Prometheus监控-Ceph告警规则(全网最全最详细)
groups:
- name: ceph.rules
rules:
- alert: Ceph Target Down
expr: up{job="C2-Ceph"} == 0
for: 5m
#for: 1m
labels:
severity: critical
cluster_name: C2-Ceph-Cluster
annotations:
description: CEPH target down for more than 2m, please check - it could be a either exporter crash or a whole cluster crash
summary: CEPH exporter down
- alert: Ceph Error State
expr: ceph_health_status >= 1
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: critical
annotations:
description: Ceph is in Error state longer than 5m, please check status of pools and OSDs
summary: CEPH in ERROR
- alert: Ceph Warn State
expr: ceph_health_status == 1
for: 10m
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: Ceph is in Warn state longer than 30m, please check status of pools and OSDs
summary: CEPH in WARN
- alert: Osd Down
expr: ceph_osd_up == 0
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: OSD is down longer than 30 min, please check whats the status
summary: OSD down
- alert: Ceph Pg Unavailable
expr: ceph_pg_total - ceph_pg_active > 0
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: critical
annotations:
description: Some groups are unavailable on {{ $labels.cluster }}. Please check their detailed status and current configuration.
summary: PG UNAVAILABLE [{{ $value }}] on {{ $labels.cluster }}
- alert: Ceph Osd Reweighted
expr: ceph_osd_weight < 1
for: 1h
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: OSD {{ $labels.ceph_daemon}} on cluster {{ $labels.cluster}} was reweighted for too long. Please either create silent or fix that issue
summary: OSD {{ $labels.ceph_daemon }} on {{ $labels.cluster }} reweighted - {{ $value }}
- alert: Disk(s) Near Full
expr: (ceph_osd_stat_bytes_used / ceph_osd_stat_bytes) * 100 > 85
for: 2m
labels:
severity: critical
cluster_name: C2-Ceph-Cluster
annotations:
summary: "Disk(s) Near Full"
description: "This shows how many disks are at or above 85% full. Performance may degrade beyond this threshold on filestore (XFS) backed OSD's."
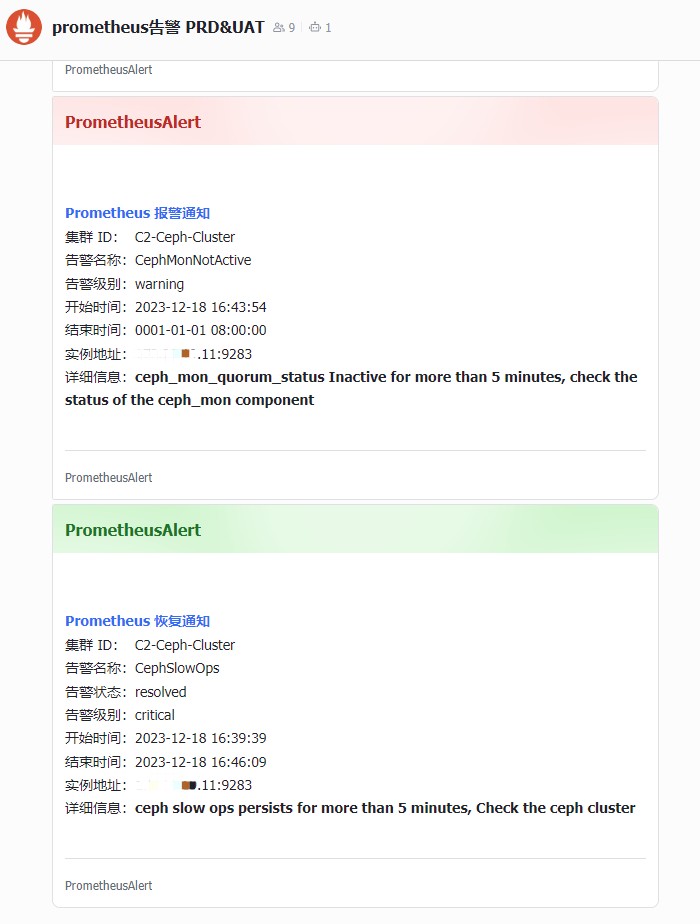
- alert: Ceph Mon Not Active
expr: ceph_mon_quorum_status == 0
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: ceph_mon_quorum_status Inactive for more than 5 minutes, check the status of the ceph_mon component
summary: CEPH in warning
- alert: Ceph Slow Ops
expr: ceph_health_detail{name="SLOW_OPS"} == 1
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: critical
annotations:
description: ceph slow ops persists for more than 5 minutes, Check the ceph cluster
summary: CEPH in critical
- alert: Ceph Pg Inconsistent
expr: ceph_pg_inconsistent == 1
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: critical
annotations:
description: ceph pg inconsistency persists for more than 5 minutes, check the ceph cluster in time
summary: CEPH in critical
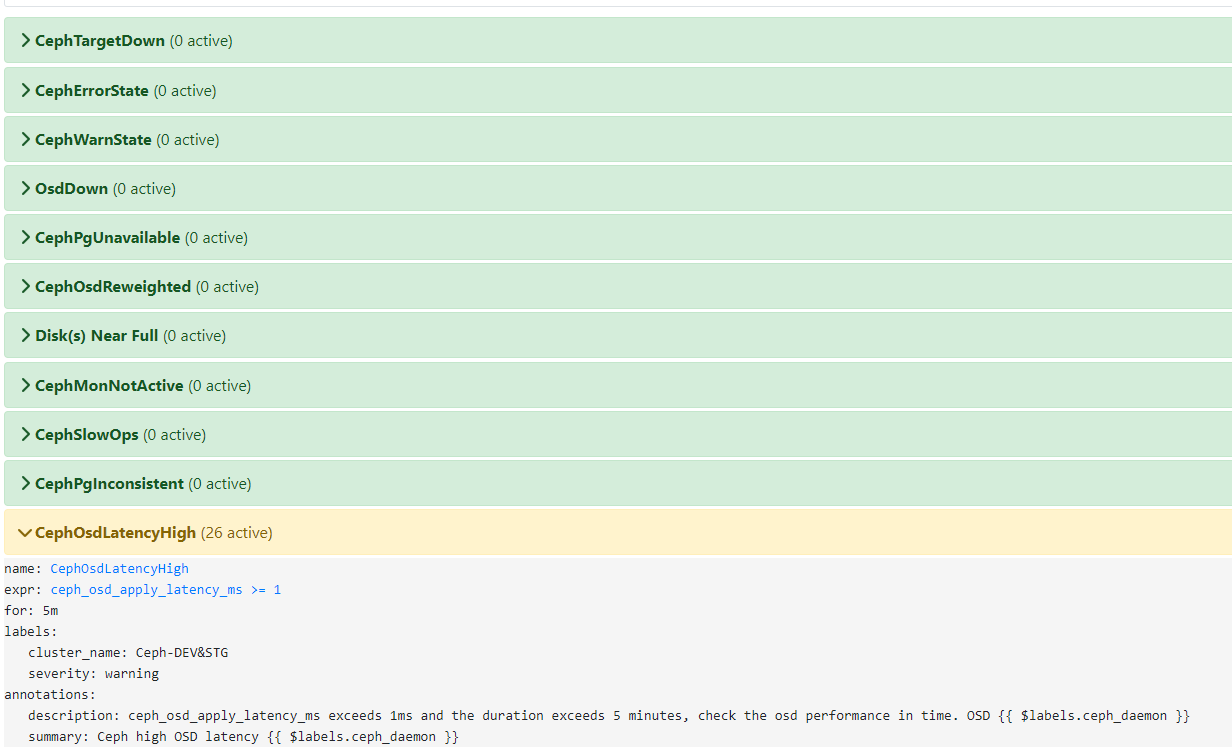
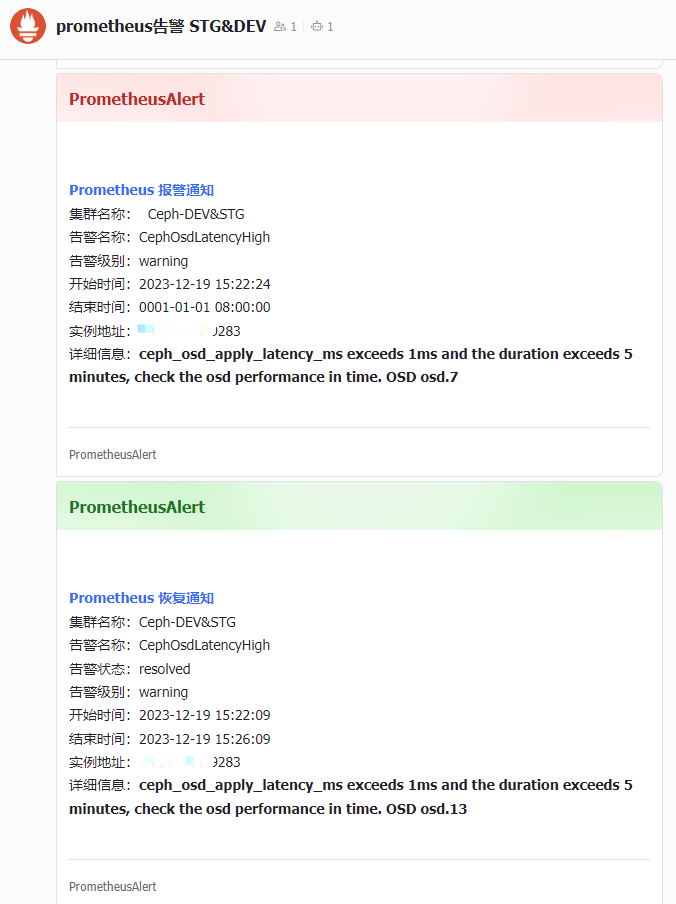
- alert: Ceph Osd Latency High
expr: ceph_osd_apply_latency_ms >= 80
for: 5m
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: ceph_osd_apply_latency_ms exceeds 80ms and the duration exceeds 5 minutes, check the osd performance in time. {{ $labels.ceph_daemon}}
summary: Ceph high OSD latency {{ $labels.ceph_daemon }}
- alert: Ceph Read Iops High
#irate 函数用于计算时间序列的瞬时速率,但其在短时间范围内可能不太稳定。因此,我们可以尝试使用 rate 函数进行平均速率计算,并设置一个较短的时间范围。
expr: sum(round(rate(ceph_osd_op_r[1m]))) by (instance) > 5000
for: 2m
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: ceph_osd_op_r the cluster IOPS exceeds 5000 for more than 2 minutes, check whether the cluster performance is abnormal
summary: ceph osd has high read IOPS
- alert: Ceph Write Iops High
expr: sum(round(rate(ceph_osd_op_w[1m]))) by (instance) > 3000
for: 2m
labels:
cluster_name: C2-Ceph-Cluster
severity: warning
annotations:
description: ceph_osd_op_w the cluster IOPS exceeds 3000 for more than 2 minutes, check whether the cluster performance is abnormal
summary: ceph osd has high write IOPS
随便把监控规则调低测试告警信息