剖析业务IO模型
了解业务基本存储模型:
-
最高并发多少,最高读写带宽需求。
-
- 并发多少决定了在知道单个RGW最大并发数上限的前提下你需要用多少个RGW的实例去支撑这些并发。
- 最高读写带宽决定了你要用多少OSD去支撑这么大的读写带宽,同时还要考虑endpoint入口处的带宽是否满足这个需求。
-
客户端分布在内外还是外网。
-
- 客户端主要分布在外网,意味着在公网这种复杂的网络环境下,数据读写会受到一些不可控因素的影响,所以现在做对象存储的公有云都不敢把自己的带宽和延时和并发数告诉你。
- 客户端分布在内外,意味着应该尽量减少endpoint入口与客户端的路由跳数,保障其带宽。
-
读写比率,平均request大小。
-
-
如果读取比较高,比如CDN场景,可以考虑在endpoint入口处增加读缓存组件。
-
如果写入比率较高,比如数据备份,则要考虑控制好入口带宽,避免出现高峰期多个业务抢占写入带宽,影响整体服务质量。
-
平均request大小,决定了整个对象存储服务,是针对大文件还是小文件做性能优化。
老司机经验:很多时候我们并不清楚业务的具体IO模型组成,这个时候可以考虑小规模接入业务,并将前端endpoint的访问日志(比如前端使用nginx)接入到ELK一类的日志分析系统,借助ELK可以很方便分析出业务IO模型。
-
兵马未动,粮草先行
所有的业务构想最终都需要构建在基础硬件平台上,前期业务规模小,可能对硬件选型不太重视,但是随着业务不断增长,选择靠谱稳定且性价比高的硬件平台会变得尤为重要。
小规模下的硬件资源经验
小规模一般指集群机器数量在20台以内或者osd数量在200个以内的场景,这个阶段为了省钱,MON节点可以考虑使用虚拟机,但是必须满足2个条件:
* MON数量在3台以上,最多5台,多了浪费钱,并且CPU和内存控制在2核4G以上。
* MON一定要分布在不同物理机上,同时做好NTP同步。
至于OSD节点,满足以下条件:
* OSD 打死也不要上虚拟机,日常换盘和故障排错麻烦,而且因为虚机IO栈又多了一层,数据安全性差很多。
* 需要考虑到网络的带宽限制,如果是千兆,只能做bond,尽量满足每个OSD有40~60M/s的网络带宽,从经验来看网络能够上万兆就不要搞千兆bond,后续的网络升级需要停OSD也是很大的坑。
* 每个OSD再抠也要做到最少1核2G的物理资源,不然出点问题座数据恢复的时候内存就会hold不住。
* 如果你不计较性能,没有SSD做journal,那就算了吧。
* index pool 能用SSD最好,没有那也没办法了。
RGW节点就轻松很多:
* RGW 可以考虑用虚机,甚至docker,因为这个服务我们通过多开可以提高整体服务的高可用和并发能力。
* 每个RGW 的资源最少2核4G,因为每个request请求在没有写入rados之前,都是缓存在内存里面。
* RGW服务节点2个左右差不多了,前端可以接入nginx做反向代理提高并发。
* 不调优的情况下civetweb并发要比fastcgi差好多。
中等规模下的硬件资源经验
中等规模一般指集群机器数量在20~40台以内或者osd数量在400个以内的场景,这个阶段基本上业务已经初具规模,MON节点不太适用虚拟机方案,同时还要注意一些事项:
* MON数量在3台以上,最多5台,并且CPU和内存控制在4核8G以上,有条件的话把MON的metadata存储在SSD上面。因为当集群上了一定规模以后,Mon上面的LevelDB会有性能瓶颈,特别是做数据压缩的时候。
* MON一定要分布在不同物理机上,有条件的话做到跨多个机柜部署,但是注意不要跨多个IP网段,如果网段之间网络波动,容易触发Mon频繁选举,当然选举有参数可以调。
OSD节点,满足以下条件:
* OSD 要考虑做好crushmap的故障域隔离,能用3副本,绝对不要去省钱搞2副本,后期磁盘批量到达寿命以后,这是很大的隐患。
* 每个物理节点的OSD磁盘数量不宜过多,并且单盘的容量不宜过大,你搞个8T的SATA盘,如果单盘已用量到了80%以上坏个盘,那么整个数据回填的时长绝对是漫长的等待,当然你可以控制backfill的并发数,但是对业务有影响,自己做好权衡。
* 每个OSD 最好还是有SSD journal保驾护航,到了这个规模再省下SSD的钱已经没必要了。
* index pool一定要上SSD,在性能方面这将是质的飞跃。
RGW节点就轻松很多:
* RGW 仍然可以考虑用虚机,甚至docker。
* 前端入口要接入负载均衡方案,比如LVS或者用nginx反代理。高可用和负载均衡是必选项。
* 根据SSD数量和故障域设计控制好rgw_override_bucket_index_max_shards 的数量,调优bucket的index性能。
* RGW 服务可以考虑在每个OSD上面部署一个,但是要保障对应节点的CPU和内存充足。
大中型规模下的硬件资源经验
大中型规模一般指集群机器数量在50台以内或者osd数量在500个以内的场景,这个阶段基本上业务已经达到一定规模,MON节点一定不要用虚机,同时还要注意一些事项:
* MON数量在3台以上,最多5台,上SSD。
* MON一定要分布在不同物理机上,一定要跨多个机柜部署,但是注意不要跨IP网段,用万兆互联最好。
* 每个MON保障有8核心16G内存基本上足够了。
OSD节点,满足以下条件:
* OSD 一定要提前设计好crushmap的故障域隔离,推荐3副本,至于EC方案,得看你有没有能力去解决服务器批量掉电下的EC数据恢复问题。
* OSD 硬盘一定要统一配置,不要搞4T和8T混合,这样weight控制会很麻烦,而且一定要做好每个osd的pg分布调优,避免性能压力与容量分布不均匀的情况。
* SSD journal 和 SSD index pool是必须的。
RGW节点就轻松很多:
* RGW 还是老老实实用物理机,到了这个规模,今天省的钱哪天就得哭着全交学费了。
* 前端负载均衡方案,可以做一层优化,比如提升前端带宽和并发能力,增加读缓存,甚至上dpdk。
* 使用civetweb 替代fastcgi,能够极大提升部署效率,如果结合docker可以做到快速的并发能力弹性伸缩。
* RGW可以集中部署在单独的几个物理节点,也可以考虑沿用和OSD混布方案。
凡事预则立,不预则废。
硬盘有价数据无价,对与数据打交道的存储系统务必多保持几分敬畏之心。一些高危操作,一定要慎重,不要在测试环境下养成动不动就重启删数据的习惯,上线以后可能一个习惯性动作会让你终身难忘。另外上线前一定要做好各种测试,不然等到线上出了问题再去临时抱佛脚可能已经回天乏术。对于测试下面几点是必须要做到的.
- 故障演练与恢复:使用Cosbench进行读写操作的同时模拟各种拔盘,断网,机柜断电等,以此来考验你的crushmap故障域设计能力和运维人员基本水平,过不了这道坎,系统上线以后运维人员只能自求多福。
- 性能压测一定要准备好独立的客户端机器,尽量不要混布客户端和服务端,同时所有压测产生的网络流量最好做网络隔离,不要影响线上环境。
- NTP服务的重要性确实值得我单独拿出来讲,务必做好所有节点的时钟检查再上线,那些增加mon_clock_drift_allowed延迟的方法纯属掩耳盗铃,最后要提醒大家一句,所有涉及到硬件更新维修(比如停机换主板和内存、CPU、RAID卡),务必先检查时钟正确再恢复业务,不然够你喝一壶。
- 功能覆盖测试就看你QA的功底了,说实话无论是官方用例还是Cosbench都很难达到你的预期,这一块测试用例还是自己来吧,有条件的各种语言的SDK都备上一套,没准哪天就踩坑了。上线之务必理出一个API兼容列表,避免后期临时抱佛脚再去验证接口可用性。
运筹帷幄之中,决胜千里之外

熬到系统上线以后,怎么让运维工作省心省力又是一门很大的学问。聪明的运维,七分靠工具,三分靠经验。面对五花八门的运维工具,还去傻乎乎的写脚本造轮子,显然是不可取,何况规模大了你单纯用脚本根本管不过来,后续人员交替,脚本化管理的成本也会越来越高,因此需要一个适合中小型运维团队的运维构架方案,如下图
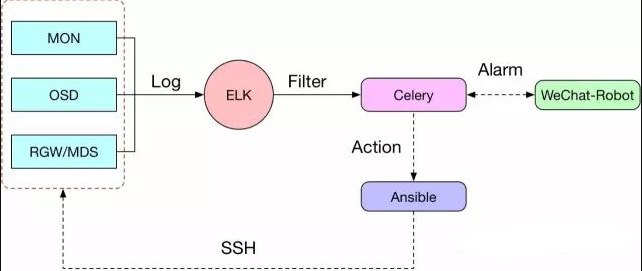
部署工具
推荐使用ansible,ansible和ceph一样被RedHat收购,同时ansible也是ceph官方主推的部署工具,SSH免代理和Ceph-deploy基本类似,但是ansible更加偏向工程实践,ceph-deploy小规模用用可以,往正规化方向还是用ansible靠谱。
日志采集与管理
首推ELK,ELK的基本功能就不介绍了,开源日志管理首推方案,把MON/OSD/RGW/MDS的日志往ELK里面一丢,接下来就是看你好好积累Ceph的运维经验了,熟悉Ceph日志,同时不断完善各种异常和告警触发条件,把日常磁盘、RAID卡等常见硬件故障日志也综合起来,基本上通过日志就可以快速诊断出OSD磁盘故障,再也不用傻乎乎的挂了OSD还不知道怎么回事,只要通知机房给你换盘就好。
异步任务调度
为什么要有异步任务调度这个东西,因为前端ELK虽然诊断分析出故障原因,最终故障还需要有人去登陆到具体的机器进行处理,引入Celery这个分布式任务调度中间件以后,运维人员把相应的故障处理操作封装成ansible playbook,比如ELK发现磁盘故障,调用运维人员的playbook去把对应的磁盘out掉,然后umount,使用megacli一类的工具点亮磁盘故障灯,最后一封邮件告知XX机房XX柜的IP为XX的机器需要更换硬盘,剩下就是等机房换完盘恢复数据了。
消息通知
微信一类的通信工具大大方便了内部人员的沟通,特别是当你不上班的时候,通过操作机器人去触发ansible playbook脚本处理故障,这种感觉才让你感觉到运维真正的酸爽!机房换完盘,把操作完毕的消息发给微信机器人,机器人会建立一个OSD恢复任务,同时发送对应的执行请求给运维人员,运维只需向机器人确认操作,剩下的事情就是让机器人随时把恢复进展以消息方式告知你就行了。一边撩妹一边处理故障绝对不是奢望。
最后附上本文推荐的工具介绍:
https://github.com/ceph/ceph-ansible
https://www.elastic.co/cn/products
http://docs.celeryproject.org/en/latest/index.html
http://wxpy.readthedocs.io/zh/latest/index.html
http://ansible-tran.readthedocs.io/en/latest/