prometheus-operator自动发现
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/heads/release-0.8.zip
mkdir -p serviceMonitor prometheus adapter node-exporter kube-state-metrics grafana alertmanager operator other
mv manifests/prometheus-adapter-* adapter/
mv manifests/alertmanager-* alertmanager/
mv manifests/grafana-* grafana/
mv manifests/kube-state-metrics-* kube-state-metrics/
mv manifests/node-exporter-* node-exporter/
mv manifests/prometheus-operator-* operator/
mv manifests/prometheus-* prometheus/
mv alertmanager/alertmanager-serviceMonitor.yaml serviceMonitor/
mv grafana/grafana-serviceMonitor.yaml serviceMonitor/
mv kube-state-metrics/kube-state-metrics-serviceMonitor.yaml serviceMonitor/
mv node-exporter/node-exporter-serviceMonitor.yaml serviceMonitor/
mv adapter/prometheus-adapter-serviceMonitor.yaml serviceMonitor/
mv operator/prometheus-operator-serviceMonitor.yaml serviceMonitor/
mv prometheus/prometheus-serviceMonitor.yaml serviceMonitor/
mv manifests/kube-prometheus-prometheusRule.yaml prometheus/
mv manifests/kubernetes-serviceMonitor* serviceMonitor/
mv manifests/kubernetes-prometheusRule.yaml prometheus/
mv operator/prometheus-operator-prometheusRule.yaml prometheus/
mv manifests/setup/* operator/
组件说明:
MetricServer:是 kubernetes 集群资源使用情况的聚合器,收集数据给 kubernetes 集群内使用,如 kubectl,hpa,scheduler 等。
PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
NodeExporter:用于各 node 的关键度量指标状态数据。
KubeStateMetrics:收集 kubernetes 集群内资源对象数 据,制定告警规则。
Prometheus:采用 pull 方式收集 apiserver,scheduler,controller-manager,kubelet 组件数 据,通过 http 协议传输。
Grafana:是可视化数据统计和监控平台。
修改nfs-provisioner挂载路径
修改service-monitor的节点IP地址
cd prometheus
ls |xargs grep 192
部署顺序:
operator alertmanager node-export kube-state-metrics grafana prometheus service-monitor
注意:
必须先部署operator,否则Prometheus无法创建。
metrics-server仅提供Node和Pod的CPU和内存使用情况。
Prometheus Adapter可支持任意Prometheus采集到的指标。
Adapter 暂时不需要部署,HPA根据CPU和内存指标暂时够用
kubectl create ns monitoring
kubectl apply -n monitoring -f nfs/
创建新的 secret additional-configs 从文件 prometheus-additional.yaml
kubectl delete secret generic additional-configs -n monitoring
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
kubectl -n monitoring create secret generic etcd-certs \
--from-file=/etc/etcd/ssl/ca.pem \
--from-file=/etc/etcd/ssl/server-key.pem \
--from-file=/etc/etcd/ssl/server.pem
kubectl create -f operator node-exporter/ -f kube-state-metrics/ -f alertmanager/ -f grafana/ -f serviceMonitor/ -f prometheus-alert
kubectl create -f prometheus --validate=false
然后promethes-deployment文件也需要修改class store名字,调用存储类。否则无法创建pod,报错提示创建pvc找不到class store
additional-configs文件里必须要格式正确,否则promethes无法被创建起来,甚至连pod都看不见。
#注意,添加监控项,需要在额外的secret配置文件加上job_name。
prometheus的原生配置文件是以secret方式,然后gzip压缩。
查看prometheus原生的gz压缩secret
kubectl get secret -n monitoring prometheus-k8s -o json | jq -r '.data."prometheus.yaml.gz"' | base64 -d | gzip -d
导出成yaml
kubectl get secret -n monitoring prometheus-k8s -o json | jq -r '.data."prometheus.yaml.gz"' | base64 -d | gzip -d > prometheus.yaml
压缩方法:
gzip prometheus.yaml
base64 prometheus.yaml.gz -w 0
去prometheus搜索监控项是否添加上来
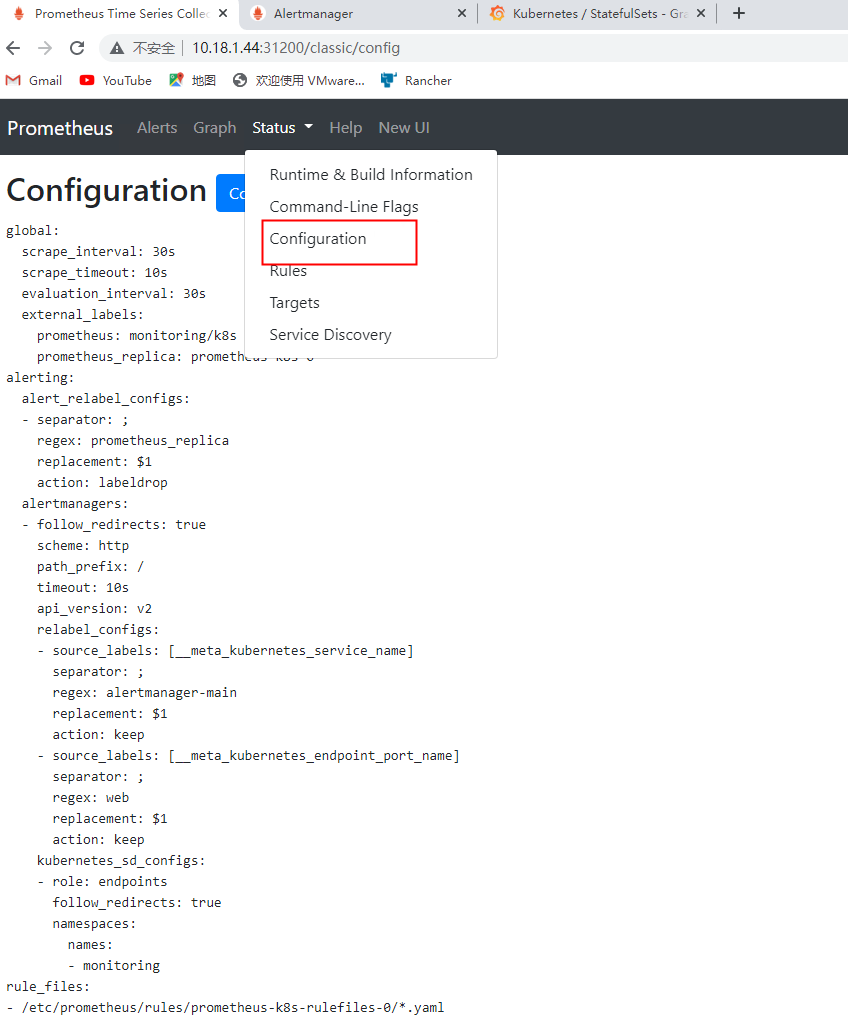
下面这些都是额外添加的
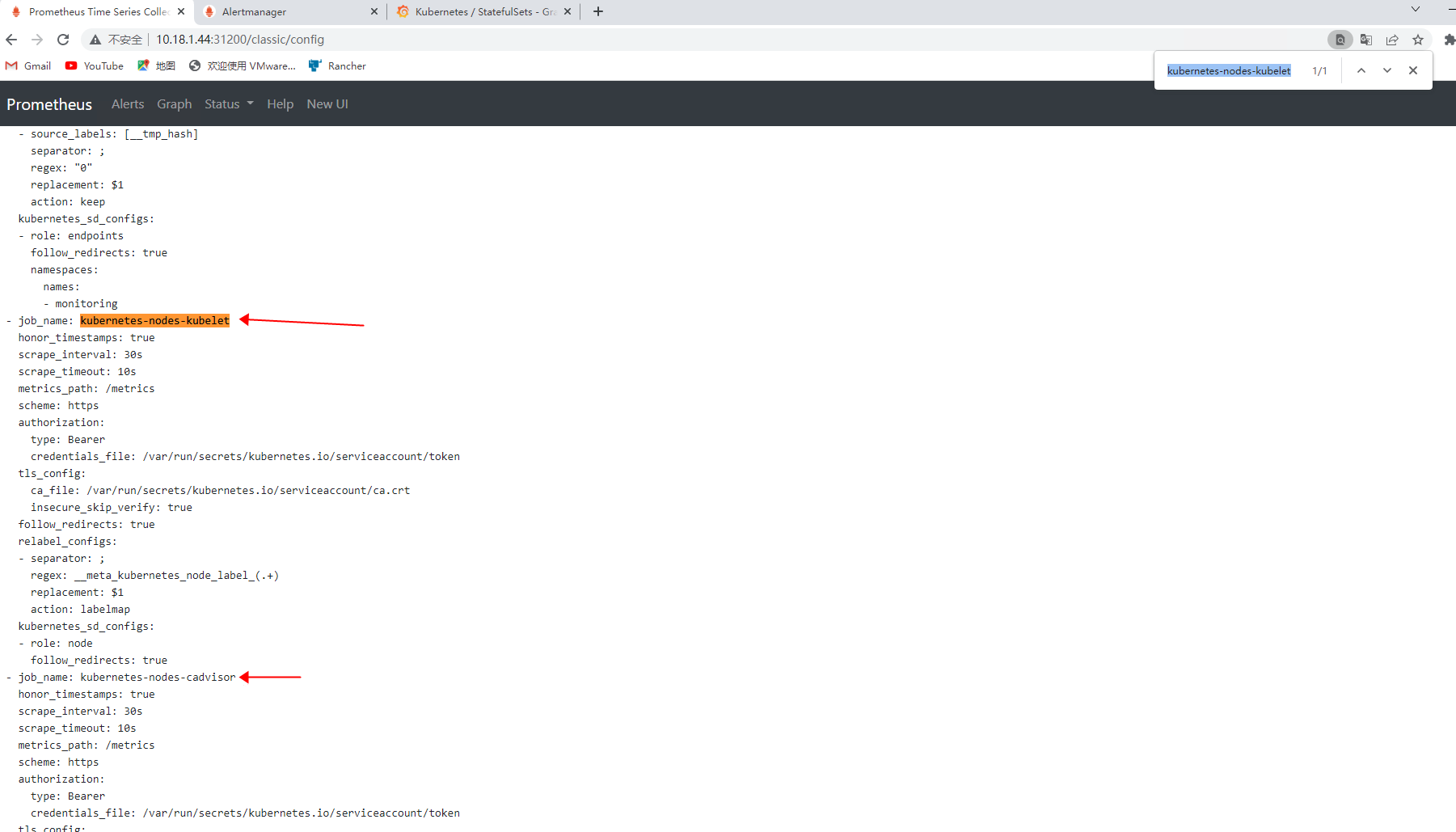
部署prometheus alert全家桶
https://github.com/feiyu563/PrometheusAlert
kubectl apply -n monitoring -f prometheus-alert
修改alertmanager,对接告警中心
vim alertmanager/alertmanager-secret.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
route:
group_by: ['instance']
group_wait: 10s
group_interval: 10s
repeat_interval: 1m
receiver: 'web.hook.prometheusalert'
receivers:
- name: 'web.hook.prometheusalert'
webhook_configs:
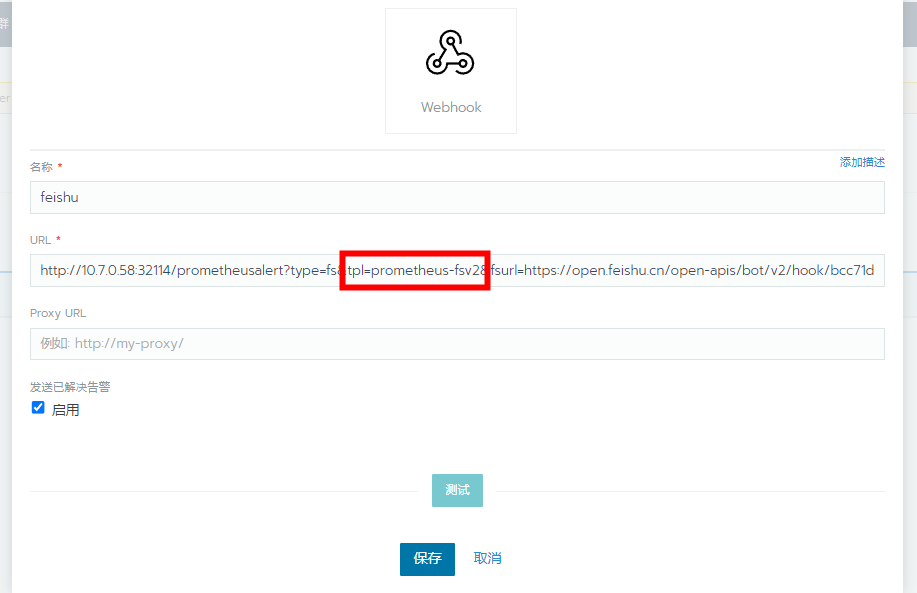
- url: 'http://prometheus-alert-center:8080/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/bcxxxxxxx'
#inhibit_rules:
#- source_match:
# severity: 'critical'
# target_match:
# severity: 'warning'
# equal: ['alertname', 'dev', 'instance']
配置告警模板:
https://github.com/feiyu563/PrometheusAlert/issues/30
把模板名字改成feishu,因为alertmanager里面的url定义了名字为飞书
需要查看alert日志,获取json格式的告警信息,使用变量打印信息,自定义使用模板:
{{ $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved"}}
**[Rancher容器云平台恢复信息]({{$v.generatorURL}})**
*[{{$v.labels.alertname}}]({{$var}})*
告警级别:{{$v.labels.severity}}
开始时间:{{TimeFormat $v.startsAt "2006-01-02 15:04:05 UTC"}}
结束时间:{{TimeFormat $v.endsAt "2006-01-02 15:04:05 UTC"}}
集群ID: {{$v.labels.cluster_name}}
故障主机IP: {{$v.labels.instance}}
PromQL: {{$v.alert.expression}}
触发告警持续时间: {{$v.labels.duration}}
当前值为:**{{$v.annotations.current_value}}**
详细信息:**{{$v.annotations.description}}**
{{else}}
**[Rancher容器云平台告警信息]({{$v.labels.server_url}})**
*[{{$v.labels.alertname}}]({{$var}})*
告警级别:{{$v.labels.severity}}
开始时间:{{TimeFormat $v.startsAt "2006-01-02 15:04:05 UTC"}}
{{if eq $v.endsAt "0001-01-01T00:00:00Z"}}
结束时间: {{ printf "告警当前仍然存在!"}}
{{else}}
结束时间: {{TimeFormat $v.endsAt "2006-01-02 15:04:05 UTC"}}
{{end}}
集群ID: {{$v.labels.cluster_name}}
故障主机IP: {{$v.labels.instance}}
PromQL: {{$v.labels.expression}}
触发告警持续时间: {{$v.labels.duration}}
当前值为:**{{$v.annotations.current_value}}**
详细信息:**{{$v.annotations.description}}**
{{end}}
{{ end }}
使用这个模板:
{{ $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved"}}
**[Prometheus 恢复通知]({{$v.generatorURL}})**
集群 ID: {{$v.labels.cluster_name}}
告警名称:{{$v.labels.alertname}}
告警状态:{{$v.status}}
开始时间:{{TimeFormat $v.startsAt "2006-01-02 15:04:05"}}
结束时间:{{TimeFormat $v.endsAt "2006-01-02 15:04:05"}}
实例地址:{{$v.labels.instance}}
命名空间:{{$v.labels.namespace}}
POD名称:{{$v.labels.pod}}
详细信息:**{{$v.annotations.description}}**
{{else}}
**[Prometheus 报警通知]({{$v.generatorURL}})**
集群 ID: {{$v.labels.cluster_name}}
告警名称:{{$v.labels.alertname}}
告警级别:{{$v.labels.severity}}
开始时间:{{TimeFormat $v.startsAt "2006-01-02 15:04:05"}}
实例地址:{{$v.labels.instance}}
命名空间:{{$v.labels.namespace}}
POD名称:{{$v.labels.pod}}
详细信息:**{{$v.annotations.description}}**
{{end}}
{{ end }}
rancher对接prometheus-alert全家桶告警中心
注意,URL这里的tpl=xxxxxx 必须要和alert告警中心自定义模板的名字一致!
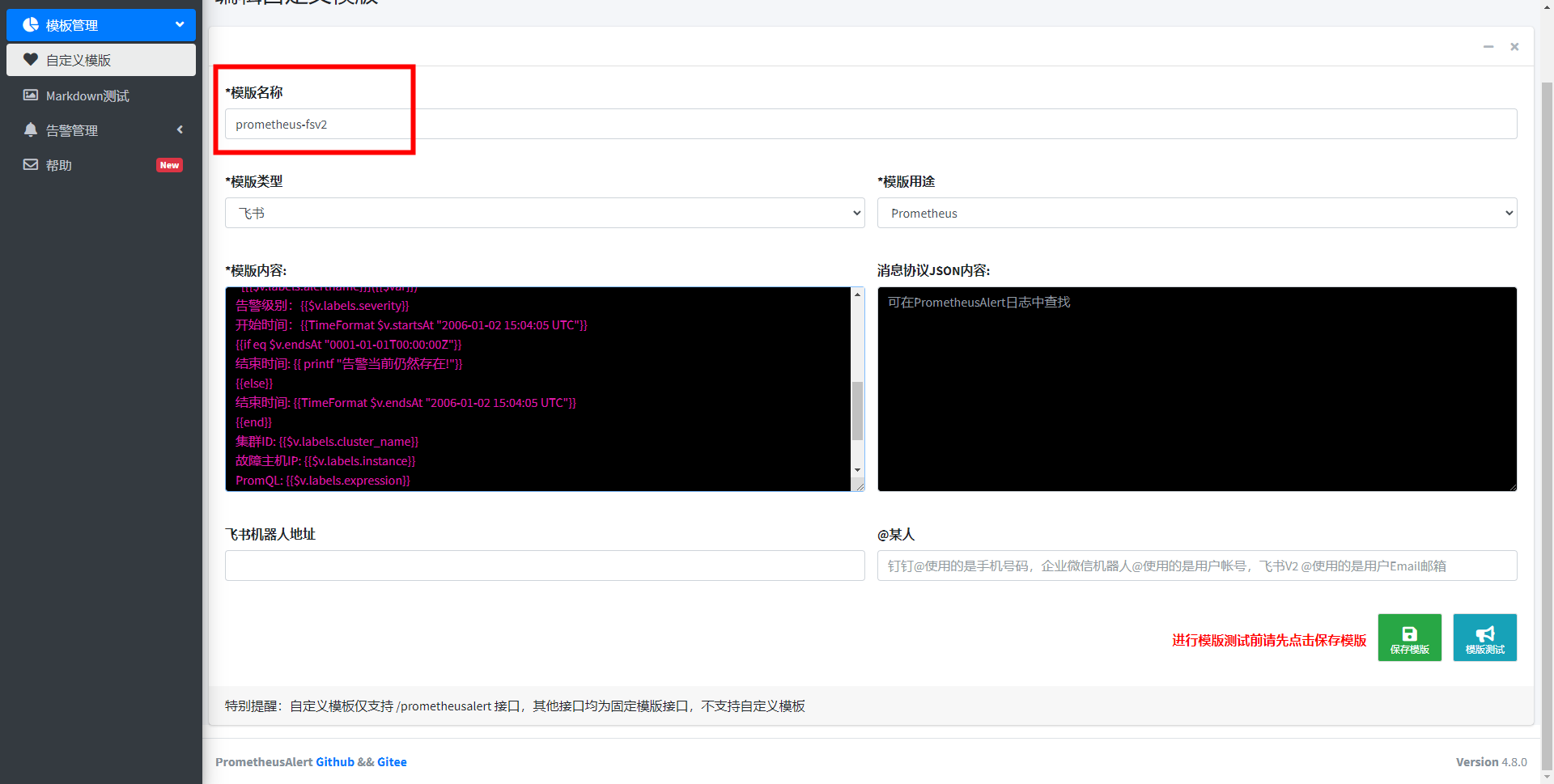
下面是测试使用的json文件
{
"receiver": "prometheus-alert-center",
"status": "firing",
"alerts": [{
"status": "firing",
"labels": {
"alertname": "TargetDown",
"index": "1",
"instance": "example-1",
"job": "example",
"level": "2",
"service": "example"
},
"annotations": {
"description": "target was down! example dev /example-1 was down for more than 120s.",
"level": "2",
"timestamp": "2020-05-21 02:58:07.829 +0000 UTC"
},
"startsAt": "2020-05-21T02:58:07.830216179Z",
"endsAt": "0001-01-01T00:00:00Z",
"generatorURL": "https://prometheus-alert-center/graph?g0.expr=up%7Bjob%21%3D%22kubernetes-pods%22%2Cjob%21%3D%22kubernetes-service-endpoints%22%7D+%21%3D+1\u0026g0.tab=1",
"fingerprint": "e2a5025853d4da64"
}],
"groupLabels": {
"instance": "example-1"
},
"commonLabels": {
"alertname": "TargetDown",
"index": "1",
"instance": "example-1",
"job": "example",
"level": "2",
"service": "example"
},
"commonAnnotations": {
"description": "target was down! example dev /example-1 was down for more than 120s.",
"level": "2",
"timestamp": "2020-05-21 02:58:07.829 +0000 UTC"
},
"externalURL": "https://prometheus-alert-center",
"version": "4",
"groupKey": "{}/{job=~\"^(?:.*)$\"}:{instance=\"example-1\"}"
}
告警规则大全:
https://help.aliyun.com/document_detail/176180.html
监控etcd
第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
第三步确保 Service 对象可以正确获取到 metrics 数据
创建secrets资源
首先查看etcd引用的证书文件
创建secret资源
kubectl -n monitoring create secret generic etcd-certs \
--from-file=/etc/etcd/ssl/ca.pem \
--from-file=/etc/etcd/ssl/server-key.pem \
--from-file=/etc/etcd/ssl/server.pem
apply Prometheus配置文件
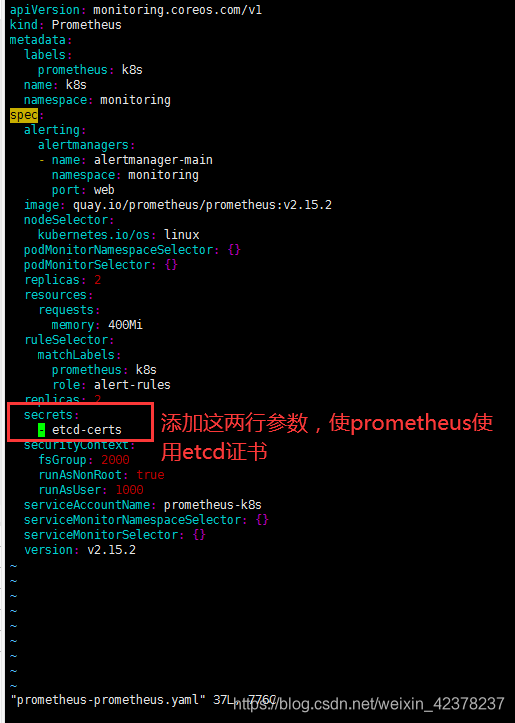
kubectl apply -f prometheus-prometheus.yaml
进入pod查看是否可以看到证书
kubectl exec -it -n monitoring prometheus-k8s-0 -- /bin/sh
/prometheus $ ls -l /etc/prometheus/secrets/etcd-certs/
total 0
lrwxrwxrwx 1 root root 22 Oct 24 07:20 k8s-root-ca.pem -> ..data/k8s-root-ca.pem
lrwxrwxrwx 1 root root 25 Oct 24 07:20 kubernetes-key.pem -> ..data/kubernetes-key.pem
lrwxrwxrwx 1 root root 21 Oct 24 07:20 kubernetes.pem -> ..data/kubernetes.pem
修改etcd的ServiceMonitor文件
vim prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: http-metrics #注意要和下面service的port名字一致
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/etcd/ssl/ca.pem
certFile: /etc/etcd/ssl/server.pem
keyFile: /etc/etcd/ssl/server-key.pem
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd-k8s
namespaceSelector:
matchNames:
- kube-system
kubectl apply -f prometheus-serviceMonitorEtcd.yaml
创建 Service
vim prometheus-etcdService.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd-k8s
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd-k8s
subsets:
- addresses:
- ip: 200.200.100.71
- ip: 200.200.100.72
- ip: 200.200.100.73
ports:
- name: http-metrics
port: 2379
protocol: TCP
kubectl apply -f prometheus-etcdService.yamlPrometheus 的 Dashboard 中查看 targets,便会有 etcd 的监控项