
benchmark集群故障测试过程
-
二进制k8s集群
-
pod-1和pod-2落在i9 node1 10.17.1.58
-
pod-3个pod落在i9 node2 10.17.1.59
关闭node2主机,node1 剩余2个pod日志刷出:
failed to consume PRICE-V2-RAW-TRADES: read tcp 172.17.24.4:36144->10.18.1.30:9092: i/o timeout"

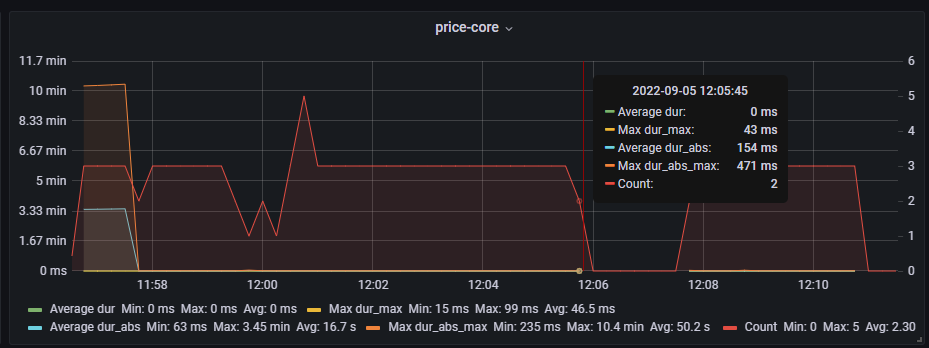
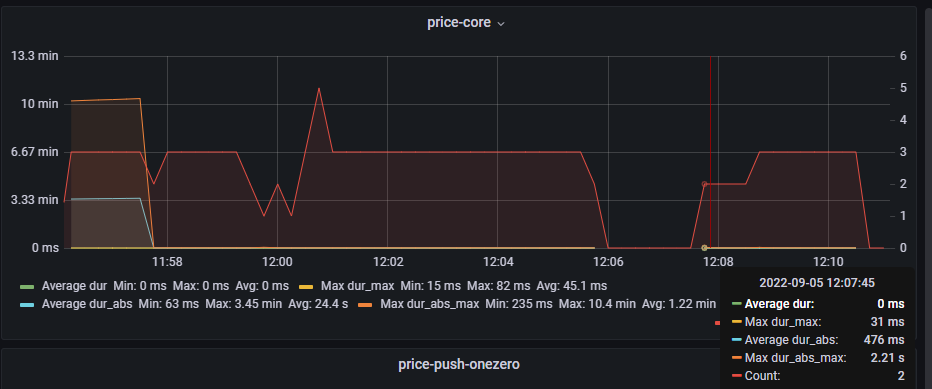
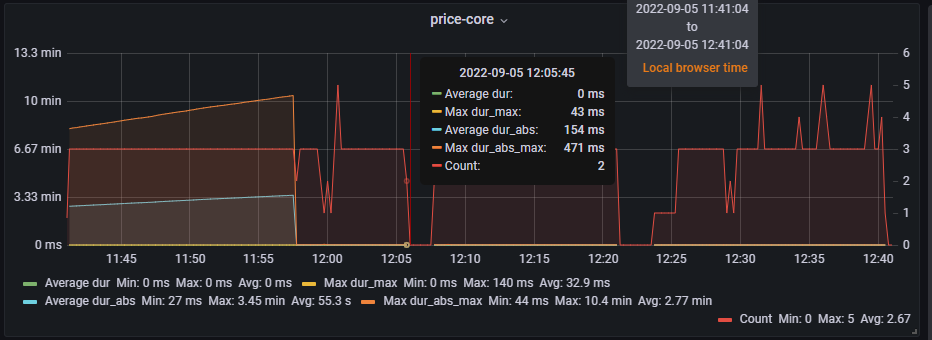
11:58分由3个pod变成2个pod
12:05分 2个pod就掉到了0
12:07分 2个pod恢复连接
12:09分 3个pod恢复连接
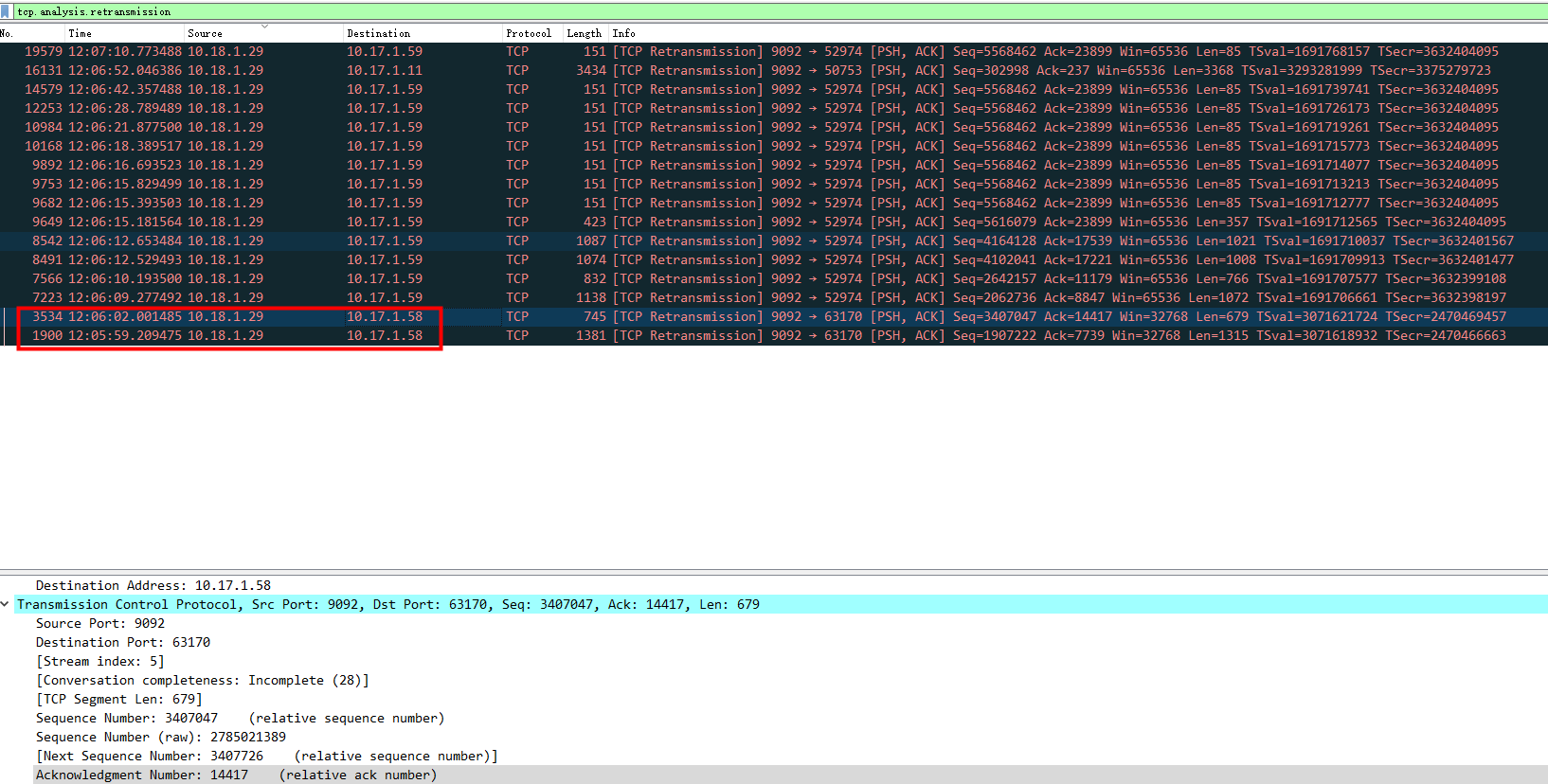
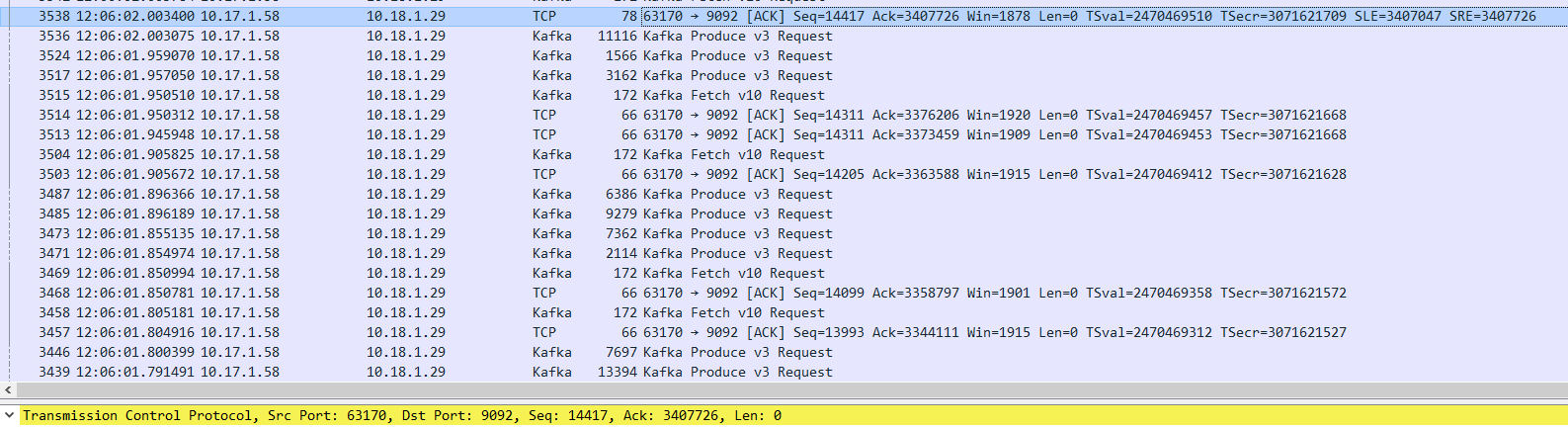
12:05:59 10.18.1.29 TCP重传 10.17.1.58
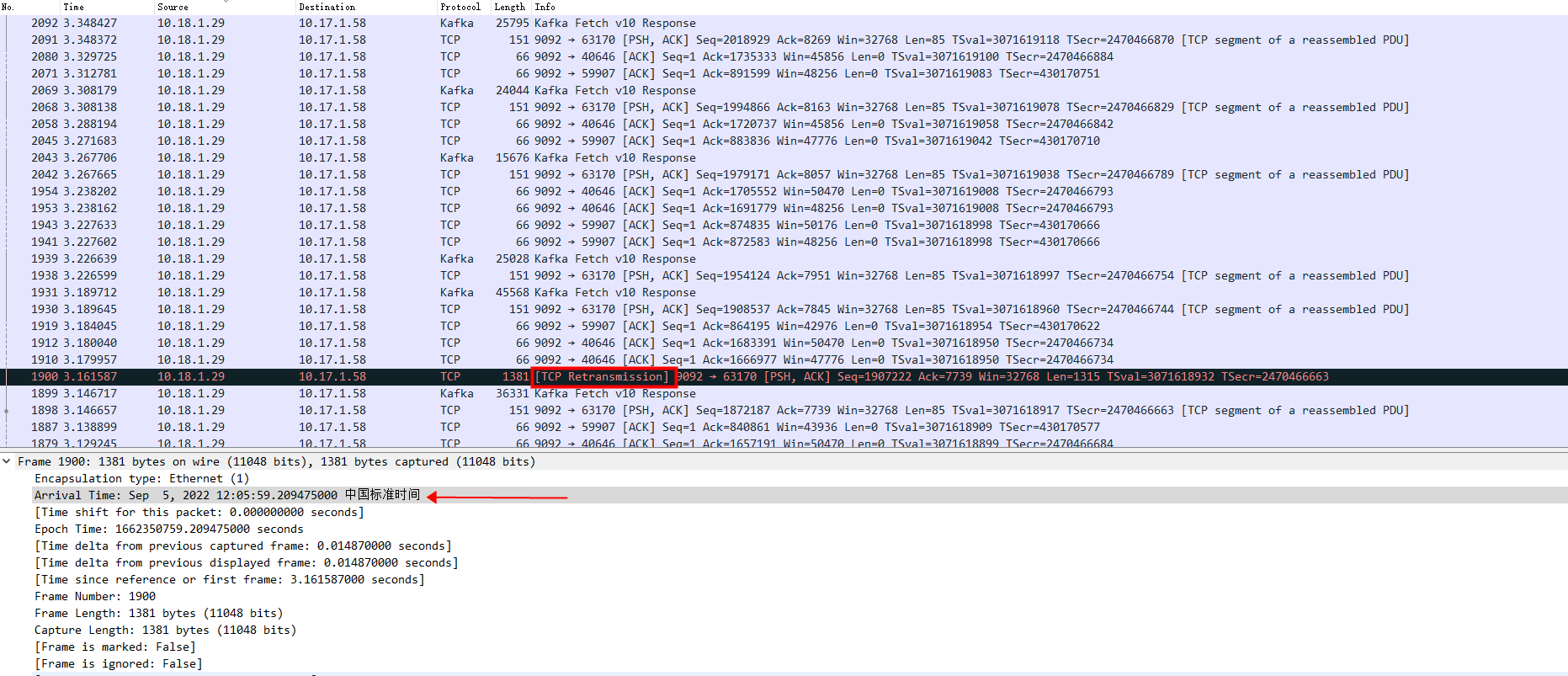
重传了2次
-
第一次重传
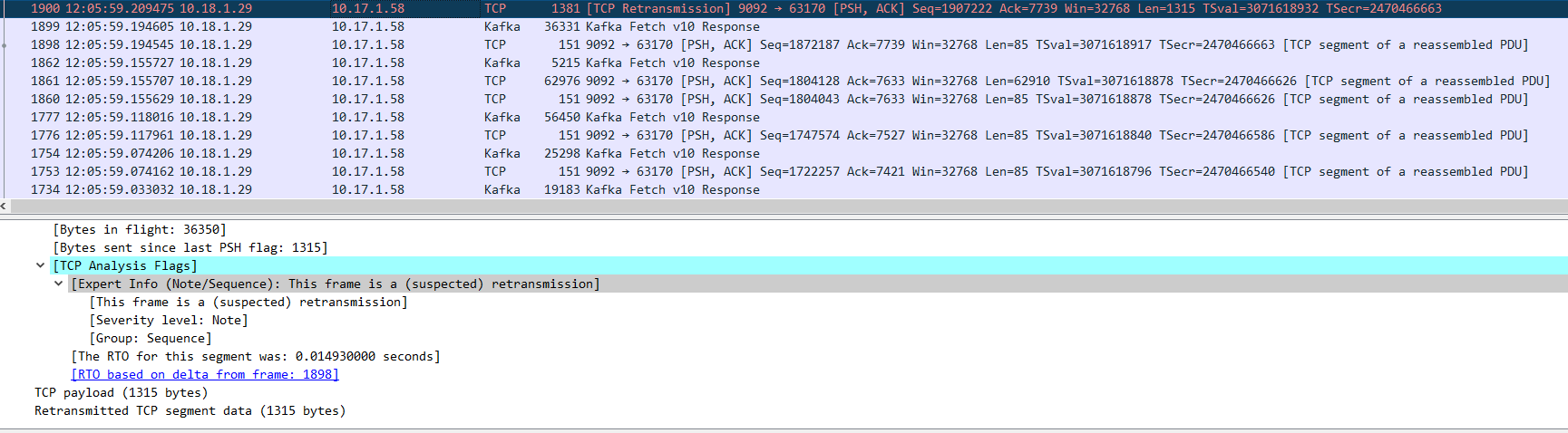
12:06:02 第二次重传
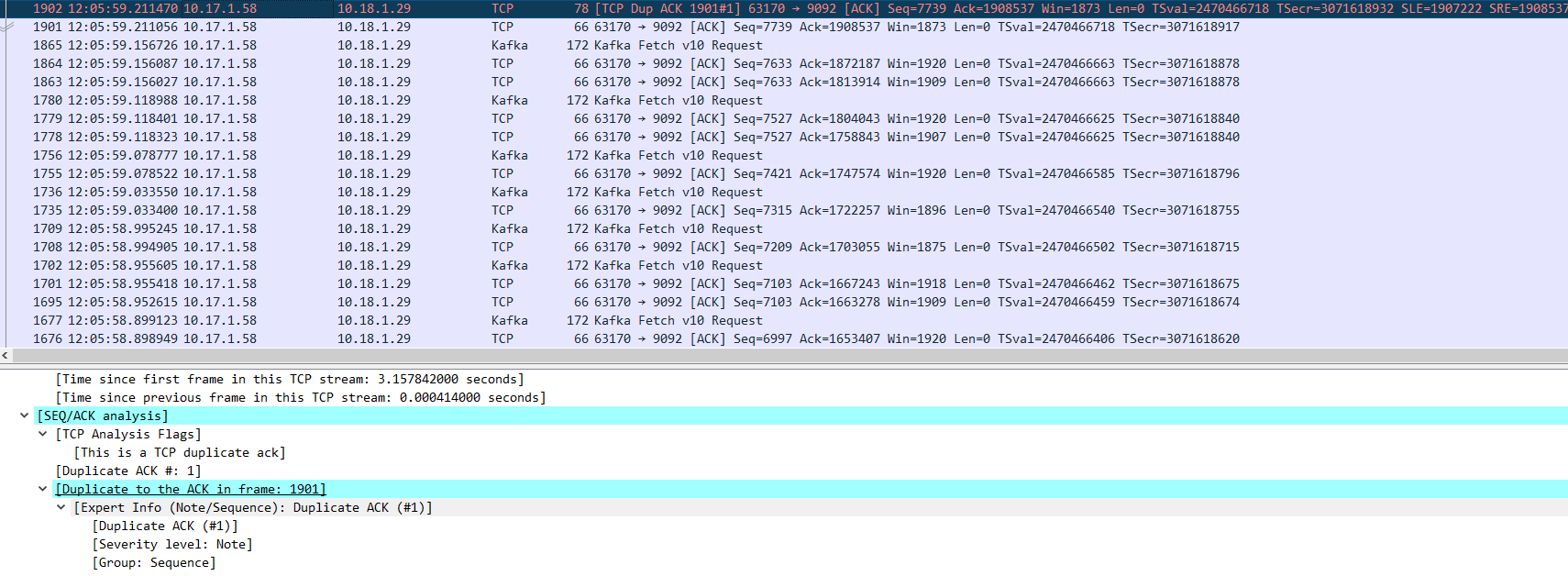
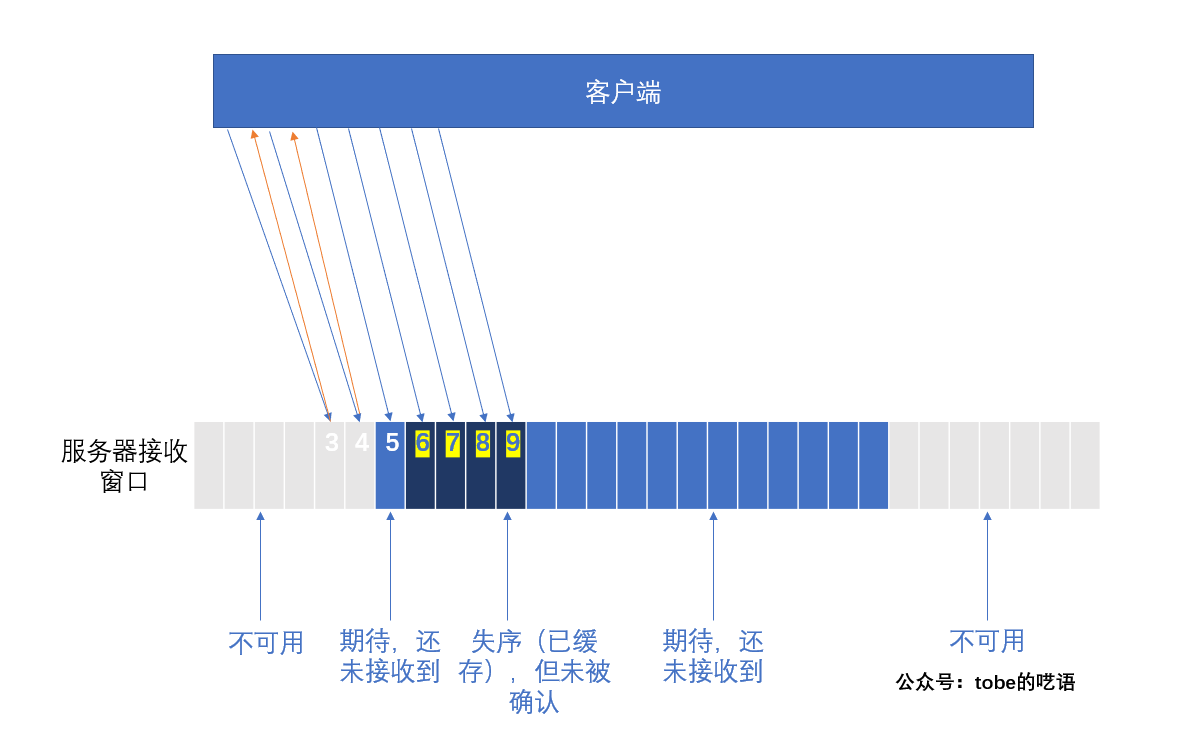
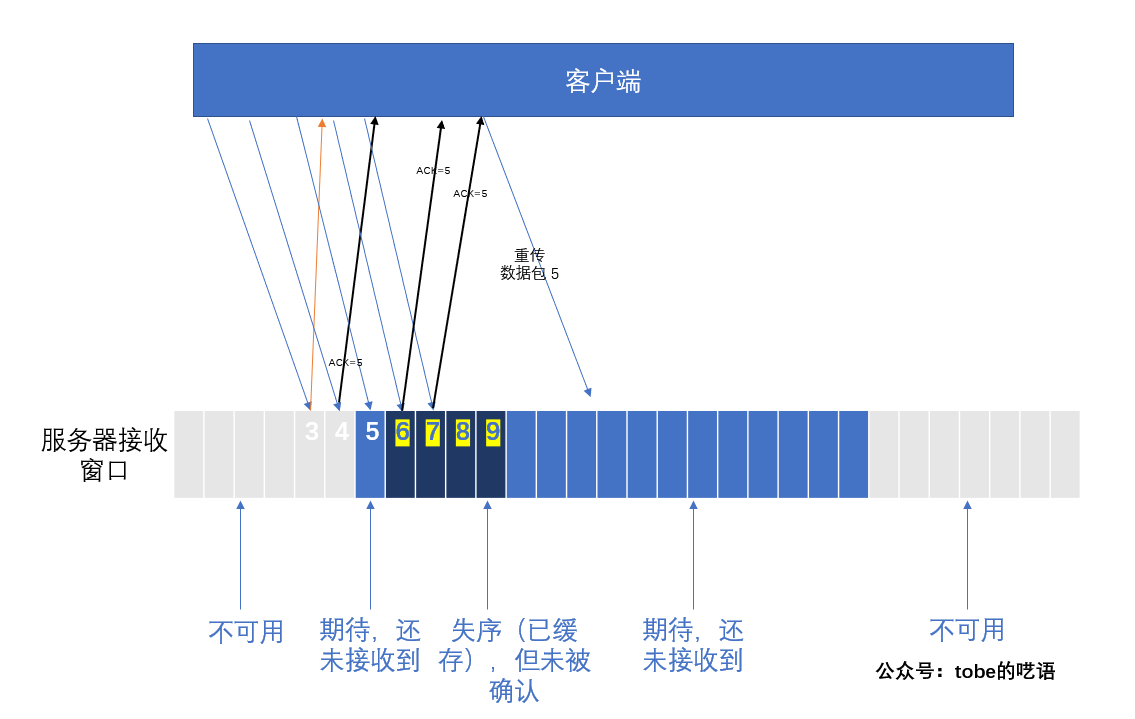
由于IP包的传输是无序的,所以接收方有可能先收到后发出的片段 (快速重传机制)
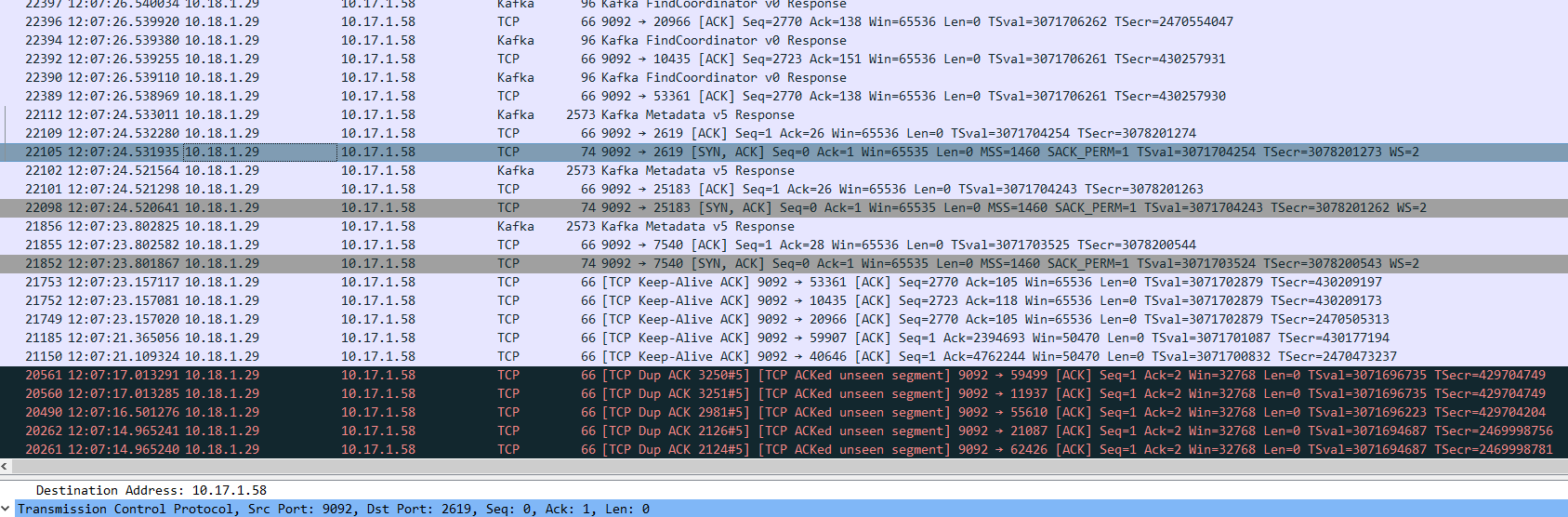
12:07:24 服务端回复syn+ack报文
-
超时重传
在请求包发出去的时候,开启一个计时器,当计时器达到时间之后,没有收到ACK,则就进行重发请求的操作,一直重发直到达到重发上限次数或者收到ACK。
-
快速重传
当接收方收到的数据包是不正常的序列号,那么接收方会重复把应该收到的那一条ACK重复发送,这个时候,如果发送方收到连续3条的同一个序列号的ACK,那么就会启动快速重传机制,把这个ACK对应的发送包重新发送一次。
问题:
-
为何该pod-3调度到node1,然后TCP建立连接这段时间内,其它2个pod会中断连接?连接kafka超时?
-
node2断电是不会影响node1已经建立了的TCP连接。
排查过程:
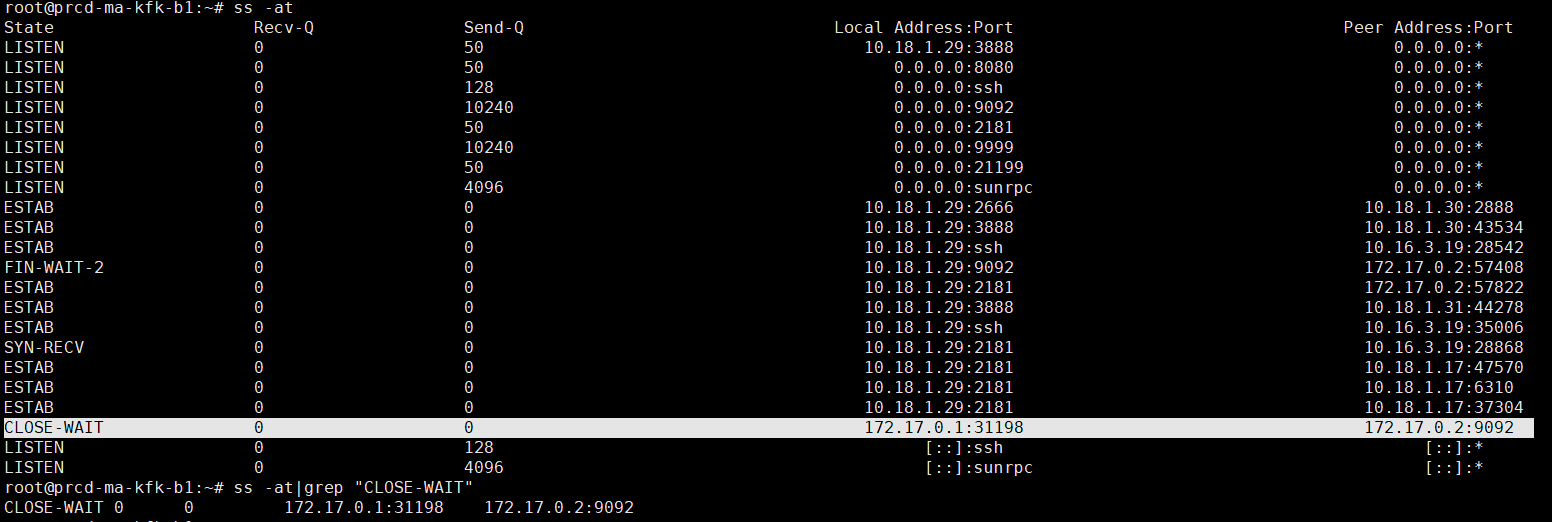
检查kafka的TCP连接状态,发现第一个kafka节点,docker网关与kafka容器长时间处于CLOSE-WAIT状态。
说明套接字是被动关闭的
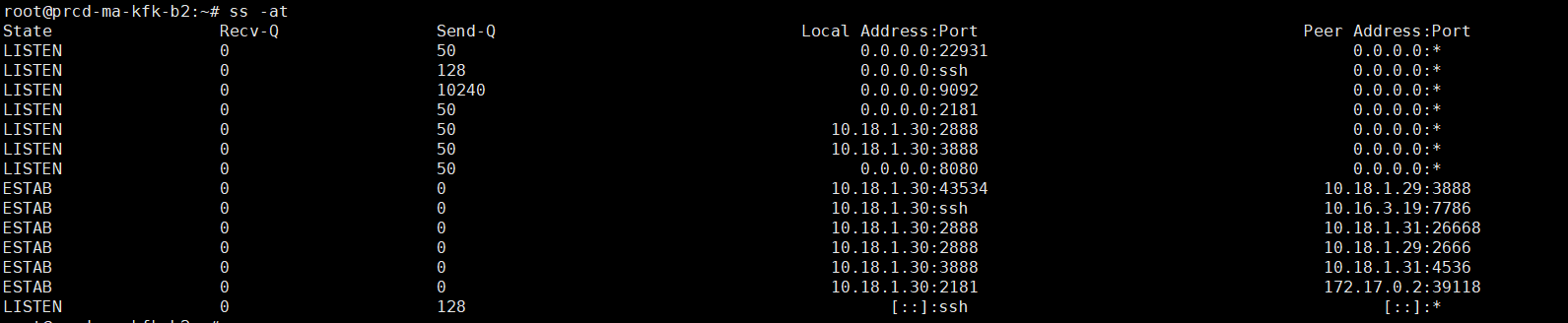
kafka的第二和第三个节点,均无异常

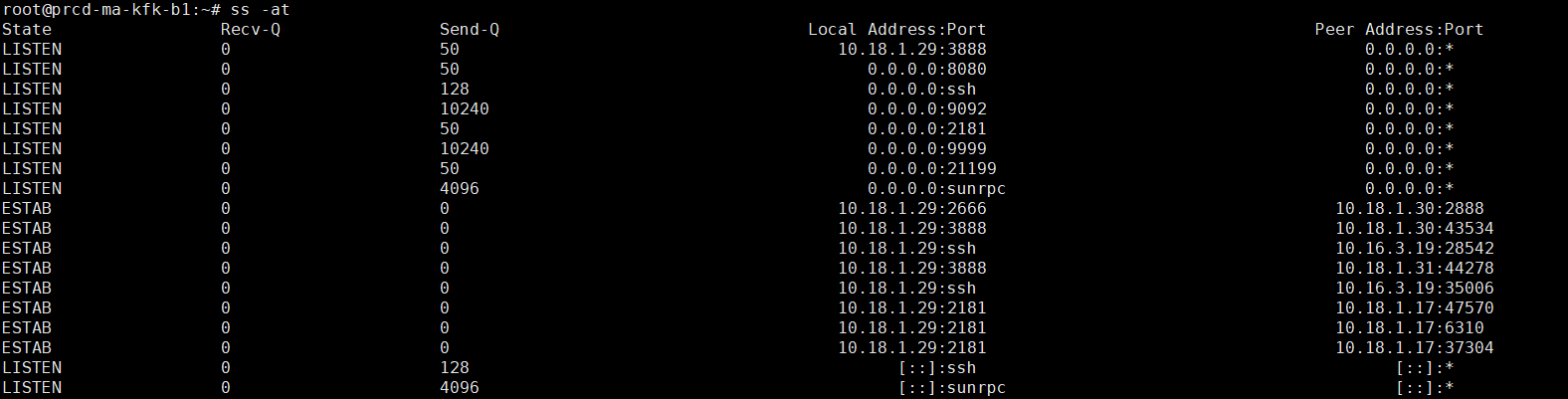
重启第一个节点的kafka容器,TCP连接状态恢复了正常。
再次测试故障转移
日志也没有刷超时的日志,监控显示也没有断连现象
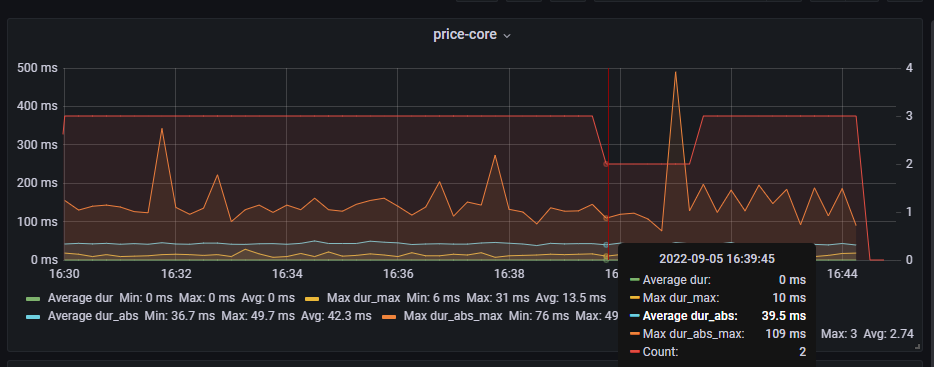
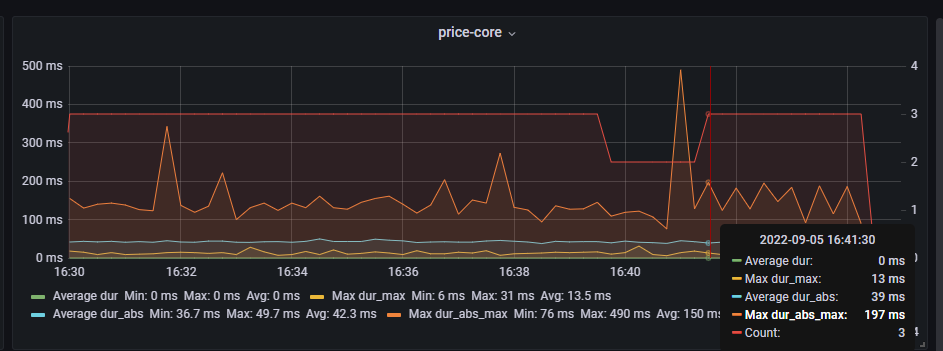
问题总结:
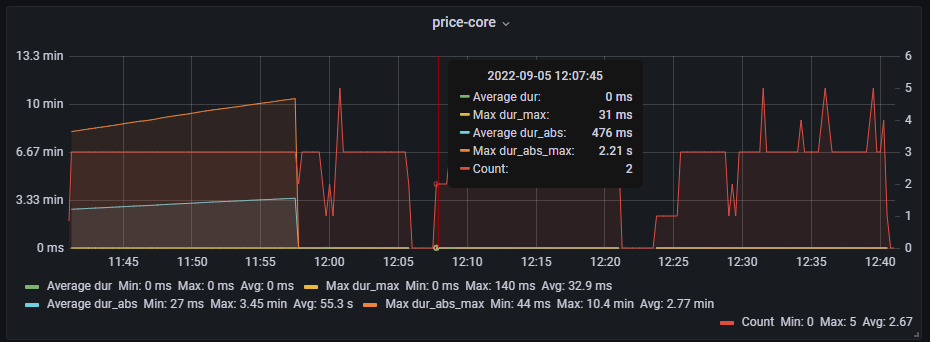
我们目的是要达到 2-3分钟 pod故障转移,期间不影响其它2个pod消费kafka。
由此得出,可以排除k8s集群网络或配置问题。定位出是kafka的重平衡机制,需要开发从代码入手
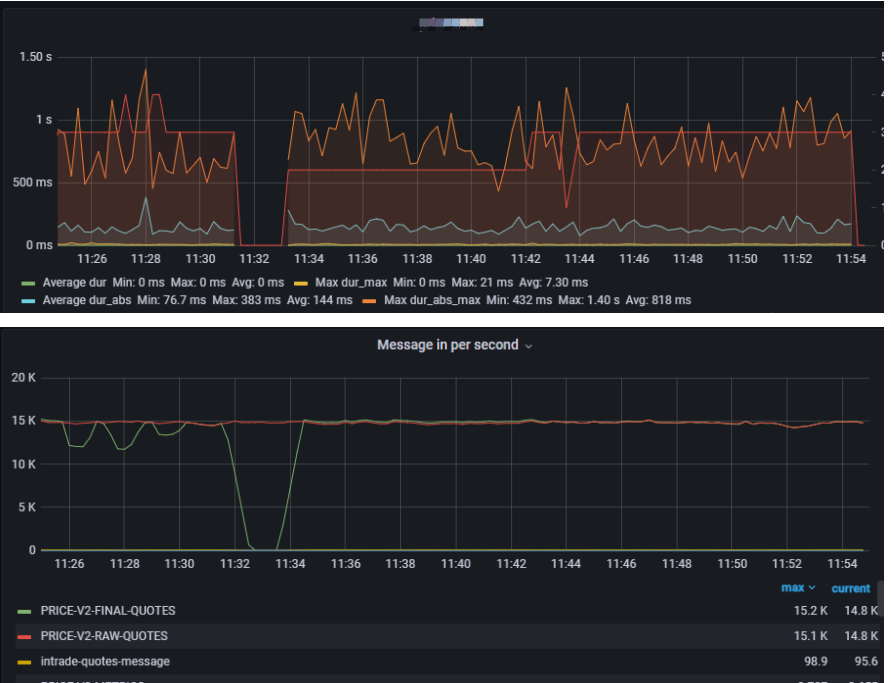
新问题: 前提是,测试之前,必须重启kafka第二个节点,否则就会出现上周的情况,其余2个pod都无法消费kafka。但是重启kafka第二个节点,监控显示全部中断2分钟。
上图kafka第一个节点可以看出,docker网关与kafka容器,TCP连接长期处于CLOSE-WAIT状态
关闭TCP连接,等待对方确认。
解决方法:
1. 重启kafka容器
2. kafka集群更换为二进制部署方式
经过几天时间的反复断电测试,发现问题并没有解决。
这是因为kafka的重平衡机制,导致其它2个pod也会断开连接。有2分钟的时间是不可用的

最后附上pod通信原理
1. 相同节点的Pod通信

2.不同节点的Pod通信,跨主机通信。网络插件起了nat转发作用,二次封装。

综上结论,可以排除k8s集群网络、组件问题,当pod调用kafka时,数据流为以下过程:

