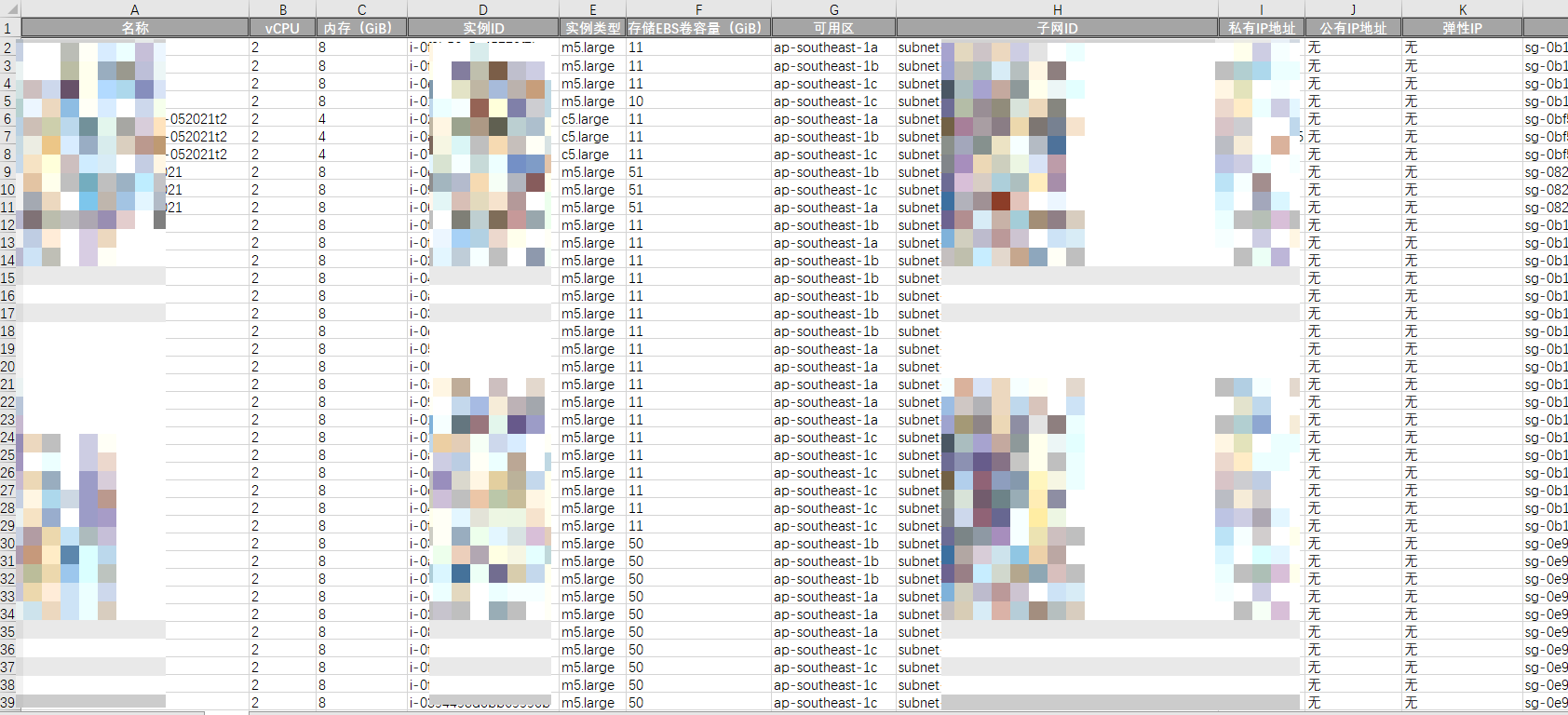
#一、实例和ebs挂载卷、自动伸缩的详细配置导出为json
aws ec2 describe-instances \
--filters "Name=instance-state-name,Values=running" \
--query 'Reservations[*].Instances[*].[InstanceId, InstanceType, Tags[?Key==`Name`].Value | [0], Placement.AvailabilityZone, SubnetId, PrivateIpAddress, PublicIpAddress, NetworkInterfaces[0].Association.PublicIp, BlockDeviceMappings[*].Ebs.{VolumeId:VolumeId}, SecurityGroups[*].GroupId, SecurityGroups[*].GroupName, KeyName, ImageId, IamInstanceProfile.Arn, Tags]' \
--output json > instances.json
aws ec2 describe-volumes \
--query "Volumes[*].{VolumeId:VolumeId, Size:Size}" \
--output json > volumes.json
aws autoscaling describe-auto-scaling-instances \
--query 'AutoScalingInstances[*].[InstanceId, AutoScalingGroupName]' \
--output json > asg_info.json
二、使用Python脚本将json内容,写入到excel表格里
import json
import csv
# 加载 instances.json 数据
with open('instances.json','r',encoding='utf-8') as file:
instances = json.load(file)
# 加载 volumes.json 数据
with open('volumes.json','r',encoding='utf-8') as file:
volumes = json.load(file)
# 加载 asg_info.json 数据
with open('asg_info.json','r',encoding='utf-8') as file:
asg_info = json.load(file)
# 创建一个字典以便快速查找卷大小
volume_size_dict = {volume['VolumeId']: volume['Size'] for volume in volumes}
# 创建一个字典以便快速查找ASG信息
asg_dict = {item[0]: item[1] for item in asg_info}
# 定义CSV头部(确保使用正确的字符集)
fields = [
'名称','vCPU','内存(GiB)','实例ID','实例类型','存储EBS卷容量(GiB)',
'可用区','子网ID','私有IP地址','公有IP地址','弹性IP','安全组ID','安全组名称','密钥名称',
'AMI ID','IAM角色','Auto Scaling 组名称','标签'
]
def filter_user_tags(tags):
"""过滤掉系统默认生成的标签,保留用户自定义的标签"""
if not tags:
return {}
# 系统默认标签的前缀列表
system_tag_prefixes = ['aws:','elasticbeanstalk:']
# 过滤逻辑
user_tags = {
tag['Key']: tag['Value']
for tag in tags
if not any(tag['Key'].startswith(prefix) for prefix in system_tag_prefixes)
}
return user_tags
# 准备写入CSV
with open('ec2_instances.csv','w',newline='',encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(fields)
# 遍历每个实例并写入CSV
for reservation in instances:
for instance in reservation:
# 解析每个实例的信息
instance_id = instance[0]
instance_type = instance[1]
name = instance[2]
availability_zone = instance[3]
subnet_id = instance[4]
private_ip_address = instance[5]
public_ip_address = instance[6]
elastic_ip = instance[7]
block_device_mappings = instance[8]
security_group_ids = ','.join(instance[9]) if instance[9] else ''
security_group_names = ','.join(instance[10]) if instance[10] else ''
key_name = instance[11]
ami_id = instance[12]
iam_instance_profile = instance[13]
tags = instance[14]
# 补充缺失字段(vCPU 和 内存设为空)
vcpu = ''
memory_gib = ''
# 计算EBS卷总大小
ebs_volume_size_total = sum(volume_size_dict.get(bdm['VolumeId'],0) for bdm in block_device_mappings if
isinstance(bdm,dict) and 'VolumeId' in bdm)
# 获取Auto Scaling组名称
auto_scaling_group_name = asg_dict.get(instance_id,'')
# 过滤用户自定义的标签
user_tags = filter_user_tags(tags)
user_tags_str = json.dumps(user_tags,ensure_ascii=False)
# 写入行
writer.writerow([
name, # 名称
vcpu, # vCPU
memory_gib, # 内存(GiB)
instance_id, # 实例ID
instance_type, # 实例类型
ebs_volume_size_total, # 存储EBS卷容量(GiB)
availability_zone, # 可用区
subnet_id, # 子网ID
private_ip_address, # 私有IP地址
public_ip_address, # 公有IP地址
elastic_ip, # 弹性IP
security_group_ids, # 安全组ID
security_group_names, # 安全组名称
key_name, # 密钥名称
ami_id, # AMI ID
iam_instance_profile, # IAM角色
auto_scaling_group_name, # Auto Scaling 组名称
user_tags_str # 用户自定义标签
])
最终结果展示: