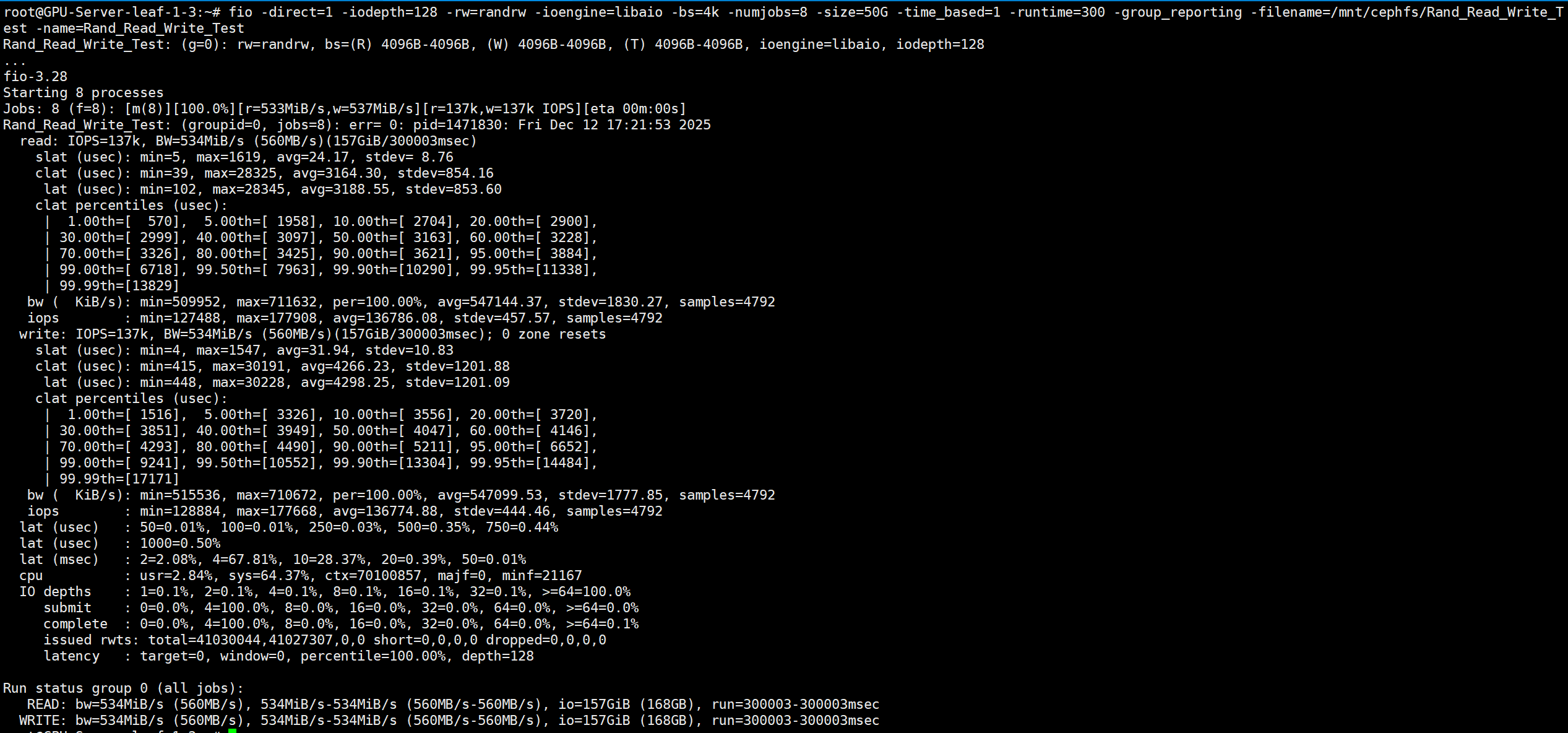
<10ms延迟 4k随机读写IOPS
# numjobs需要逐步增加,找到<10ms的极限值。numjobs=8
fio -direct=1 -iodepth=128 -rw=randrw -ioengine=libaio -bs=4k -numjobs=8 -size=50G -time_based=1 -runtime=300 -group_reporting -filename=/mnt/cephfs/Rand_Read_Write_Test -name=Rand_Read_Write_Test
读写IOPS 137K/s
- 读平均延迟 (
lat avg) 3.2ms - 写平均延迟 (
lat avg) 4.3ms - 读延迟分布 (
99.90th) 99.9%请求<10.3ms - 写延迟分布 (
99.50th) 99.5%请求<10.6ms - 平均IOPS 137K/s
五、系统稳定性评估
- 测试过程中未出现性能波动或异常中断,Ceph集群与客户端系统运行稳定。
- 各节点硬件资源(CPU、内存、网络、磁盘)利用率均衡,无单点瓶颈。
六、结论
本次压测表明,当前Ceph存储集群在搭配高性能GPU服务器时,能够充分发挥NVMe硬盘的性能潜力,在顺序读写、随机读写及高并发IOPS场景下均表现出色,且系统资源无瓶颈,满足高性能计算与AI训练等场景的存储需求。
