
安装Ollama
下载Ollama,根据当前系统选择版本
打开cmd命令行
这是DeepSeek R1对应参数的性能需求,根据自身硬件来部署对应模型。
| 模型大小 | 显存需求(FP16推理) | 显存需求(INT8推理) | 推荐显卡 | macOS 需要的 RAM |
|---|---|---|---|---|
| 1.5B | ~3GB | ~2GB | RTX 2060/Mac M系列 | 8GB |
| 7B | ~14GB | ~10GB | RTX 3060 12GB/4070 Ti/Mac M系列 | 16GB |
| 8B | ~16GB | ~12GB | RTX 4070 /Mac M系列 | 16GB |
| 14B | ~28GB | ~20GB | RTX 4090 /A100 40G | 32GB |
| 32B | ~64GB | ~48GB | 2xRTX 4090 /A100 80G | 64GB |
# 等待下载完成
ollama run deepseek-r1:8b
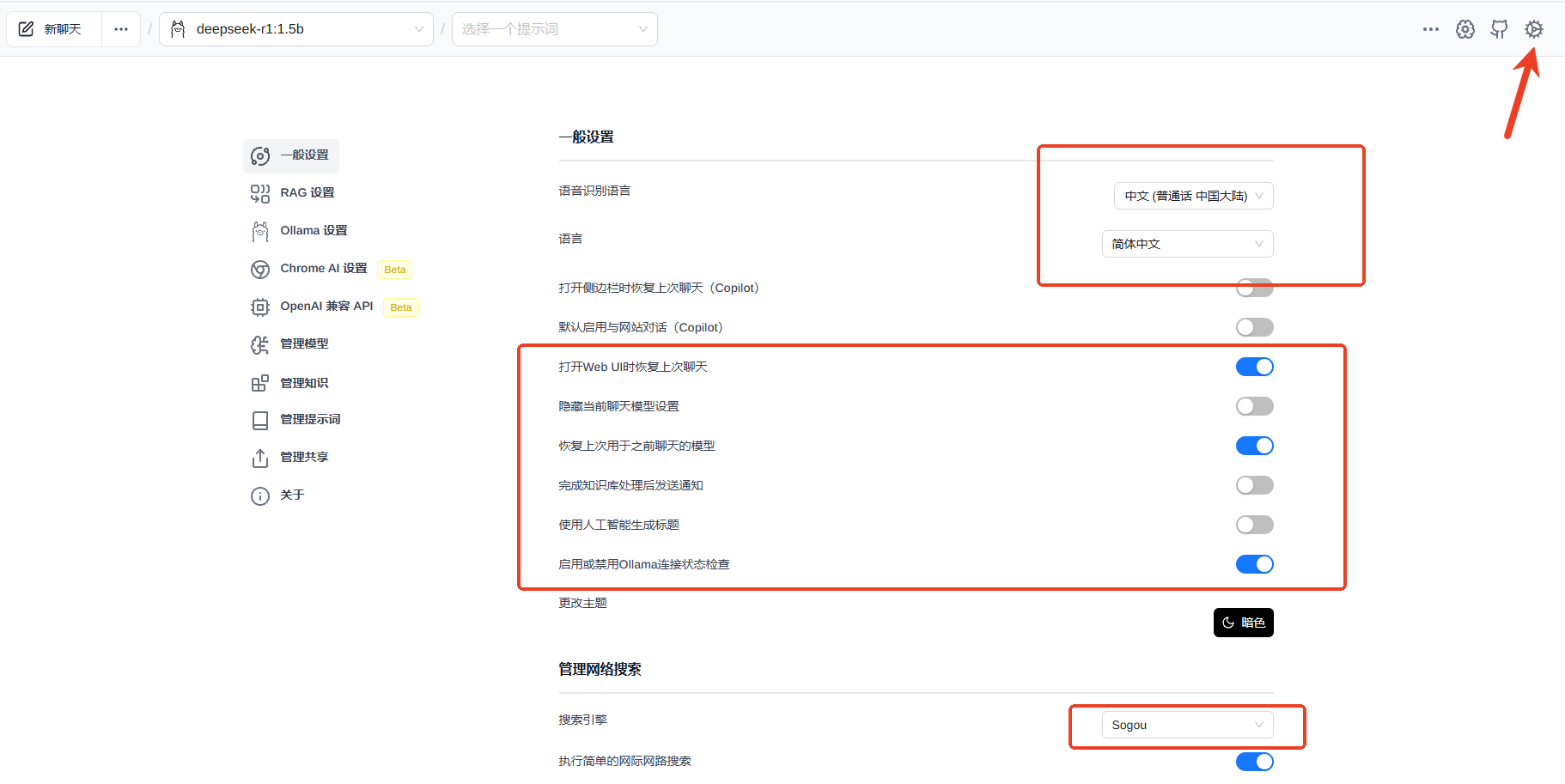
最后把插件拖进浏览器
设置浏览器插件UI使用本地模型
部署LLaMA-Factory预训练大模型、微调大模型
**官方教程:**https://llamafactory.readthedocs.io/zh-cn/latest/advanced/trainers.html
**博客命令行执行教程:**https://ai.oaido.com/index.php/2024/10/08/llama-factory使用教程/
**训练好的大模型导出,转换为gguf格式:**https://yuxiyang.netlify.app/project/llm微调/本地部署llm详解/
通过LlaMA-Factory导出的模型与Ollama所需格式有区别,**借助Llama.cpp的代码进行转换:**https://github.com/ggerganov/llama.cpp
# windows安装可视化UI,进行训练操作
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
# 完成安装后,可以通过使用 llamafactory-cli version 来快速校验安装是否成功
llamafactory-cli version
# 注意需要提前安全英伟达驱动CUDA工具,执行命令查看是否有结果
nvidia-smi
nvidia-smi --version
$ nvidia-smi
Sat Feb 8 10:45:17 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.94 Driver Version: 560.94 CUDA Version: 12.6
# 安装CUDA,注意要跟上面nvidia-smi的版本一致,比如12.2或12.6,两个要版本一致
https://developer.nvidia.com/cuda-12-6-2-download-archive?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exe_local
nvcc -V
# 从魔搭社区下载模型,设置代理
export USE_MODELSCOPE_HUB=1
# Windows 使用
set USE_MODELSCOPE_HUB=1
# 设置模型的下载目录,默认是在C盘的
set MODELSCOPE_CACHE=D:\Downloads\LLaMA-Factory\deepseek-ai\DeepSeek-R1-Distill-Qwen-32B
# 启动UI,需要进入LLaMA-Factory目录执行,否则找不到数据集
cd /d D:\Downloads\LLaMA-Factory
llamafactory-cli webui
#安装LoRA(QLoRA),版本也是根据CUDA选择
https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
pip install bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
# 安装FlashAttention-2,根据CUDA版本为12.2安装的
https://github.com/kingbri1/flash-attention/releases/download/v2.4.2/flash_attn-2.4.2+cu122torch2.1.2cxx11abiFALSE-cp311-cp311-win_amd64.whl
pip install bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
先在UI加载模型,自动下载模型
下载完成后,然后找到模型路径,在UI修改本地模型的路径,才能点开始训练
D:\Downloads\LLaMA-Factory\deepseek-ai\DeepSeek-R1-Distill-Qwen-32B\hub\deepseek-ai\DeepSeek-R1-Distill-Qwen-32B
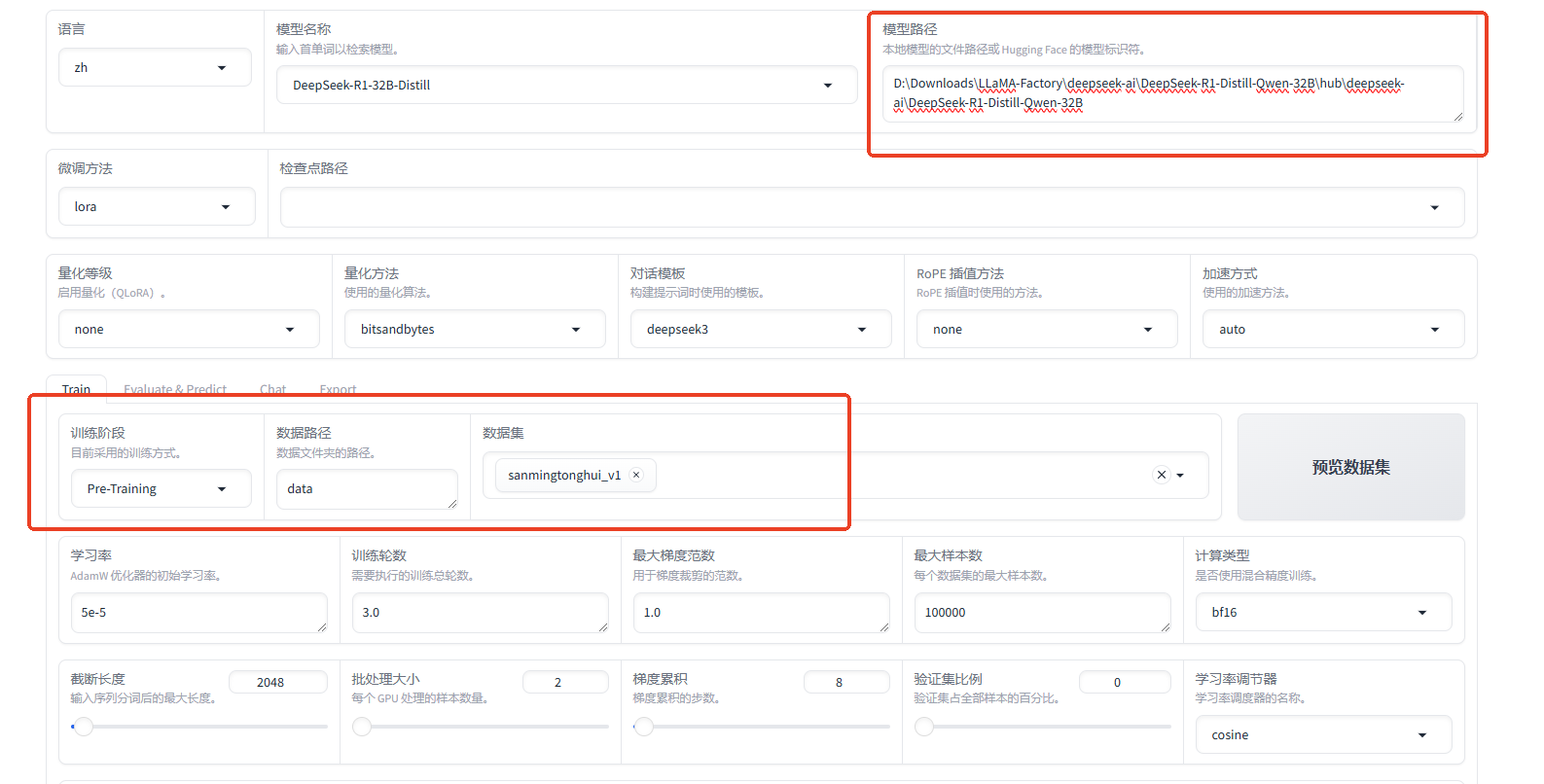
注意:至少需要2个数据集才能训练
需要修改dataset_info.json文件添加数据集名字才能识别成功
dataset_info.json
"sanmingtonghui_v1": {
"file_name": "sanmingtonghui_v1.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
"alpaca_gpt4_data_zh": {
"file_name": "alpaca_gpt4_data_zh.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
最小化训练模型的cmd命令
llamafactory-cli train ^
--stage pt ^
--do_train True ^
--model_name_or_path D:/Downloads/LLaMA-Factory/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B/hub/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B ^
--preprocessing_num_workers 1 ^
--finetuning_type lora ^
--template deepseek3 ^
--flash_attn auto ^
--dataset_dir data ^
--dataset sanmingtonghui_v1 ^
--cutoff_len 256 ^
--learning_rate 5e-05 ^
--num_train_epochs 1.0 ^
--max_samples 1000 ^
--per_device_train_batch_size 1 ^
--gradient_accumulation_steps 32 ^
--lr_scheduler_type cosine ^
--max_grad_norm 1.0 ^
--logging_steps 5 ^
--save_steps 50 ^
--warmup_steps 0 ^
--packing True ^
--report_to wandb ^
--output_dir saves/DeepSeek-R1-32B-Distill/lora/train_2025-02-08-18-43-00 ^
--bf16 True ^
--plot_loss True ^
--trust_remote_code True ^
--ddp_timeout 180000000 ^
--include_num_input_tokens_seen True ^
--optim adamw_torch ^
--lora_rank 4 ^
--lora_alpha 16 ^
--lora_dropout 0 ^
--lora_target all ^
--log_level debug
安装AnythingLLMDesktop软件,对接ollama启动的deepseek-r1模型
https://anythingllm.com/desktop
Cherry Studio搭建本地知识库
Open WebUI
如果需要投喂知识库,精准度提高,需要下载其它模型。缺点是提问非知识库相关的问题会不知道。
ollama pull nomic-embed-text
然后上传知识库
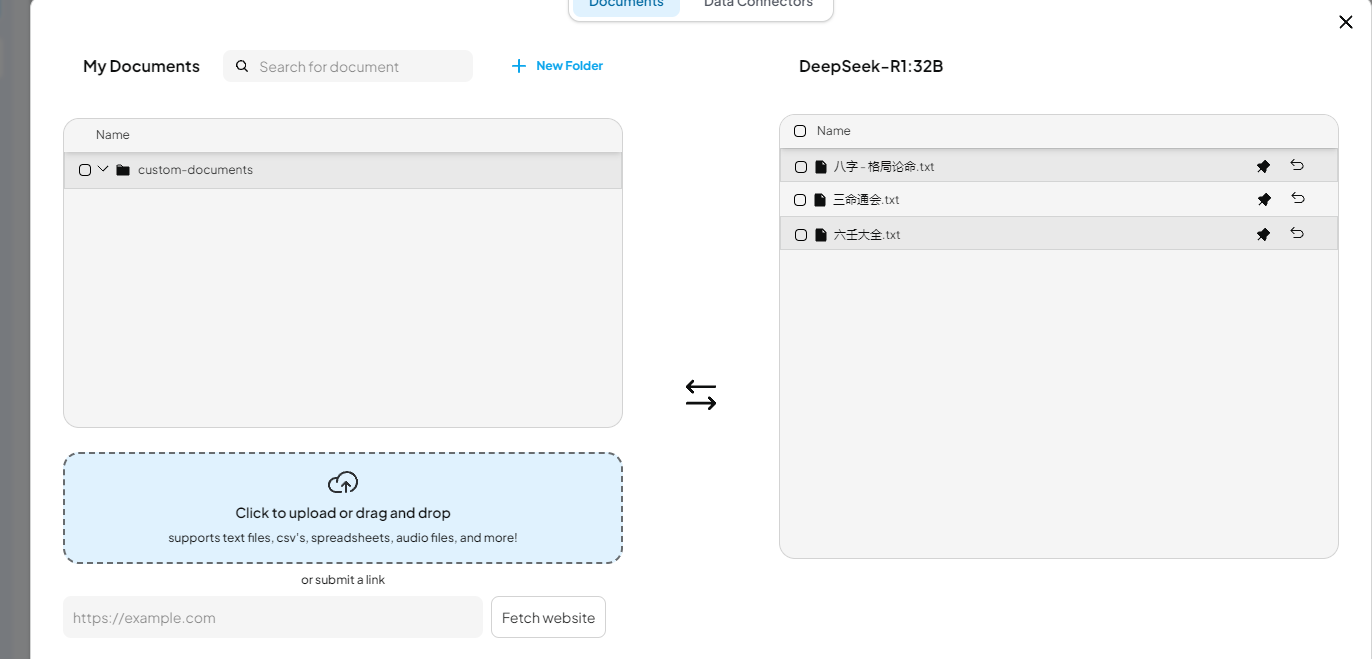
使用模型自身来投喂知识库

