记一次100T数据反编译Crush Map自定义根树触发的数据重平衡
尝粪忧心
背景:
最初部署Ceph集群的时候,因为刚入门Ceph存储且门槛较高,没有设计好架构模式,随着时间推移,集群越来越大,出现性能问题。会出现客户端资源争用导致偶发连接超时的问题。然后过程不断的优化配置参数、不断调优集群,最终还是由于hdd硬盘问题,达到性能瓶颈。然后在Ceph官网文档看到crushmap的高级玩法,就计划额外扩展3台节点,硬盘类型为全SSD,且自定义另外独立树,达到资源隔离。虽然性能会有所提升,但始终还是不及单块SSD的性能,由于op路径很长且流程繁琐,所以性能就是Ceph的硬伤。
所以使用hdd的硬盘,只适用于归档存储,如果你的场景是高吞吐量或频繁IOPS,还是头铁要用hdd硬盘,ceph不会让你失望的,就像扯到蛋一样,隐隐作痛。
操作步骤与思路:
- 设置禁止重平衡、回填、恢复等动作
- 添加新节点的osd
- 反编译crushmap,然后编辑自定义规则
- 导入新的crushmap,恢复重平衡、回填、恢复等动作
- 限制osd恢复速度,避免占用过多客户端IO
前人栽树
以上方法亲测可行,务必要在低峰期执行,且风险较大,本人比较喜欢探索冒险,所以我改了default的规则,导致原来的根树触发回填、恢复、迁移等操作,然后由于旧节点osd是hdd类型,wal和db分区在osd自身的hdd硬盘里,因为最初是想提高稳定性,不把所有鸡蛋放在同一篮子(因为要浪费1-2块SSD分区给db、wal使用),所以牺牲了这些性能。然而谁知道这里面有巨坑,因为hdd性能实在拉跨,而且db和wal还在同一块硬盘里,导致经常把hdd类型的osd打down了,然后又up,陷入了死循环,引起严重的震荡。此时这种情况一定要把down和out的时间设置尽量大一点,避免osd频繁震荡。如果out时间太短,那么超过默认的时间就会把osd剔除,会触发数据丢失的这种恢复状态,严重占用客户端的IO。
扩展节点:
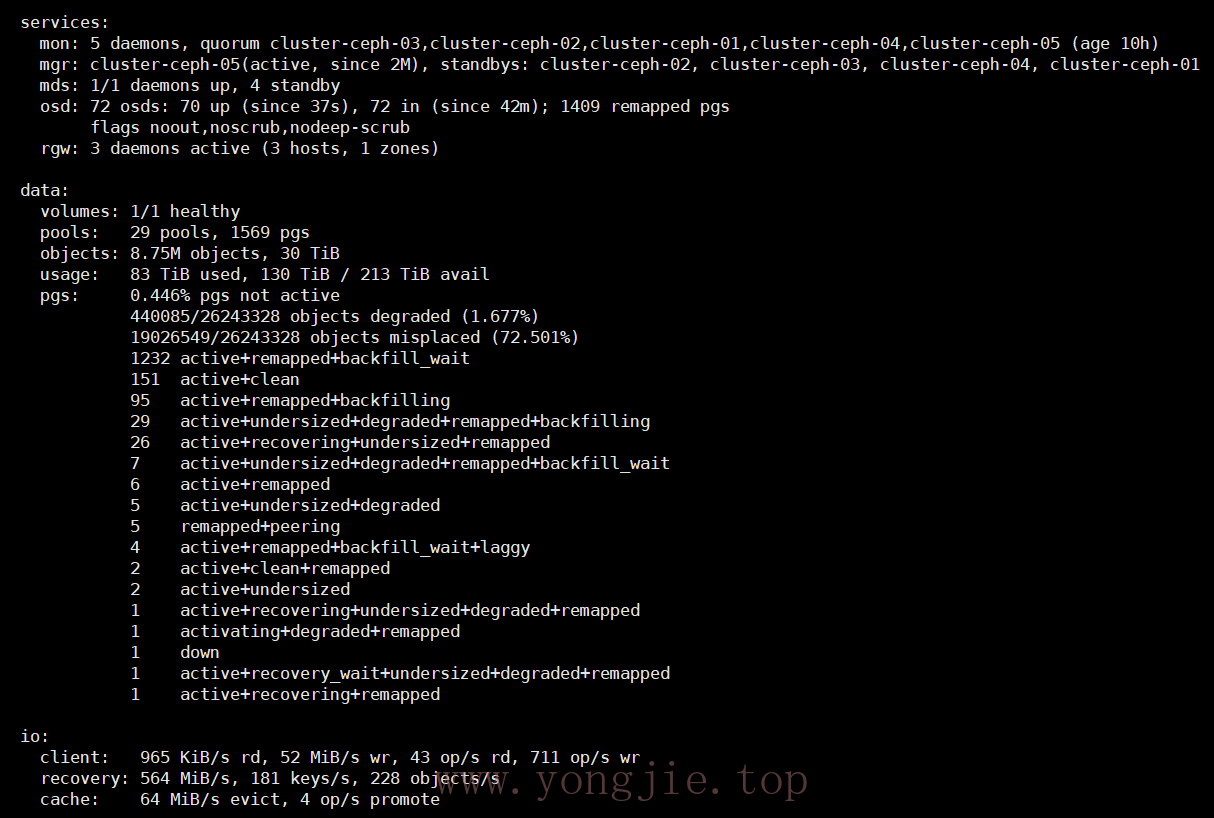
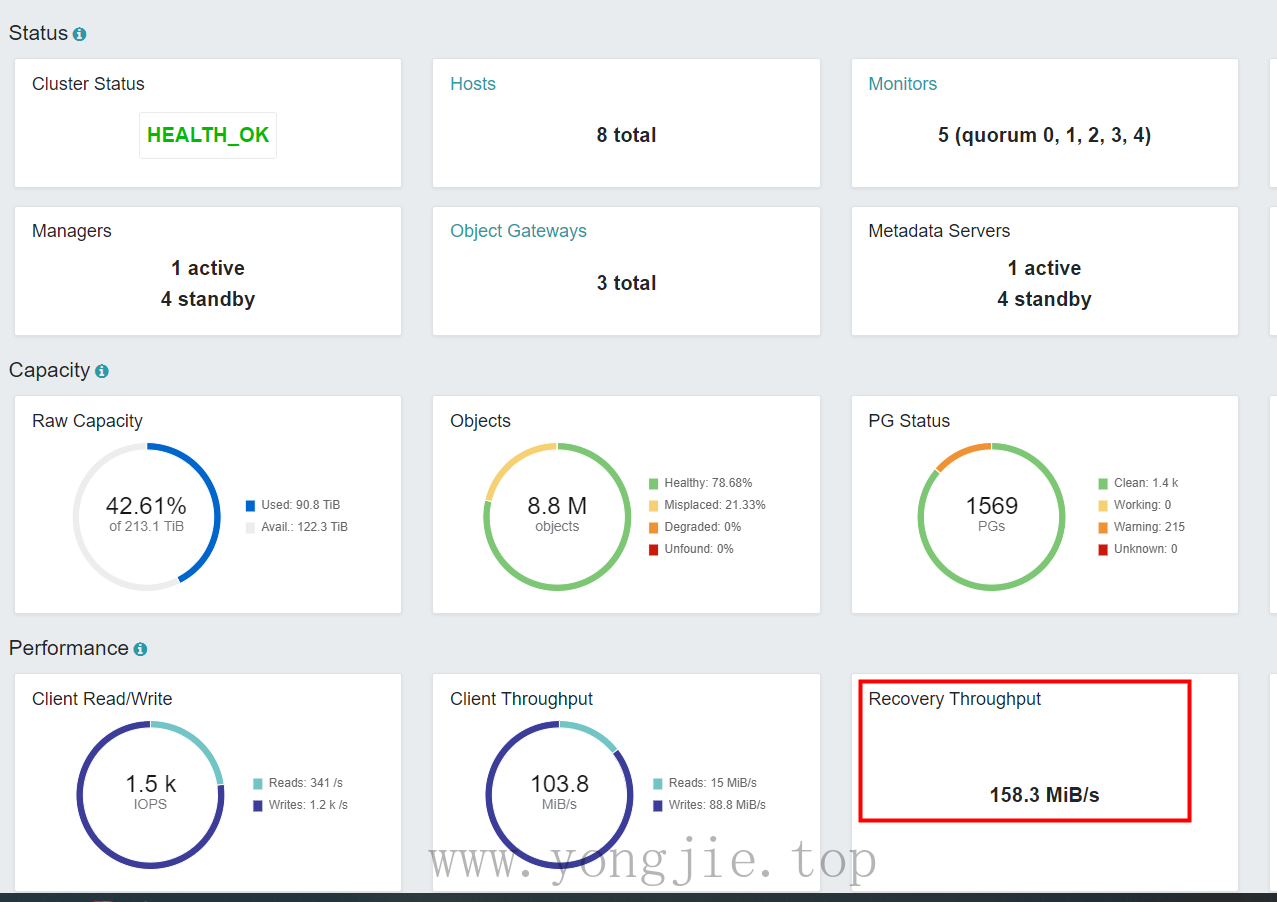
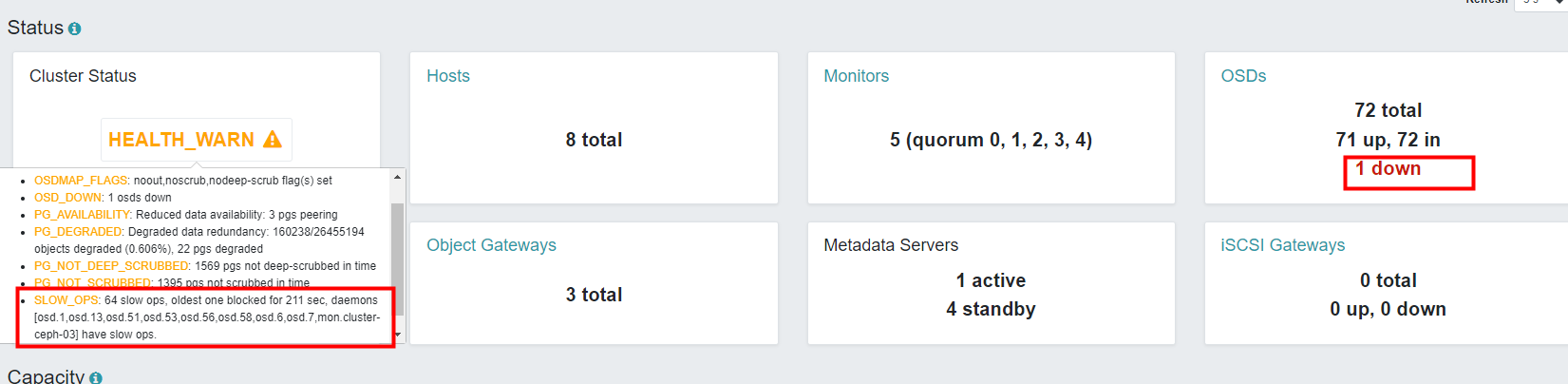
然后另外新增独立的根树,新增的3台节点不需要恢复、回填等操作,因为与旧的节点是不同的根树,资源隔离的,可以直接创建存储池绑定给客户端使用。集群旧的节点由于触发了回填、恢复、重平衡的操作,这个过程是漫长的等待,而且无法预估时间,即使限制了恢复速度,还是会影响客户端IO的。但恢复速度越慢,对于客户端是越友好,恢复速度越快,会导致客户端大面积连接超时、拒绝,读写缓慢甚至内核hang死(注意:这里说的恢复指的是数据回填、重平衡,并不是数据丢失的恢复。因为数据丢失的恢复还得看故障域是否host类型,否则2个副本在同一台节点,丢失了2个副本就无法恢复),最终花了3天时间才完全恢复完成。下图就是集群恢复过程和状态,偶尔会有慢ops,IO阻塞,严重的情况osd心跳超时就会设置为down。部分截图,心领神会:

反编译Crush Map重点!
如果OSD的容量规格统一,节点数量3台以上,OSD数量9块以上,则使用host故障域,如果是osd故障域,有些幸运儿会有两个副本存在同一台节点,此时故障1台节点,很有可能会导致部分PG Unkown需要恢复数据,此时就会影响到虚拟机的读写性能,甚至客户端IO路径中断或暂时无法写入等等异常问题。如果无法恢复PG,那么只能弃车保帅,删除损坏的PG,然后提桶进厂——成格。。。

注意:务必要硬盘的容量规格统一、节点、osd数量足够多的情况下,才能用host分布。如果不统一硬盘容量,那么会导致部分osd容量使用近满的情况,因为是按照host分布的,就很难去平衡每个osd的数据了,而且单独调整osd权重,也会一直限于循环重平衡当中,重平衡会大量占用IO,客户端自然就会影响性能
改chushmap规则之前,一定要备份原文件,定义失败可以回滚!生产环境,数据量大的场景,建议别搞,否则真的成格了。
CrushMap举例详解:
#查看crushmap信息
ceph osd getcrushmap -o crushmap
crushtool -d crushmap -o crushmap.txt
cat crushmap.txt
#一定要备份原文件,定义失败可以回滚!!!
cp crushmap.txt crushmap.backup
#开始自定义crushmap
vim crushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 11 osd.11 class ssd
device 12 osd.12 class ssd
device 13 osd.13 class hdd
device 14 osd.14 class hdd
device 15 osd.15 class hdd
device 16 osd.16 class hdd
device 17 osd.17 class hdd
device 18 osd.18 class hdd
device 19 osd.19 class hdd
device 20 osd.20 class hdd
device 24 osd.24 class ssd
device 25 osd.25 class ssd
device 26 osd.26 class hdd
device 27 osd.27 class hdd
device 28 osd.28 class hdd
device 29 osd.29 class hdd
device 30 osd.30 class hdd
device 31 osd.31 class hdd
device 32 osd.32 class hdd
device 33 osd.33 class hdd
device 37 osd.37 class ssd
device 38 osd.38 class ssd
device 39 osd.39 class hdd
device 40 osd.40 class hdd
device 41 osd.41 class hdd
device 42 osd.42 class hdd
device 43 osd.43 class hdd
device 44 osd.44 class hdd
device 45 osd.45 class hdd
device 46 osd.46 class hdd
device 47 osd.47 class hdd
device 48 osd.48 class hdd
device 49 osd.49 class hdd
device 50 osd.50 class ssd
device 51 osd.51 class ssd
device 52 osd.52 class hdd
device 53 osd.53 class hdd
device 54 osd.54 class hdd
device 55 osd.55 class hdd
device 56 osd.56 class hdd
device 57 osd.57 class hdd
device 58 osd.58 class hdd
device 59 osd.59 class hdd
device 60 osd.60 class hdd
device 61 osd.61 class hdd
device 62 osd.62 class hdd
device 63 osd.63 class ssd
device 64 osd.64 class ssd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host r1830-ceph { #旧OSD-hdd类型
id -3 # do not change unnecessarily
id -5 class hdd # do not change unnecessarily
# weight 40.000
alg straw2
hash 0 # rjenkins1
item osd.0 weight 5.000
item osd.1 weight 5.000
item osd.2 weight 5.000
item osd.3 weight 5.000
item osd.4 weight 5.000
item osd.5 weight 5.000
item osd.6 weight 5.000
item osd.7 weight 5.000
}
host r1827-ceph { #旧OSD-hdd类型
id -7 # do not change unnecessarily
id -9 class hdd # do not change unnecessarily
# weight 40.000
alg straw2
hash 0 # rjenkins1
item osd.13 weight 5.000
item osd.14 weight 5.000
item osd.15 weight 5.000
item osd.16 weight 5.000
item osd.17 weight 5.000
item osd.18 weight 5.000
item osd.19 weight 5.000
item osd.20 weight 5.000
}
host r1824-ceph { #旧OSD-hdd类型
id -10 # do not change unnecessarily
id -11 class hdd # do not change unnecessarily
# weight 40.000
alg straw2
hash 0 # rjenkins1
item osd.26 weight 5.000
item osd.27 weight 5.000
item osd.28 weight 5.000
item osd.29 weight 5.000
item osd.30 weight 5.000
item osd.31 weight 5.000
item osd.32 weight 5.000
item osd.33 weight 5.000
}
host r1821-ceph { #旧OSD-hdd类型
id -13 # do not change unnecessarily
id -12 class hdd # do not change unnecessarily
# weight 55.000
alg straw2
hash 0 # rjenkins1
item osd.39 weight 5.000
item osd.40 weight 5.000
item osd.41 weight 5.000
item osd.42 weight 5.000
item osd.43 weight 5.000
item osd.44 weight 5.000
item osd.45 weight 5.000
item osd.46 weight 5.000
item osd.47 weight 5.000
item osd.48 weight 5.000
item osd.49 weight 5.000
}
host r1818-ceph { #旧OSD-hdd类型
id -16 # do not change unnecessarily
id -20 class hdd # do not change unnecessarily
# weight 55.000
alg straw2
hash 0 # rjenkins1
item osd.52 weight 5.000
item osd.53 weight 5.000
item osd.54 weight 5.000
item osd.55 weight 5.000
item osd.56 weight 5.000
item osd.57 weight 5.000
item osd.58 weight 5.000
item osd.59 weight 5.000
item osd.60 weight 5.000
item osd.61 weight 5.000
item osd.62 weight 5.000
}
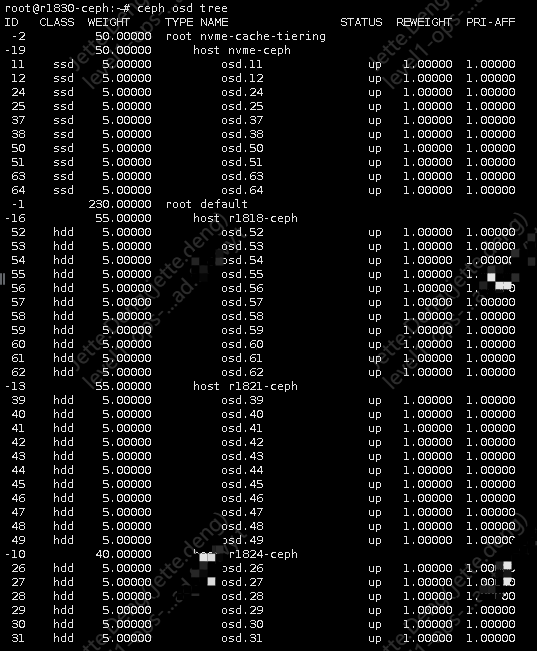
root default { #默认的树
id -1 # do not change unnecessarily
id -22 class hdd # do not change unnecessarily
id -30 class ssd # do not change unnecessarily
# weight 230.000
alg straw2
hash 0 # rjenkins1
item r1830-ceph weight 40.000
item r1827-ceph weight 40.000
item r1824-ceph weight 40.000
item r1821-ceph weight 55.000
item r1818-ceph weight 55.000
}
host nvme-ceph { #新增虚拟host-全ssd类型OSD
id -19 # do not change unnecessarily
id -21 class ssd # do not change unnecessarily
# weight 50.000
alg straw2
hash 0 # rjenkins1
item osd.24 weight 5.000
item osd.25 weight 5.000
item osd.37 weight 5.000
item osd.38 weight 5.000
item osd.50 weight 5.000
item osd.51 weight 5.000
item osd.63 weight 5.000
item osd.64 weight 5.000
item osd.11 weight 5.000
item osd.12 weight 5.000
}
root nvme-cache-tiering { #这是新增的树,转发给上面的host
id -2 # do not change unnecessarily
id -18 class hdd # do not change unnecessarily
id -4 class ssd # do not change unnecessarily
# weight 50.000
alg straw2
hash 0 # rjenkins1
item nvme-ceph weight 50.000
}
# rules
rule replicated_rule { #默认的rule规则,路由到默认的host-hdd类型
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule ssd_rule { #新增的rule规则,路由到新增的树再转发到host-ssd类型
id 1
type replicated
min_size 1
max_size 10
step take nvme-cache-tiering
step chooseleaf firstn 0 type osd
step emit
}
# end crush map
#注意rules的类型一定要是host的故障域,缓存层的也必须是host,否则容易导致3个副本都在同一台节点上,当这个节点故障就会丢PG无法恢复!
#如果是缓存层的nvme太少,那么就需要把每台节点的nvme另外分成独立的host!
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule ssd_rule { #给缓存层使用的rule,不需要定义class hdd或ssd,因为这个nvme-cache-tiering是新定义的树,然后再绑定了名为nvme-ceph的host
id 1
type replicated
min_size 1
max_size 10
step take nvme-cache-tiering
step chooseleaf firstn 0 type host
step emit
}
#重新编译crushmap并导入进去
crushtool -c crushmap.txt -o crushmap.new
ceph osd setcrushmap -i crushmap.new
效果展示: