
390 台 H20 智算集群架构与生产验收方法论
这篇文章整理的是一个 390 台H20 智算集群的公开版落地经验。项目形态是典型的大规模训练集群:单台服务器 8 张 H20 GPU,训练侧使用 8 张 400G ConnectX-7 网卡承载 RoCEv2 算力网络,业务侧使用 200G x2 bonding 形成 400G 聚合业务网络。

一、为什么大规模 GPU 集群不是“装驱动 + 跑测试”
单机 GPU 服务器交付时,大家容易关注 nvidia-smi 是否正常、CUDA 是否能跑、单机 NCCL 是否有带宽。但到 390 台级规模,集群是否可用不再取决于单点成功,而取决于每一层都能被批量复制、批量验证、批量回滚。
在这个规模下,任何一个细节都会被放大。比如某一批网卡 RoCE 模式没有固化,可能导致双机测试偶发失败;某几个节点 PCI ACS 没有关,可能导致 GPU Direct RDMA 带宽异常;某个 Leaf 下 PFC 或 ECN 配置不一致,可能在 128 机以上才暴露成 NCCL 尾延迟。
因此,生产验收要按“分层基线”推进:
| 层级 | 验收重点 | 典型检查 |
|---|---|---|
| 硬件层 | GPU、NIC、NVSwitch、BMC、固件版本 | 设备数量、PCIe 拓扑、错误计数 |
| OS 层 | 内核、驱动、OFED、CUDA、NCCL | 模块加载、版本一致性、系统参数 |
| 网络层 | RoCEv2、MTU、PFC、ECN、DCQCN、DSCP | GID、链路、队列、CNP 标记 |
| 通信层 | 单机、双机、小规模、百台级 NCCL | AllReduce、AllToAll、busbw、错误计数 |
| 存储层 | 数据集读取、Checkpoint 写入、元数据压力 | fio 吞吐、IOPS、延迟分布 |
| 运维层 | 自动化、监控、故障定界、复跑能力 | 幂等脚本、节点清单、排障闭环 |
真正的交付目标不是“某一次跑通”,而是任何节点出现异常后,都能快速定界、隔离、恢复,并在恢复后复跑同一套验收基线。
二、集群网络平面设计
这个项目的网络可以按职责拆成三类平面。
第一类是业务管理网。它承载 SSH、调度控制、镜像拉取、运维平台、日志回传、少量数据分发等流量。项目口径中业务侧采用 200G x2 bonding,形成 400G 聚合能力。这里要特别注意,bond 的聚合速率不等于单 TCP 流一定能吃满 400G,实际还取决于 bonding 模式、交换机聚合算法、五元组分布和上层业务并发模型。
第二类是 RoCEv2 算力网络。每台 8 卡 H20 服务器配 8 张 400G 训练网卡,常见目标是尽量让 GPU 和 NIC 建立稳定、可预测的亲和关系,使 NCCL 在跨机通信时能充分利用多 HCA、多路径和 ECMP。这里的关键不是“网卡速率足够高”,而是 RoCE 的无损队列、拥塞控制、DSCP、PFC、ECN、GID、MTU 等参数必须端到端一致。
第三类是存储数据路径。训练数据读取和 Checkpoint 写入可以走独立存储网络,也可以复用高速数据网络。无论使用 CephFS、对象存储、并行文件系统,还是缓存层,存储验收都不能只看单次顺序读写带宽,还要同时看延迟分布、客户端 CPU、网卡速率、服务端 OSD 或磁盘利用率。
三、单机 8 卡服务器基线
单机基线要先回答四个问题。
第一,硬件是否完整识别。GPU 数量、NIC 数量、NVSwitch 或 PCIe 设备数量必须和 BOM 一致。对 8 卡服务器来说,不能只看 nvidia-smi 是否显示 8 张卡,还要看 PCIe BDF、GPU UUID、网卡 PCI 地址、NUMA 亲和、NVLink/NVSwitch 状态。
第二,软件栈是否一致。大规模集群最怕“少数节点版本漂移”。驱动、CUDA、NCCL、OFED、固件、BIOS 参数都要形成版本矩阵。本文项目资料中的单机 NCCL 证据图可以看到 H20-3e 设备和 NCCL 测试输出,适合公开证明机器类型和测试方法。
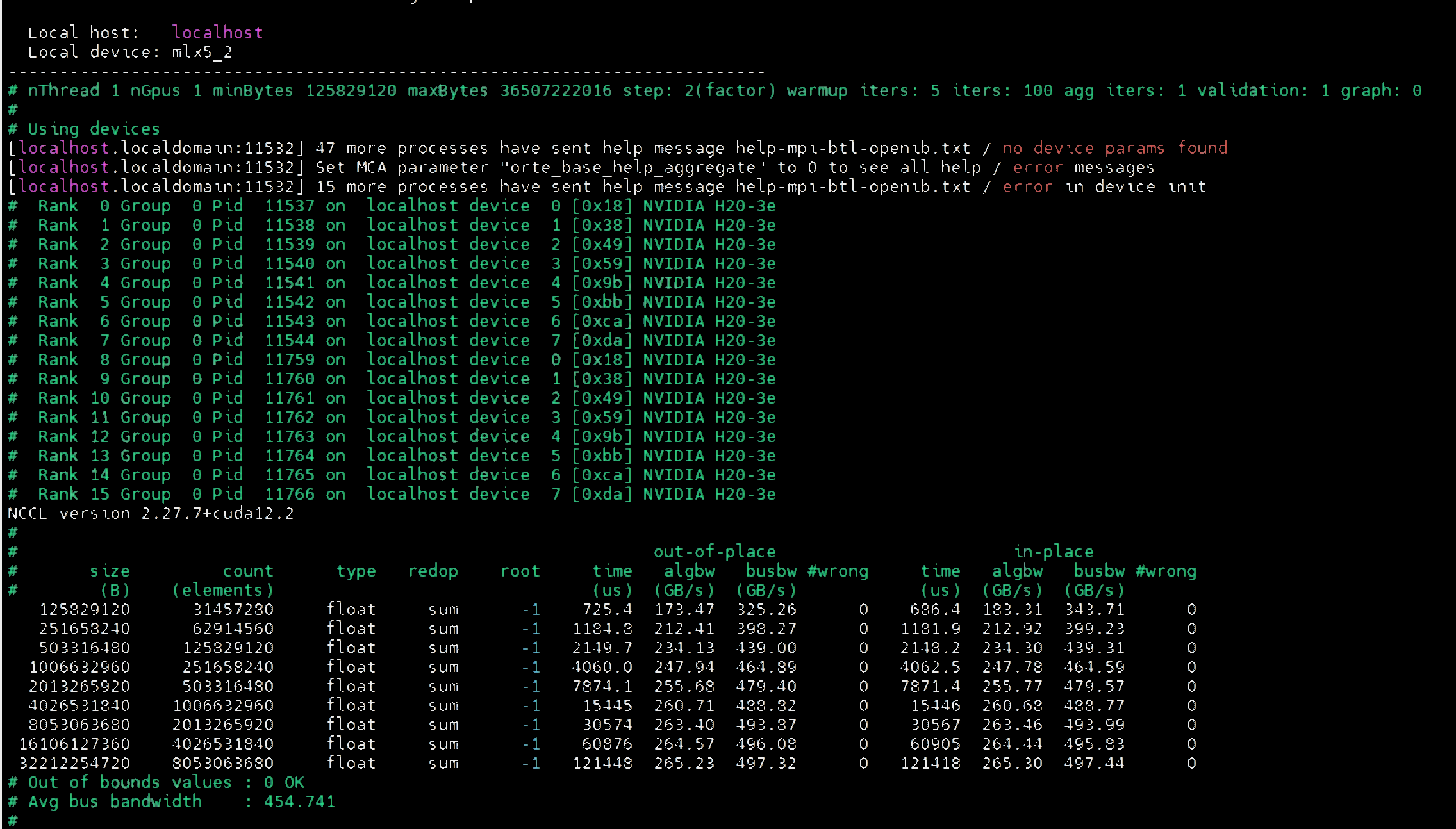
第三,GPU Direct RDMA 是否可用。H20 跨机训练的通信路径不能只停留在 TCP 或普通 RDMA,要确保 nvidia_peermem、mlx5_ib、rdma_cm 等模块加载正常,PCI ACS 不阻断点对点访问,NCCL 能正确选择 IB/RoCE 路径。
第四,单机 NCCL 是否稳定。单机 8 卡测试的价值不是替代整网测试,而是尽早排除 GPU、NVLink/NVSwitch、驱动、CUDA、NCCL 本地问题。单机不稳定时,直接上百台测试只会制造噪声。
四、从单机到整网的验收阶梯
大规模 NCCL 验收建议分阶段推进。
| 阶段 | 目标 | 为什么不能跳过 |
|---|---|---|
| 单机 8 卡 | 验证本机 GPU、驱动、NCCL、拓扑 | 排除本地硬件和软件栈问题 |
| 双机 16 卡 | 验证 RoCE、HCA、路由、GDR | 最小化跨机问题定位范围 |
| 64 机 | 验证小规模 ECMP 和队列一致性 | 能较快暴露配置批次差异 |
| 128 机 | 验证百台级稳定性和尾延迟 | 接近实际训练通信压力 |
| 256 机 | 验证大规模路径与拥塞控制 | 检查网络局部热点和慢节点 |
| 350 机以上 | 验证整网可用性 | 给生产上线提供验收依据 |
项目资料中的脱敏 NCCL 结果显示,64 机、128 机、256 机和 350 机验收批次均达到预期。这里需要强调一点:NCCL 的 busbw 不是单张网卡线速,也不是所有网卡线速简单相加,它是集合通信算法下的有效总线带宽指标。解读结果时,要结合消息大小、迭代次数、算法、协议、节点规模和网络拓扑。
五、生产交付的关键原则
第一,所有配置必须自动化。包括 RDMA 模块持久化、网卡命名、RoCE 模式、DSCP、PFC、ECN、DCQCN、ACS、NCCL 环境变量模板。手工配置可以用于排障,但不能作为集群的生产交付方式。
第二,所有自动化必须可验证。每个配置项都要有检查命令和期望输出。例如配置了 CNP DSCP,就要能批量读取对应 sysfs 值;配置了 DCQCN,就要能批量查询网卡固件参数;加载了 nvidia_peermem,就要能从模块列表和 NCCL 结果确认生效。
第三,验收结果必须可复跑。生产环境里经常会有节点替换、固件升级、网络维护、驱动升级。没有可复跑的验收模板,后续任何变更都只能靠经验判断,风险会越来越高。
第四,故障定界必须闭环。GPU 掉卡、NVSwitch 异常、Fabric Manager 启动失败、NCCL 慢节点、RoCE 丢包,都不能停留在“重启好了”。每一次恢复都要记录现象、证据、判断、动作和复测结果。
六、总结
智算集群的核心难点不是单个组件,而是硬件、网络、GPU 通信、存储和运维之间的系统协同。一个可靠的交付方案,应该具备清晰的网络分层、统一的软件栈、可自动化的 RoCE 调优、分阶段的 NCCL 验收、可复跑的测试模板,以及面向生产的故障定界闭环。
如果只能给一个建议,那就是:不要把大规模 GPU 集群交付做成一次性工程。它应该是一套可以持续验证、持续修复、持续扩容的生产系统。