
Kubernetes POD Unknown状态,节点失联引起微服务调用异常
初步分析:
1,从前端日志分析,请求已经流转到后端api网关,api网关上打印出{“code”:500,“message”:“Internal Server Error”,“traceId”:“ITLM4RE5-2419162-31983086”}"}。依此信息可以推断出响应该请求的后端服务出现异常。
2,检查对应的工作负载,发现有部分pod呈现Unkno状态。注意当前共有4个pod,3个正常,1个Unknow,其中Unknow的ip为:10.42.7.247。
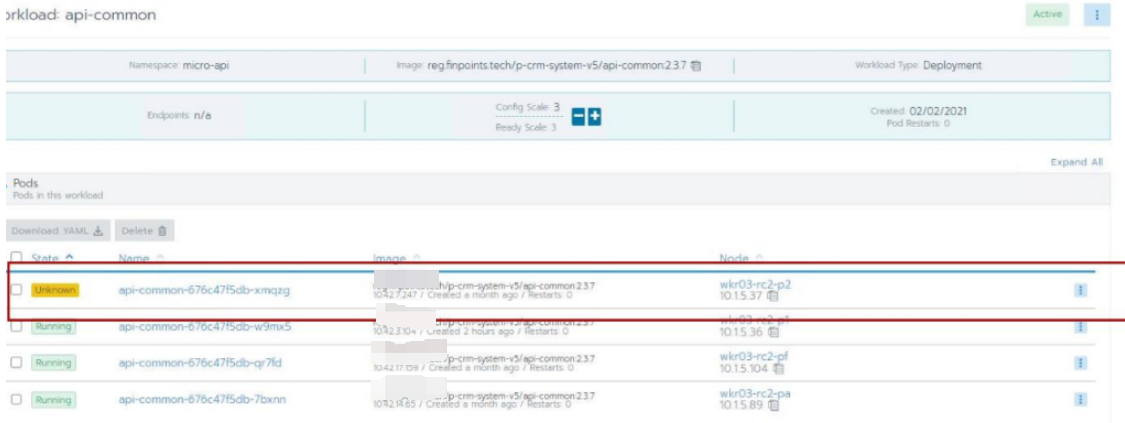
3,检查Nacos服务,注意注册服务有4个,与上面工作负载完全对应上。注意IP为10.42.7.247的节点对应pod状态为Unknow。
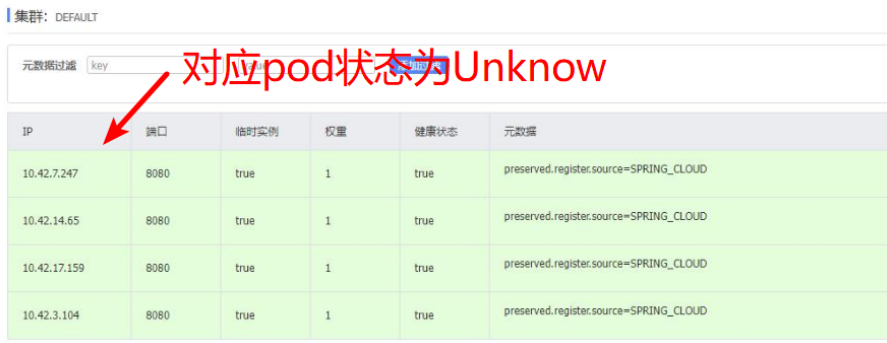
到此处,初步判断为k8s某个工作节点出现失联,导致网络不通。k8s问题转交甲方运维处理,改故障以得到解决。
根源分析:
A.从服务发现的原理分析,
- 后端微服务(服务提供方)按照15s/次的频率向nacos发送包括ip,端口等信息的心跳包,nacos如果超过30s(默认两个心跳周期)没有收取心跳就会删除这个pod实例。
- 网关(服务的调用方)从服务列表上获取一个ip,然后发起调用。
由于ip为10.42.7.247这个POD一直存在与Nacos服务列表上,可以推断出该pod节点一直正常的往nacos发送心跳,并维持的正常的服务运行。反之pod异常则导致心跳异常,naocs会在30s后删除该故障pod。
根据网关打印的日志可以推断出,pod服务正常,但是调用链路不通。再联想起rancher集群出现工作节点失联,怀疑失联节点只是如Rancher控制节点网络中断,失联工作节点上的服务依然正常运行。
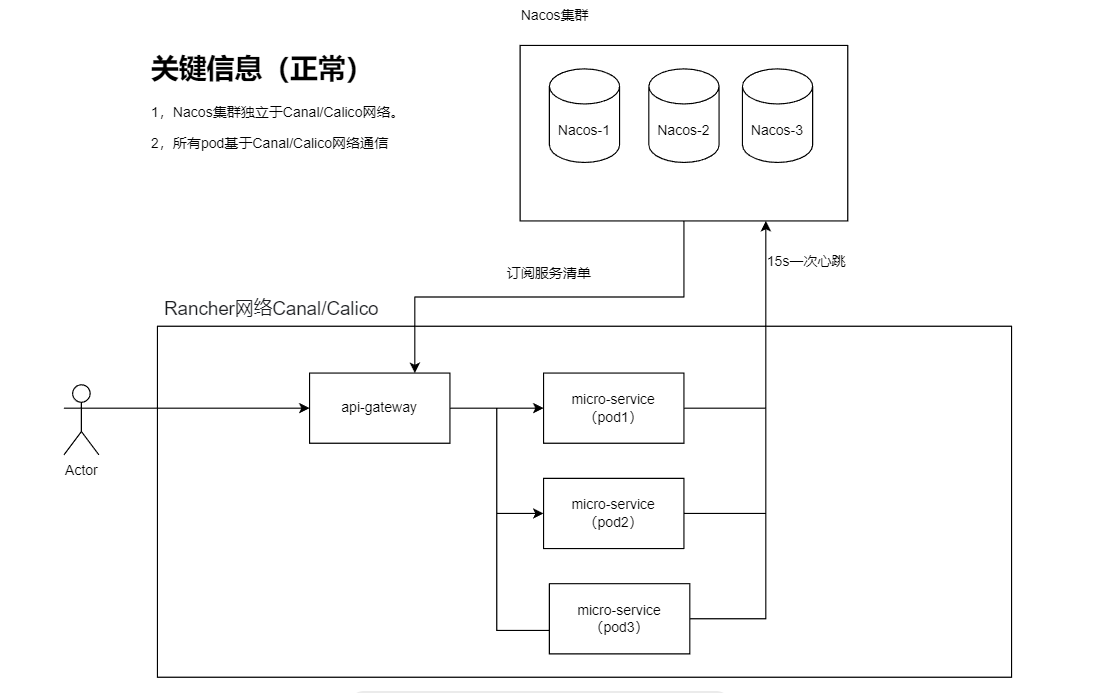
B.再次分析k8s网络情况,正常情况下,所有的pod节点均在rancher网络内部,nacos独立于rancher网络。
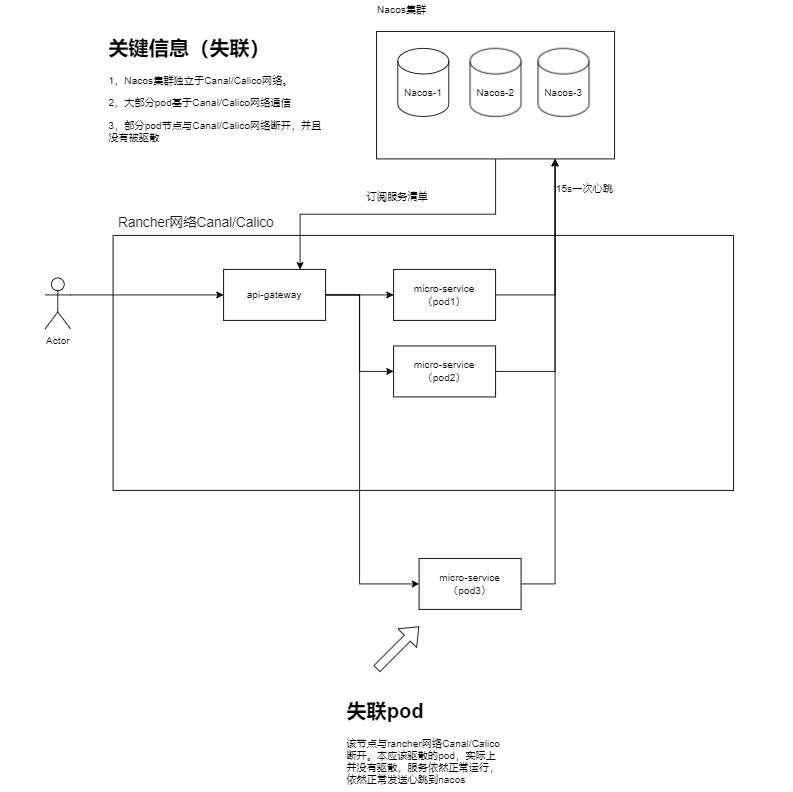
推测失联情况下网络,失联的工作节点上的全部pod均与rancher网络断开,并且本应该驱散的pod,实际上还在正常运行,并且正常的正常的向nacos发送心跳包。
Pod 一直处于 Unknown 状态,通常是节点失联,没有上报状态给 apiserver,到达阀值后 controller-manager 认为节点失联,而k8s不会因为节点失联而删除其上正在运行的 Pod,而是将其标记为 Terminating 或 Unknown 状态。
可能原因:
- 节点高负载导致无法上报
- 节点宕机
- 节点被关机
- 网络不通
根治措施
- 由运维负责处理基础rancher的基础设施稳定性,保证工作节点稳定不适量,或者失联后能够正常的驱散pod节点,销毁失联工作节点上所有微服务。
- 迁移nacos注册中心到rancher集群,使得nacos服务同在rancher网络内部。所有服务注册使用rancher内部通信。
- 检查集群网络插件是否异常
- 适当调整kubelet参数: node-status-update-frequency: 10s (默认 10s) 达到该阀值后,controller-manager 认为节点失联
- 如果pod状态长时间没有恢复,则需要手动删除Unknown状态的pod
- 更换集群部署方式
