
第一章 Prometheus介绍
官方地址
https://prometheus.io/docs/introduction/overview/
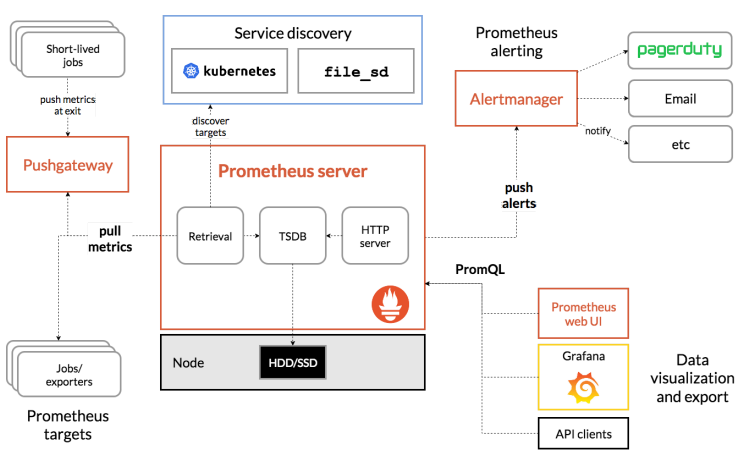
组件架构
Prometheus Server 服务端,主动拉数据,存入TSDB数据库
TSDB 时序数据库,用于存储拉取来的监控数据
exporter 暴露指标的组件,需要独立安装
Pushgatway push的方式将指标数据推送到网关
Alertmanager 报警组件
Promtheus Web UI prometheus自带的简单web界面
第二章 安装部署
官方配置文件说明
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
编写configmap
cat > prom-cm.yml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: prom
data:
prometheus.yml: |
global: #全局配置
scrape_interval: 15s #抓取数据间隔
scrape_timeout: 15s #抓取超时时间
scrape_configs: #拉取配置
- job_name: 'prometheus' #任务名称
static_configs: #静态配置
- targets: ['localhost:9090'] #抓取数据节点的IP端口
EOF
创建PV和PVC
cat > prom-pv-pvc.yml << 'EOF'
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-local
labels:
app: prometheus
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
storageClassName: local-storage
local:
path: /data/k8s/prometheus
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
persistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: prom
spec:
selector:
matchLabels:
app: prometheus
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: local-storage
EOF
编写RBAC
cat > prom-rbac.yml << 'EOF'
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: prom
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: prom
EOF
编写deployment
cat > prom-dp.yml << 'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: prom
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus #引用RBAC创建的ServiceAccount
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data
- name: config-volume
configMap:
name: prometheus-config
initContainers: #由初始化容器将数据目录的属性修改为
nobody用户和组
- name: fix-permissions
image: busybox
command: [chown, -R, "nobody:nobody", /prometheus]
volumeMounts:
- name: data
mountPath: /prometheus
containers:
- name: prometheus
image: prom/prometheus:v2.24.1
args:
- "--config.file=/etc/prometheus/prometheus.yml" #指定配置文件
- "--storage.tsdb.path=/prometheus" #tsdb数据库保存路径
- "--storage.tsdb.retention.time=24h" #数据保留时间,默认15天
- "--web.enable-admin-api" #控制对admin HTTP API的访问
- "--web.enable-lifecycle" #支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- name: http
containerPort: 9090
volumeMounts:
- name: config-volume
mountPath: "/etc/prometheus"
- name: data
mountPath: "/prometheus"
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
EOF
编写Service
cat > prom-svc.yml << 'EOF'
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: prom
labels:
app: prometheus
spec:
selector:
app: prometheus
ports:
- name: web
port: 9090
targetPort: http
EOF
编写ingress
cat > prom-ingress.yml << 'EOF'
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus
namespace: prom
labels:
app: prometheus
spec:
rules:
- host: prom.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: prometheus
port:
number: 9090
EOF
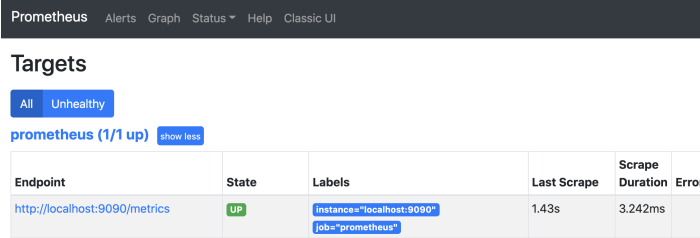
访问promtheus
第三章 应用检测
应用监控说明
prometheus的数据指标都是通过http实现的metrics接口获取到的,所以应用只需要暴露metrics接口, prometheus就可以定期的去拉取数据。
随着容器和k8s的流行,现在很多服务都自己内置了metrics接口,对于本身没有提供metrics的应用, promtheus官方也提供了很多可以直接使用的exporter来获取指标数据,比如: redis_exporter,mysql_exporter等。
自带/metrics接口的应用检测
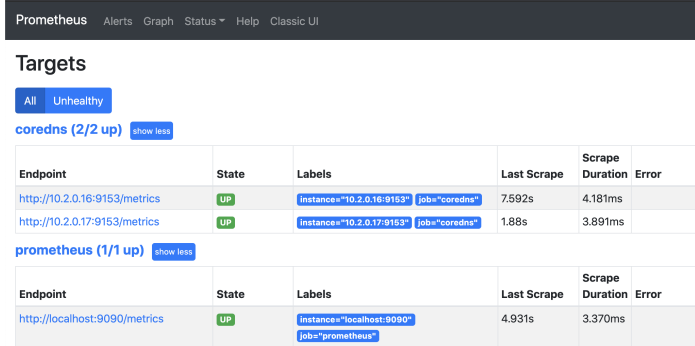
k8s里的coredns自带的metrics接口,所以可以先拿来试试手,查看croedns的配置文件可以发现提 供prometheus服务采集的端口是9153。
编辑prometheus的配置文件来发现这个服务
cat prom-cm.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: prom
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'coredns' #任务名称
static_configs: #静态配置
- targets: ['10.2.0.16:9153','10.2.0.17:9153'] #这里直接写coredns的ClusterIP
更新prom-cm资源配置
因为在prometheus的配置文件里配置了热更新的参数,所以可以不用重启pod在线热更新配置使其生效。
热更新promtheus配置
使用exporter监控
有些应用自带的metrics接口,那么对于没有自带metrics接口的应用,可以使用各种exporter监控,官方已经提供了非常多的exporter,具体可以去官网查阅,地址如下:
https://prometheus.io/docs/instrumenting/exporters/
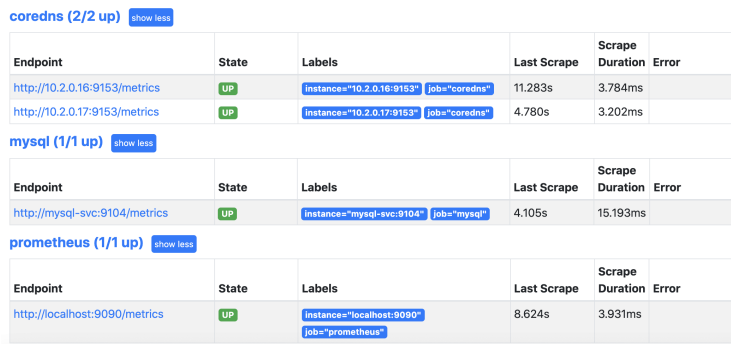
下面以mysql的exporter举例,具体的做法就是在每个mysql的pod里部署一个exporter服务来监控 mysql的各项数据。
部署mysql-exporter省略
修改prom配置文件
cat > prom-cm.yml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: prom
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'coredns'
static_configs:
- targets: ['10.2.0.16:9153','10.2.0.17:9153']
- job_name: 'mysql'
static_configs:
- targets: ['mysql-svc:9104']
EOF
热更新配置
第四章 监控集群节点
集群监控组件介绍
k8s节点的运行状态:内存,cpu,磁盘,网络等。
k8s组件的运行状态:kube-apiserver,kube-controller,kube-scheduler,coredns等。
k8s资源的运行状态:Deployment,Daemoset,Service,Ingress等。
对于k8s集群的监控,主要有以下几种方案:
cAdvisor: 监控容器内部的资源使用情况,已经集成在kubelet里了
kube-state-metrics: 监控k8s资源的使用状态
metrics-server: 监控k8s的cpu,内存,磁盘,网络等状态
监控集群节点
传统架构监控节点运行状态有非常成熟的zabbix可以使用,在k8s里可以直接使用prometheus 官方的node-exporter来获取节点的各种指标,比如cpu,memory,disk,net等信息。
项目地址:https://github.com/prometheus/node_exporter
因为是节点监控,所以采用DaemonSet模式,在每个节点都部署 node-exporter
node-exprot部署过程省略
服务发现
每个节点上部署了node-exporter,要如何采集到的每个节点的数据呢?如果按照上面的操作方法写死IP工作量太大,写service的话只会显示一条数据,这两种方式都不太方便。那么 有什么好办法可以解决这种情况吗?这种时候就需要使用prometheus的服务发现功能了。
在k8s里,prometheus通过与k8s的API集成,支持5种服务发现模式,分别为:Node、Service、Pod、 Endpoints、Ingress
官方文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
node节点自动发现
修改prometheus配置
- job_name: 'nodes'
kubernetes_sd_configs: #k8s自动服务发现
- role: node
生效配置
查看prometheus
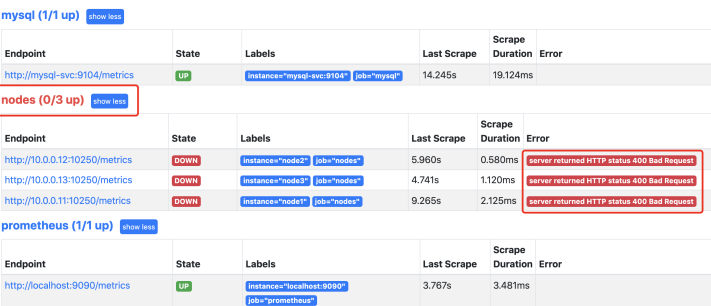
这是发现提示有问题,因为prometheus默认去访问的是10250,需要把10250替换为9100
这里就需要使用prometheus提供的relabel_configs的replace功能。replace可以在采集数据之前通过 Target的Metadata信息,动态重写Label的值。这里可以把_address_这个标签的端口修改为9100
relabel_config配置官方说明:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config
修改prometheus配置:
- job_name: 'nodes'
kubernetes_sd_configs:
- role: node
relabel_configs: #配置重写
- action: replace #基于正则表达式匹配执行的操作
source_labels: ['__address__'] #从源标签里选择值
regex: '(.*):10250' #提取的值与之匹配的正则
表达式
replacement: '${1}:9100' #执行正则表达式替换的值
target_label: __address__ #结果值在替换操作中写入的标签
生效配置
prometheus查看:
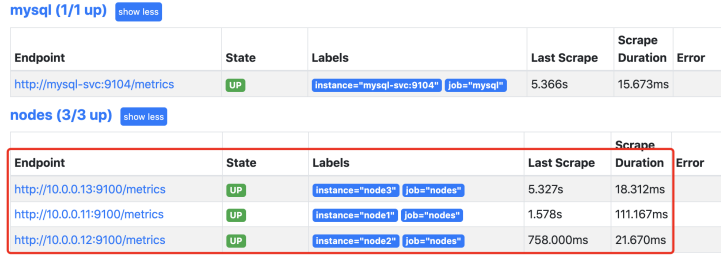
这里还有一个问题,就是节点标签目前只有主机名和任务名,不适合后期分组查询数据时候,所以需要把更多的标签添加进去,prometheus对于k8s的自动发现node模式支持以下的标签,详情可以 查询官网:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
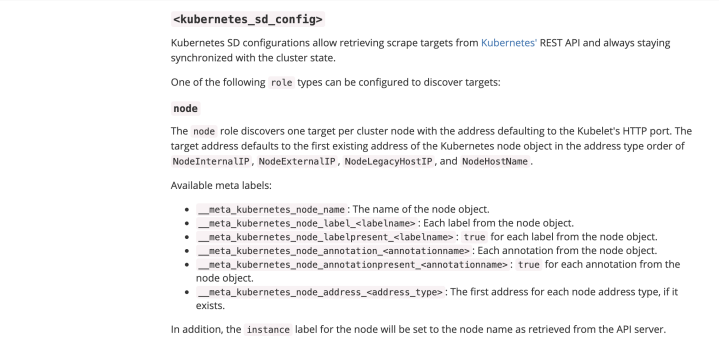
标签解释:
__meta_kubernetes_node_name: 节点对象的名称。
__meta_kubernetes_node_label: 节点对象的每个标签
__meta_kubernetes_node_annotation: 每个节点的注释
__meta_kubernetes_node_address: 每个节点地址类型的第一个地址
修改配置:
- job_name: 'nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: replace
source_labels: ['__address__']
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
- action: labelmap #将正则表达式与所有标签名称匹配
regex: __meta_kubernetes_node_label_(.+) #提取符合正则匹配的标签,然后天交到Label里
配置解释:
官方说明:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#relabel_config
添加一个动作为labelmap,作用是将符合__meta_kubernetes_node_label_(.+)正则表达式提取的标签添加到Lable标签里。
生效配置
查看prometheus
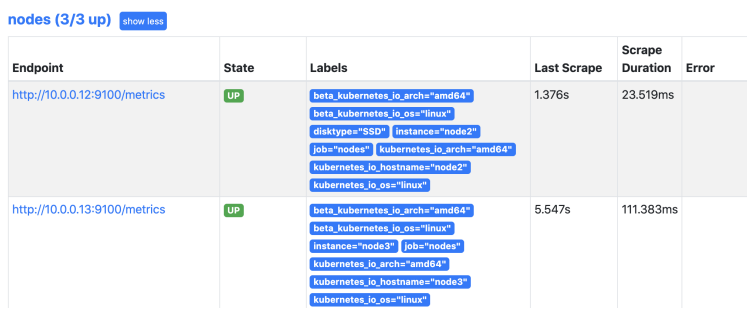
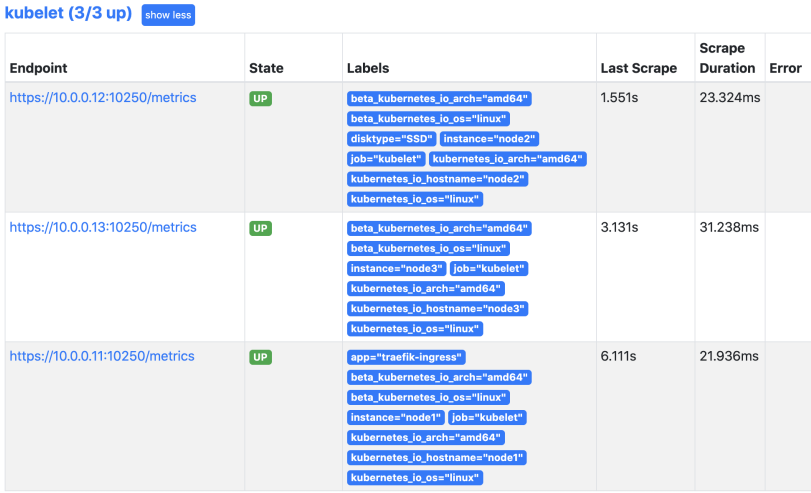
kubelet节点自动发现
prometheus自动发现kubelet访问的是10250端口,但是必须是https协议,而且必须提供证书,可以直接使用k8s的证书。除此之外访问集群资源还需要相应的权限,还需要带上刚才为prometheus 创建的service-account-token,实际上为prometheus创建的RBAC资源产生的secrets会以文件挂载 的形式挂载到Pod里,所以查询的时候只要带上这个token就具备了查询集群资源的权限。另外还设置了跳过证书检查。
- job_name: 'kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
配置解释:
scheme: https #配置用于请求的协议
tls_config: #tls配置
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #ca证书
insecure_skip_verify: true #禁用证书检查
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
#serviceaccount授权,默认securt会以文件形式挂载到pod里
查看prometheus
第五章 容器监控
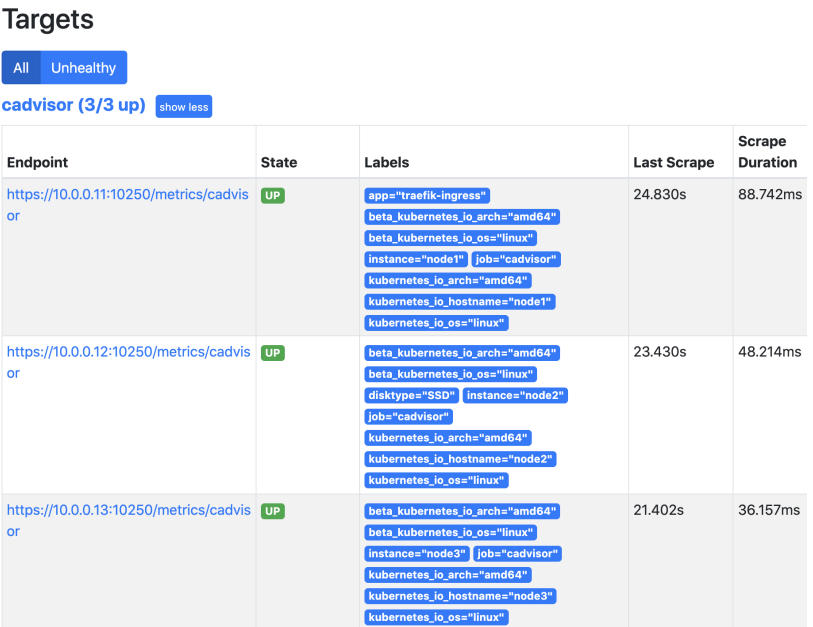
学习Docker的时候已经知道收集docker容器使用的是cAdvisor,而k8s的kubelet已经内置了 cAdvisor。所以只需要访问即可,可以使用访问kubelet的暴露的地址访问cAdvisor数据。 地址为:nodeip/metrics/cadvisor
配置文件:
- job_name: 'cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
- source_labels: [__meta_kubernetes_node_name]
regex: (.*)
replacement: /metrics/cadvisor
target_label: __metrics_path__
应用配置
查看prometheus
关于查询的数据可以查看官网的说明:
https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md
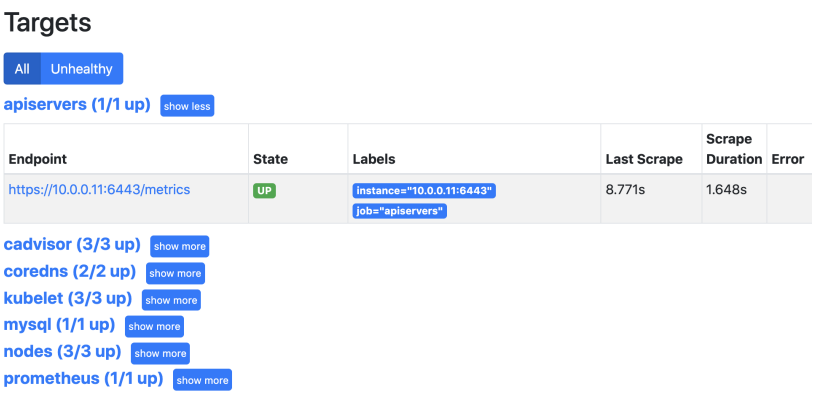
第六章 API Server监控
修改配置文件:
- job_name: 'apiservers'
kubernetes_sd_configs:
- role: endpoints
应用配置
查看prometheus
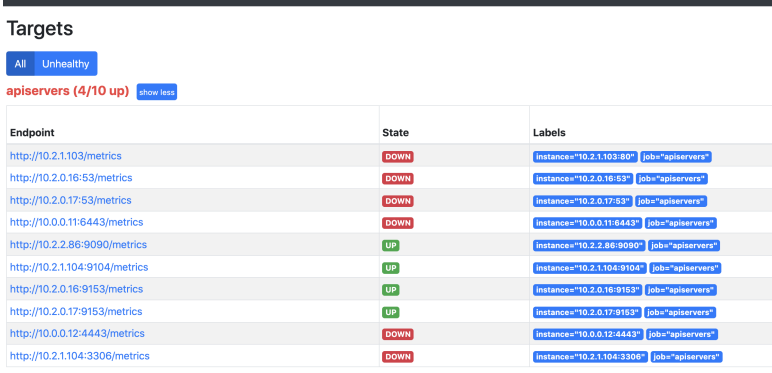
这时发现promtheus把所有的endpoint都找出来了,那么哪个才是需要的呢?通过查看API Server的svc可以发现API Server的通讯端口是6443,所以6443端口的服务才是需要的。
要想保留发现的API Server,那么就需要查看都有什么标签,然后将拥有这些标签的服务保留下来。
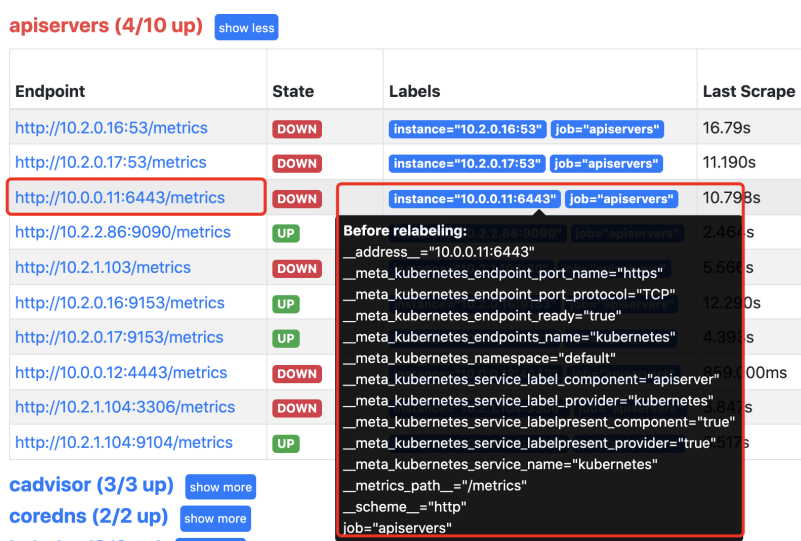
需要匹配的条件是标签名为__meta_kubernetes_service_label_component 的值为"apiserver"的服 务。
因为这个端口是https协议的,所以还需要带上认证的证书。
修改配置文件:
- job_name: 'apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_component]
action: keep
regex: apiserver
应用配置
查看prometheus
第七章 Pod监控
这里采集到的Pod监控也是使用自动发现Endpoints。只不过这里需要做一些匹配的处理.
配置如下:
- job_name: 'pods'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels:
[__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__address__,__meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
生效配置
查看prometheus
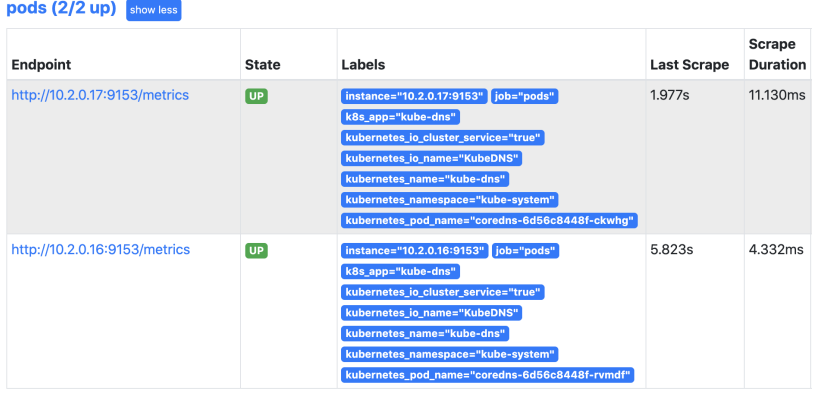
匹配参数解释:
__meta_kubernetes_service_annotation_prometheus_io_scrape 为 true
__address__的端口和__meta_kubernetes_service_annotation_prometheus_io_port 的端口一样
自动发现原理:
创建svc的时候添加了prometheus和metrics端口的注解,这样就能被prometheus自动发现
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
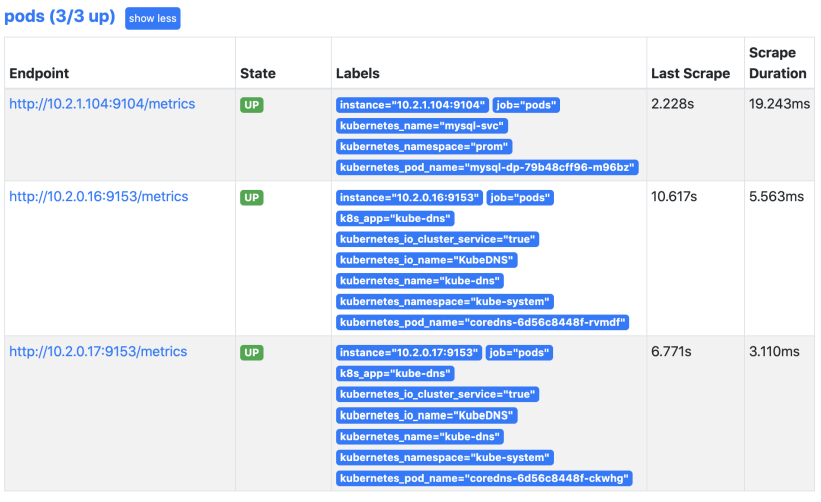
对应promethues自动发现里的数据:

那也就意味着以后发布的应用,只需要添加这两条注解就可以被自动发现了,现在可以来修改刚才创建的mysql配置,添加相关注解就可以自动被发现了。
---
kind: Service
apiVersion: v1
metadata:
name: mysql-svc
namespace: prom
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9104"
查看prometheus可以发现mysql的pod已经自动被发现了
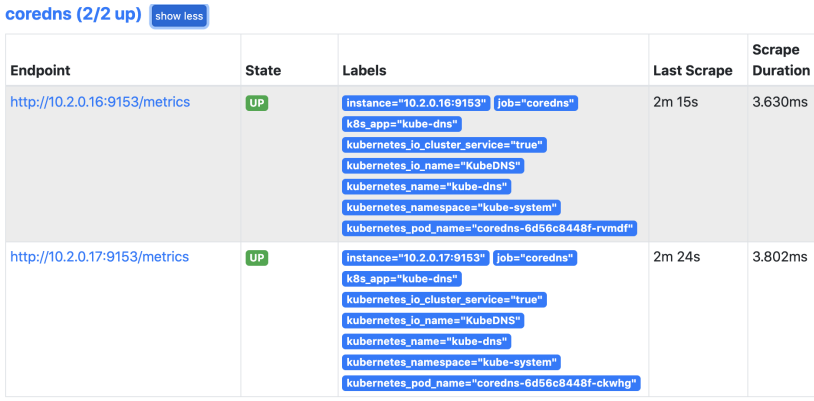
现在就可以删除刚才配置的静态mysql了,同理刚才静态配置的coredns也可以删掉了,同样使用自动发现来处理,配置如下:
- job_name: 'nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: ['__address__']
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file:
/var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file:
/var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
- source_labels: [__meta_kubernetes_node_name]
regex: (.*)
replacement: /metrics/cadvisor
target_label: __metrics_path__
- job_name: 'apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file:
/var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_component]
action: keep
regex: apiserver
- job_name: 'pods'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels:
[__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__address__,__meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'coredns'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels:
[__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__address__,__meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_endpoints_name]
action: keep
regex: kube-dns
应用配置
查看结果:
第八章 监控k8s资源对象
kube-state-metrics
刚才自动发现使用的是endpoints,监控的都是应用数据,但是在k8s内部的 pod,deployment,daemonset等资源也需要监控,比如当前有多少个pod,pod状态是什么样等等。
这些指标数据需要新的exporter来提供,那就是kube-state-metrics
项目地址:
https://github.com/kubernetes/kube-state-metrics
安装kube-state-metrics:
克隆代码:
git clone https://github.com/kubernetes/kube-state-metrics.git
修改配置:
主要修改镜像地址和添加自动发现的注解
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.1.1
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
创建资源配置
查看promtheus:

应用场景:
存在执行失败的Job: kube_job_status_failed
集群节点状态错误: kube_node_status_condition{condition="Ready",
status!="true"}==1
集群中存在启动失败的 Pod:kube_pod_status_phase{phase=~"Failed|Unknown"}==1
最近30分钟内有 Pod 容器重启:
changes(kube_pod_container_status_restarts_total[30m])>0
更多使用方法可以查看官方文档:
https://github.com/kubernetes/kube-state-metrics
第九章 Grafana添加数据源与安装插件
安装插件
grafana具有丰富的插件,使用一个非常强大的专门对k8s集群进行监控的插件
DevOpsProdigy KubeGraf 项目地址为:
https://github.com/devopsprodigy/kubegraf/
安装这个插件需要进入grafana的pod内进行安装
grafana-cli plugins install devopsprodigy-kubegraf-app
安装完成后还需要重启一下grafana才能生效,因为做了数据持久化,所以直接删除pod重新创建即可。
重启之后在grafana页面激活插件
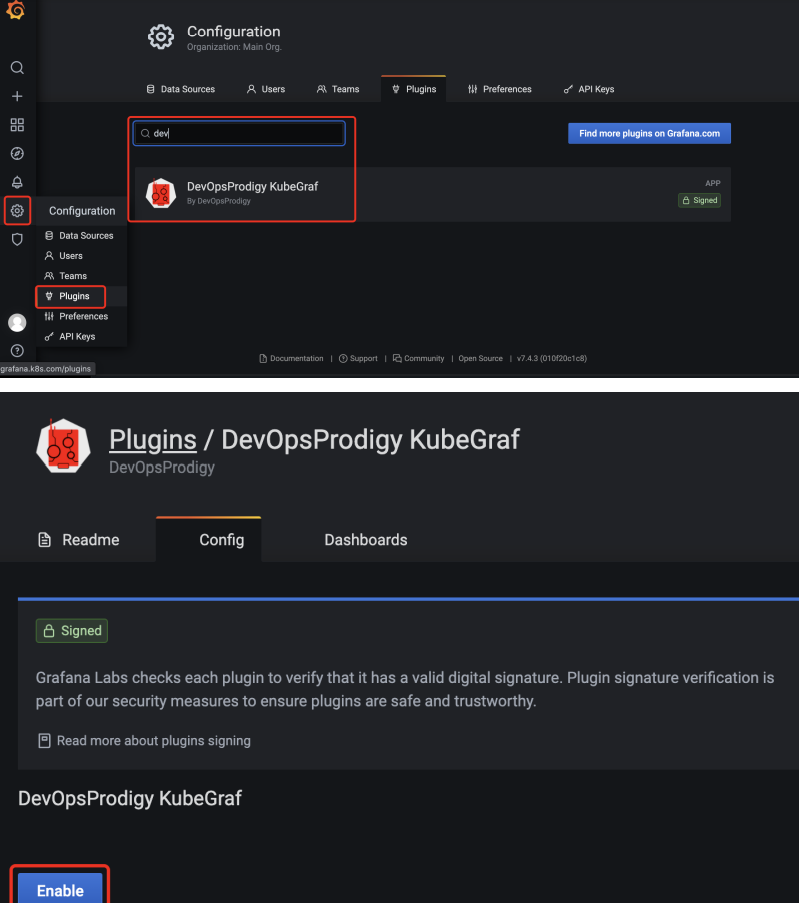
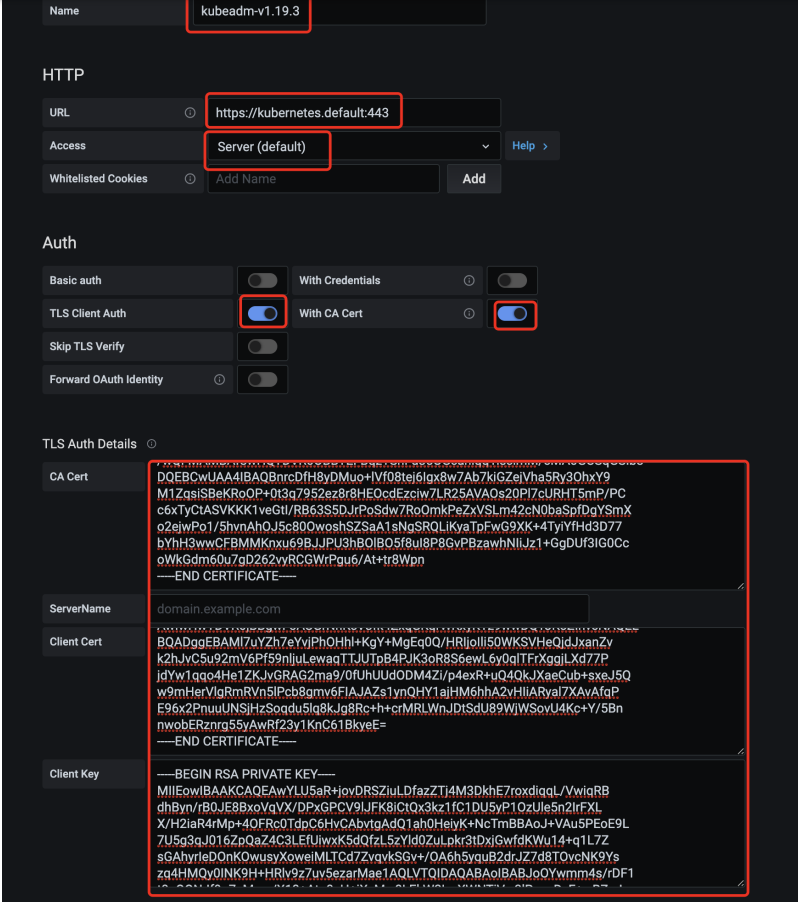
这里需要对验证,我们使用kubectl的config配置文件的内容来进行配置:
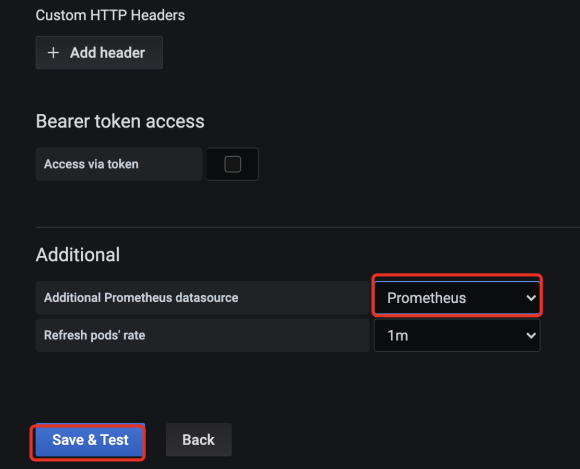
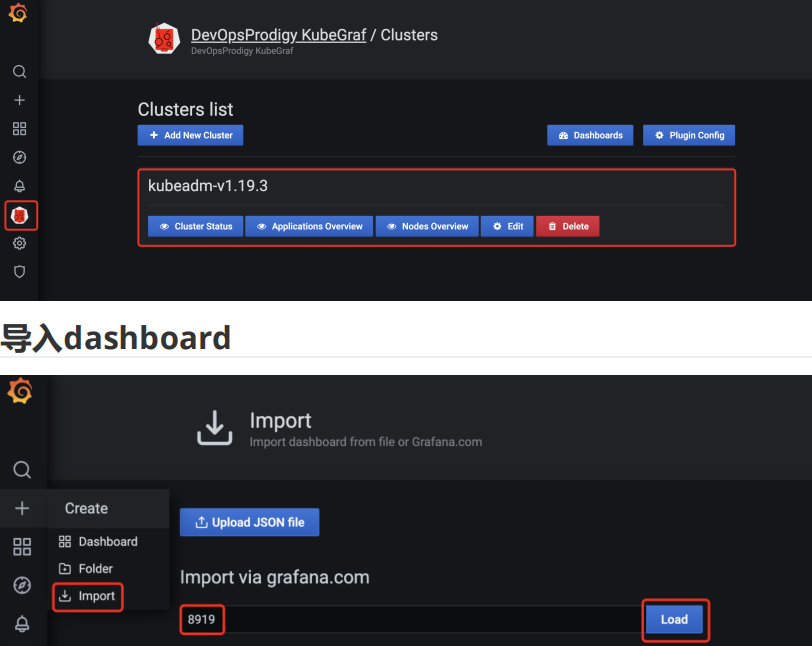
保存之后左边就会出现插件的图标,点击就可以查看了
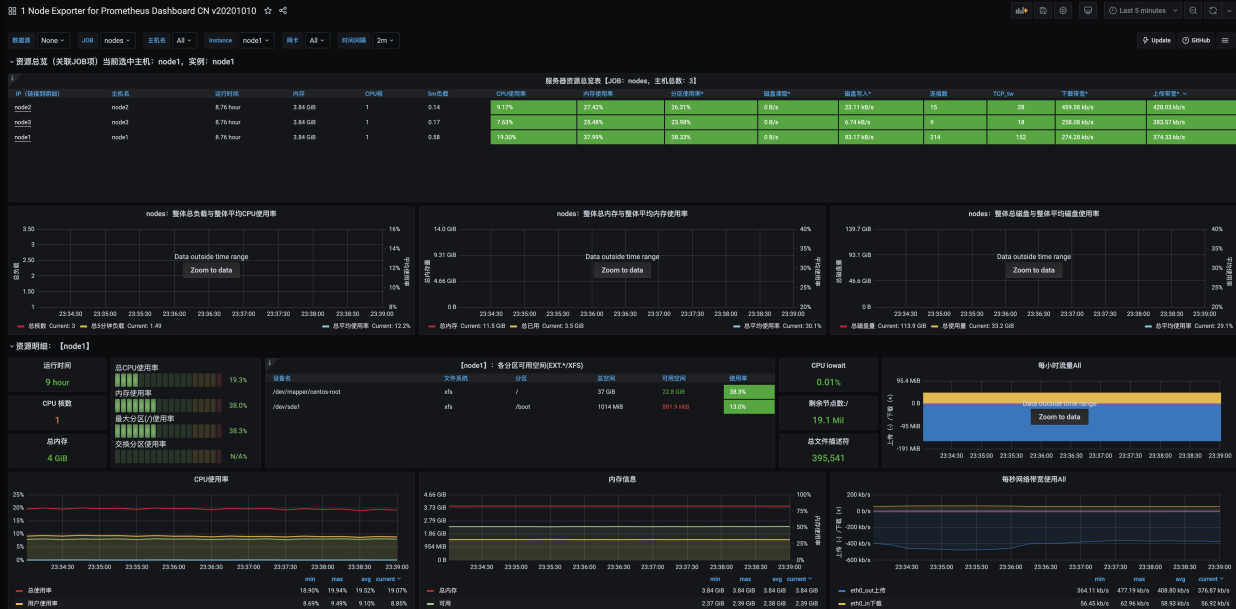
第十章 Alertmanager报警
cat > alertmanager.yml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: prom
data:
config.yml: |-
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: 'xxxx@qq.com'
smtp_auth_username: 'xxxx@qq.com'
smtp_auth_password: 'mxxxxxxx'
smtp_hello: 'qq.com'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 1h
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
group_wait: 10s
match:
team: node
receivers:
- name: 'default'
email_configs:
- to: 'xxxxx@qq.com'
send_resolved: true # 接受告警恢复的通知
- name: 'email'
email_configs:
- to: 'xxxxx@qq.com'
send_resolved: true
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: prom
labels:
app: alertmanager
spec:
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
volumes:
- name: alertcfg
configMap:
name: alert-config
containers:
- name: alertmanager
image: prom/alertmanager:v0.21.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: prom
labels:
app: alertmanager
spec:
selector:
app: alertmanager
ports:
- name: web
port: 9093
targetPort: http
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alertmanager
namespace: prom
labels:
app: alertmanager
spec:
rules:
- host: alertmanager.k8s.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: alertmanager
port:
number: 9093
EOF
应用配置
访问查看
配置报警规则
编写报警规则
cat > alert-rules.yml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-mon
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
evaluation_interval: 30s # 默认情况下每分钟对告警规则进行计算
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
rule_files:
- /etc/prometheus/rules.yml
...... # 省略prometheus其他部分
rules.yml: |
groups:
- name: test-node-mem
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20
for: 2m
labels:
team: node
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}"
EOF
