
JuiceFS 客户端性能压测方法:顺序吞吐、4K 随机读写与 NFS 对照分析
存储压测最容易踩的坑,是把不同测试口径的数字放在一张表里直接排名。对 JuiceFS 这类“客户端 + 元数据引擎 + 对象存储”的架构来说,顺序读写、随机读写、延迟约束、客户端缓存、对象存储回源、元数据压力都会影响结果。
本文只讨论客户端视角的压测方法和可公开汇总数据。原始终端截图不会直接公开;下文复用的是从项目报告中提取后裁剪脱敏的客户端 fio 结果片段,已去掉主机名、挂载路径、命令 prompt 和工具栏。

1. 为什么要从客户端视角看
业务真正感知到的是客户端返回的吞吐、IOPS 和延迟,而不是存储集群后台某个监控面板上的聚合值。服务端聚合带宽可以证明后端集群有能力承载流量,但不能直接说明单个训练任务、单个数据加工任务或单个挂载点的体验。
客户端视角要回答 4 个问题:
- 大块顺序写能否支撑 checkpoint、归档和大文件生成。
- 大块顺序读能否支撑训练样本扫描、模型权重加载和批处理读取。
- 4K 随机写能否承受小文件、索引、日志和元数据密集写入。
- 4K 随机读能否承受小样本、索引查询和随机访问。
如果只看顺序读,很容易高估系统能力;如果只看 4K 随机写,又会低估对象存储后端在大文件场景里的价值。
2. 测试矩阵设计
建议至少保留两个测试矩阵。
第一组是吞吐与 IOPS 基线:
| 场景 | 块大小 | 访问模式 | 观察指标 |
|---|---|---|---|
| 顺序写 | 1M | write | MB/s、平均延迟、错误 |
| 顺序读 | 1M | read | MB/s、平均延迟、缓存命中 |
| 随机写 | 4K | randwrite | IOPS、平均延迟、p95/p99 |
| 随机读 | 4K | randread | IOPS、平均延迟、p95/p99 |
第二组是延迟受控测试。它不追求最大吞吐,而是把延迟压在业务可接受范围内,观察在该约束下能给多少吞吐或 IOPS。
| 场景 | 目标 | 适用业务 |
|---|---|---|
| 1M 顺序写延迟受控 | 降低写入尾延迟 | checkpoint、归档 |
| 1M 顺序读延迟受控 | 稳定大文件读取 | 样本扫描、权重加载 |
| 4K 随机写延迟受控 | 控制小写抖动 | 小文件生成、索引写入 |
| 4K 随机读延迟受控 | 控制随机访问时延 | 小样本、索引读取 |
压测命令要固定并记录 bs、iodepth、numjobs、runtime、direct、文件大小、文件数量、挂载参数和缓存状态。否则同一套系统不同轮次之间也不能直接比较。
3. JuiceFS 客户端结果摘要
以下数据来自客户端侧汇总表,单位已统一。过程截图中的局部值属于不同轮次或不同参数组合,公开稿以汇总表为准。
| 测试类型 | 场景 | 指标 | 客户端观测值 | 平均延迟 |
|---|---|---|---|---|
| 带宽测试 | 1M 顺序写 | MB/s | 86.6 | 46.9ms |
| 带宽测试 | 1M 顺序读 | MB/s | 5215 | 1.6ms |
| 性能测试 | 4K 随机写 | IOPS | 2485 | 6.3ms |
| 性能测试 | 4K 随机读 | IOPS | 55237 | 0.5ms |
延迟受控轮次如下:
| 测试类型 | 场景 | 指标 | 客户端观测值 | 平均延迟 |
|---|---|---|---|---|
| 延迟测试 | 1M 顺序写 | MB/s | 97.6 | 21.4ms |
| 延迟测试 | 1M 顺序读 | MB/s | 5258 | 1.5ms |
| 延迟测试 | 4K 随机写 | IOPS | 1286 | 4.1ms |
| 延迟测试 | 4K 随机读 | IOPS | 27543 | 0.5ms |
这组结果的第一结论不是“某个数字绝对好或坏”,而是读写画像很清楚:顺序读和随机读表现更突出,写入路径更受对象上传、元数据提交、flush、缓存策略和后端写入能力影响。
3.1 JuiceFS 客户端截图
以下截图来自项目报告中的客户端 fio 结果,已做公开版裁剪,只保留测试结果区域。
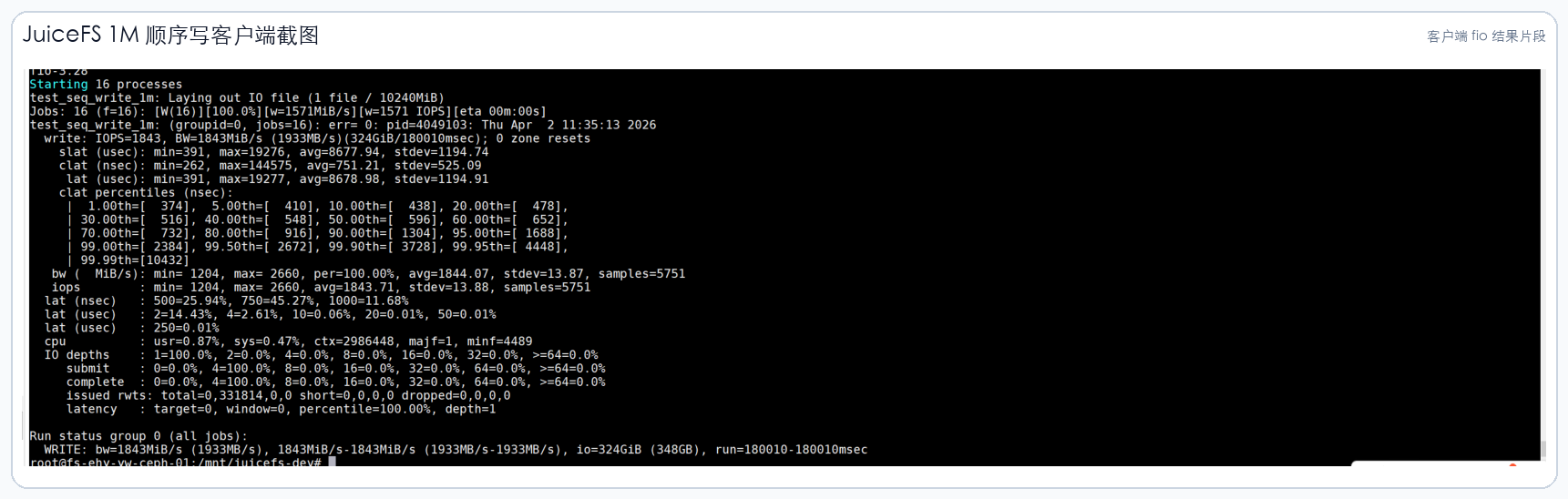
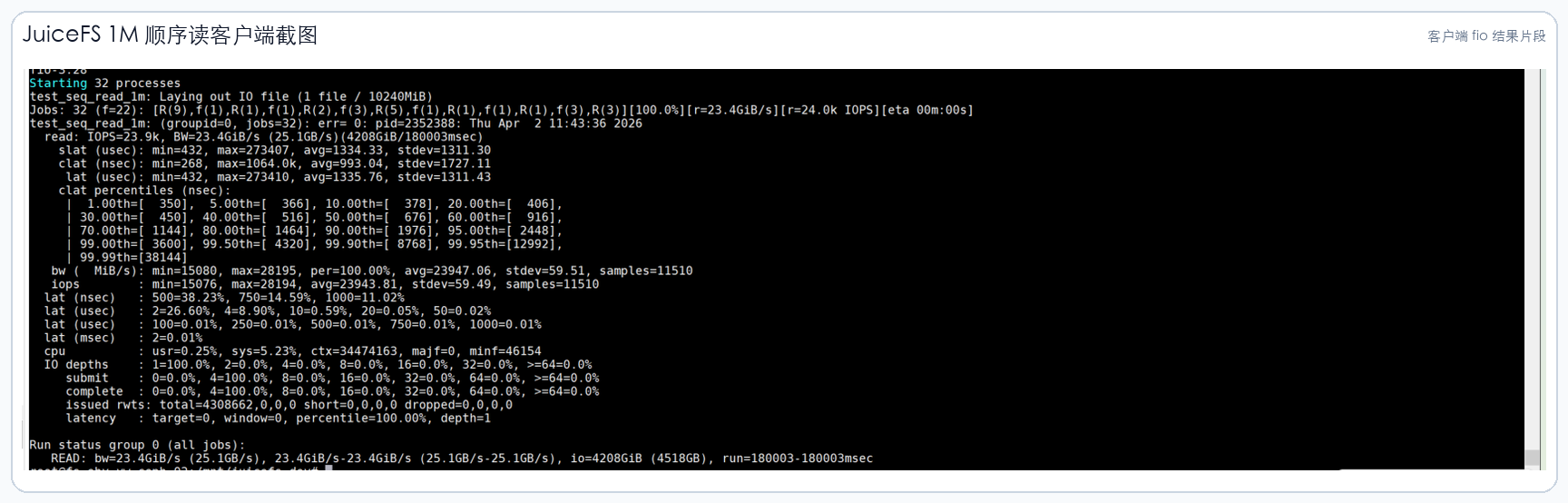
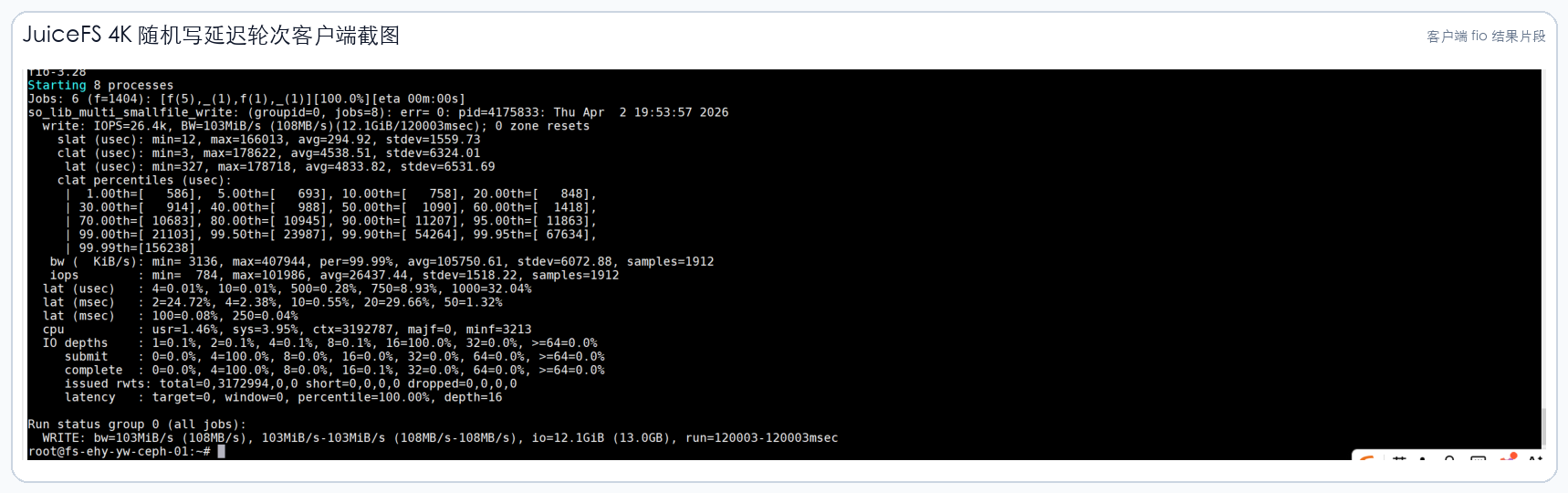
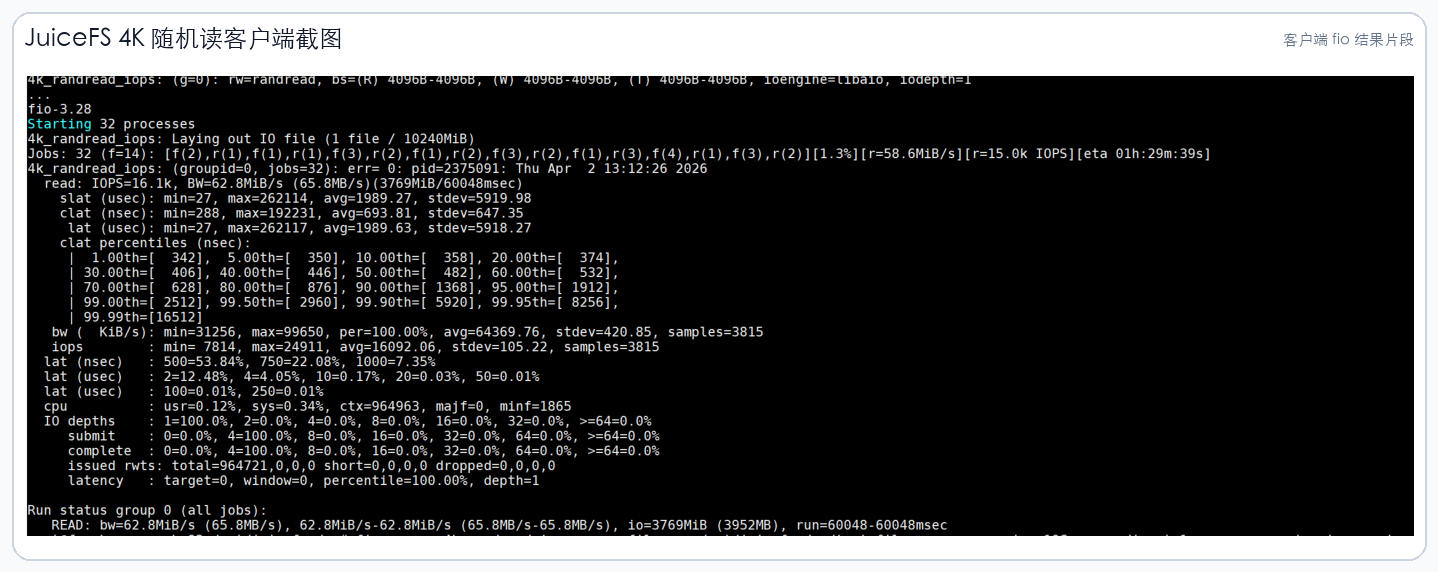
4. NFS 客户端对照结果
为了避免跨口径误读,这里只放物理客户端汇总表中可以公开表达的 NFS 客户端观测值,不引入服务端聚合截图。
| 测试类型 | 场景 | 指标 | 客户端观测值 | 平均延迟 |
|---|---|---|---|---|
| 带宽测试 | 1M 顺序写 | MB/s | 104 | 20ms |
| 带宽测试 | 1M 顺序读 | MB/s | 4515 | 1.85ms |
| 性能测试 | 4K 随机写 | IOPS | 885 | 8.9ms |
| 性能测试 | 4K 随机读 | IOPS | 70.5k | 2.7ms |
延迟受控轮次如下:
| 测试类型 | 场景 | 指标 | 客户端观测值 | 平均延迟 |
|---|---|---|---|---|
| 延迟测试 | 4K 随机写 | IOPS | 1286 | 4.1ms |
| 延迟测试 | 4K 随机读 | IOPS | 70.6k | 1.8ms |
这张表只能作为同类测试项的参考,不能扩展成“所有场景下 NFS 与 JuiceFS 的绝对优劣”。NFS 的实现方式、服务端导出参数、客户端数量、缓存状态、网络路径和后端磁盘都会改变结果。
4.1 为什么加一层 NFS 后会变慢
本次 NFS 口径里,客户端不是直接访问后端分布式存储能力,而是先访问 NFS 导出层,再由 NFS 服务端访问后端存储。链路从“客户端并发访问存储后端”变成了“客户端 -> NFS 服务端 -> 后端存储”,多了一次协议转换、一次网络转发和一层服务端调度。
这层 NFS 服务端会变成明显的收敛点。即使后端存储集群具备更高聚合带宽,客户端看到的吞吐也会受 NFS 服务端 CPU、内存、网卡、内核 NFS 线程、导出参数、页缓存、单连接/多连接行为和后端挂载性能限制。换句话说,后端有多强,不等于经过 NFS 导出后客户端就能吃满。
写入场景尤其容易被放大。NFS 需要处理客户端请求、权限检查、锁、属性更新、写入提交和缓存一致性;如果导出配置偏同步、服务端后端写入延迟偏高,1M 顺序写和 4K 随机写都会被服务端等待链路拖慢。小块随机写还会进一步放大 RPC 次数和元数据更新次数,所以随机写 IOPS 往往比直连或客户端原生并发路径更难看。
读取场景也不是总能靠缓存解决。热数据可能被 NFS 服务端页缓存加速,但冷读、跨客户端读、随机读和缓存失效后仍要回到后端存储。多客户端并发读取时,NFS 服务端既要承担网络出口,又要承担后端读取和缓存管理,很容易从“共享入口”变成“共享瓶颈”。
因此,这里看到的 NFS 性能偏低,并不是简单说明“NFS 协议一定差”,而是说明在本项目这种二次导出链路下,NFS 更适合作为兼容性入口或少量通用共享目录,不适合作为高并发 AI 数据面主路径。AI 训练、样本扫描、checkpoint 和大量小文件读写,应该优先让客户端直接接入 JuiceFS/CephFS/对象存储网关等能横向扩展的数据路径。
4.2 NFS 客户端截图
以下截图同样来自项目报告中的物理客户端 fio 结果,已做公开版裁剪。它们用于证明对照数据的来源,不引入服务端监控聚合图。
5. 如何解释这组数据
JuiceFS 顺序读表现较好,通常来自对象存储并发读取、客户端 buffer、预读和缓存的组合收益。读多写少的数据集、模型权重、训练样本扫描更容易发挥这类优势。
JuiceFS 写入要经历客户端 buffer、对象存储上传、元数据提交和 flush 过程。对于小文件随机写,写入延迟更容易受对象存储回写、元数据压力和文件碎片影响。大量小文件写入时,不要只调大并发,还要观察 Redis 延迟、RGW 上传延迟、客户端 buffer 是否拥塞。
NFS 对照结果则说明,给后端存储再包一层通用文件共享入口,会牺牲一部分横向扩展能力。它能降低客户端接入复杂度,但也把并发、缓存、锁和网络出口集中到 NFS 服务端,适合通用共享和兼容性场景,不适合把高并发训练数据面全部压在这一层。
--prefetch 和 --max-readahead 对顺序读、局部随机读有帮助,但也可能引入读放大。读取稀疏大文件时,预取过大反而会浪费对象存储带宽。
--cache-size 可以提升重复读取和随机读体验,但本地缓存不等于端到端数据保护。对缓存盘可靠性敏感的场景,要评估 --verify-cache-checksum 等完整性策略。
--writeback 能改善某些小文件写入体验,但会把数据可靠性压力转移到本地缓存盘。关键数据、跨节点共享和生产强一致场景不要轻易启用。
6. 面向 AI 业务的映射
训练数据集通常以读为主。如果数据集已经固化,可以使用缓存盘、预热和较大的 readahead 提高吞吐。此时重点观察顺序读、随机读、cache hit、对象存储回源带宽。
checkpoint 是大块写入,对象存储写带宽、flush 延迟和写入并发更关键。此时要重点观察 1M 或更大块顺序写、尾延迟、失败重试和写入完成后的跨客户端可见性。
小文件样本和索引会放大元数据压力。此时 4K 随机读写只是一个近似入口,还要补充真实目录层级、文件数量、文件大小分布和并发客户端数。
日志、临时文件和中间产物不一定适合全部放入共享文件系统。高频短生命周期数据可以考虑本地盘、临时卷或专门的缓存层,最终产物再落 JuiceFS。
7. 小结
JuiceFS 压测要从“客户端实际体验”出发,而不是追求单个最大数字。顺序读、顺序写、随机读、随机写、延迟受控轮次要分别解释。
参考资料:
- JuiceFS Benchmark and Profiling
- JuiceFS Cache
- JuiceFS Command Reference
- JuiceFS Fault Diagnosis and Analysis