
Containerd介绍
containerd-xxx-linux-amd64.tar.gz(containerd)
cri-containerd-xxx-linux-amd64.tar.gz(containerd + runc)
cri-containerd-cni-xxx-linux-amd64.tar.gz(containerd + runc + cni)
Containerd不能直接操作容器,需要通过runc来运行容器
默认Containerd管理的容器仅有lo网络(无法访问容器之外的网络),如果需要访问容器之外的网络则需要安装CNI网络插件
CNI(Container Network Interface) 是一套容器网络接口规范,用于为容器分配ip地址,通过CNI插件Containerd管理的容器可以访问容器之外的网络
CTR是containerd的一个客户端工具
CRICTL是 CRI 兼容的容器运行时命令行接口,可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序
OCI 介绍
Open Container Initiative Runtime Specification 指定容器的配置、执行环境和生命周期
因此执行的命令是 runc spec
OCI(Open Container Initiative,开放容器计划),是在 2015 年由 Docker、CoreOS 等公司共同成立的项目,并由 Linux 基金会进行管理,致力于 container runtime 标准的制定和 runc 的开发等工作。
所谓 container runtime(runc),主要负责的是容器的生命周期的管理。OCI 主要分为容器运行时规范(runtime-spec) 和镜像规范(image-spec) 两部分,runtime-spec 标准对容器的创建、删除、查看、状态等操作进行了定义,image-spec 对镜像格式、打包(Bundle)、存储等进行了定义。
runc 介绍
runc,是由 Docker 贡献的对于 OCI 标准的一个参考实现,是一个可以用于创建和运行容器的 CLI(command-line interface) 工具。runc 直接与容器所依赖的 Cgroup/OS 等进行交互,负责为容器配置 Cgroup/namespace 等启动容器所需的环境,创建启动容器的相关进程。
为了兼容 OCI 标准,Docker 也做了架构调整。将容器运行时相关的程序从 Docker daemon 剥离出来,形成了containerd。containerd 向 Docker 提供运行容器的 API,二者通过 gRPC 进行交互。containerd 最后会通过 runc 来实际运行容器。
CRI 介绍
CRI(Container Runtime Interface,容器运行时接口)是 K8s 定义的一组与容器运行时进行交互的接口,用于将 K8s 平台与特定的容器实现解耦。在 K8s 早期的版本中,对于容器环境的支持是通过 Dockershim(hard code) 方式直接调用 Docker API 的,后来为了支持更多的容器运行时和更精简的容器运行时,K8s 在遵循 OCI 基础上提出了CRI。
总结:
cri 是k8s 提的, containerd 是从docker daemon 分离出来的, 其实最后containerd 也是调用runc创建容器。
调用链路:

容器刨析+CNI:
容器之间通过多种网络插件flannel、calico等,基于CNI网络接口规范调用接口进行通信
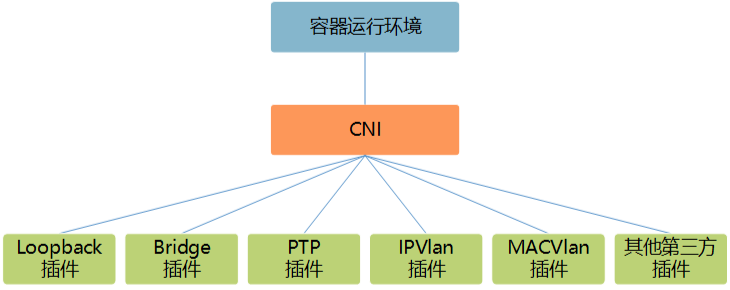
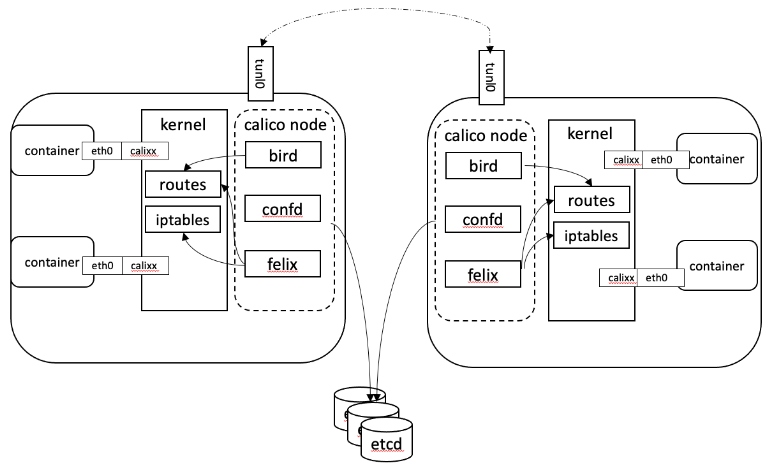
CNI 的调用流程
首先 CRI 规范要走containerd,然后 containerd 要调用 OCI ,这里先简单看下 containerd 的源码的一小部分:
// github.com/containerd/containerd/pkg/cri/server/sandbox_run.go
func (c *criService) RunPodSandbox(ctx context.Context, r *runtime.RunPodSandboxRequest) (_ *runtime.RunPodSandboxResponse, retErr error) {
// ......
// Create initial internal sandbox object.
sandbox := sandboxstore.NewSandbox(
sandboxstore.Metadata{
ID: id,
Name: name,
Config: config,
RuntimeHandler: r.GetRuntimeHandler(),
},
sandboxstore.Status{
State: sandboxstore.StateUnknown,
},
)
// Ensure sandbox container image snapshot.
image, err := c.ensureImageExists(ctx, c.config.SandboxImage, config)
// ......
ociRuntime, err := c.getSandboxRuntime(config, r.GetRuntimeHandler())
// ......
podNetwork := true
// ......
if podNetwork {
// ......
var netnsMountDir = "/var/run/netns"
// ......
sandbox.NetNS, err = netns.NewNetNS(netnsMountDir)
sandbox.NetNSPath = sandbox.NetNS.GetPath()
// ......
if err := c.setupPodNetwork(ctx, &sandbox); err != nil {
return nil, errors.Wrapf(err, "failed to setup network for sandbox %q", id)
}
// ......
}
// ......
opts := []containerd.NewContainerOpts{
containerd.WithSnapshotter(c.config.ContainerdConfig.Snapshotter),
customopts.WithNewSnapshot(id, containerdImage, snapshotterOpt),
containerd.WithSpec(spec, specOpts...),
containerd.WithContainerLabels(sandboxLabels),
containerd.WithContainerExtension(sandboxMetadataExtension, &sandbox.Metadata),
containerd.WithRuntime(ociRuntime.Type, runtimeOpts)}
container, err := c.client.NewContainer(ctx, id, opts...)
// ......
if err = c.setupSandboxFiles(id, config); err != nil {
return nil, errors.Wrapf(err, "failed to setup sandbox files")
}
// ......
return &runtime.RunPodSandboxResponse{PodSandboxId: id}, nil
}
剔除掉了一些部分,只留下有用的(凑合能看懂的)部分。其主要逻辑就是:
- 创建一个 sandbox 结构体,里面描述了这个 sandbox 的各种信息
- 拉它的镜像
- 生成 oci 的 runtime,这里的 oci 大部分情况下就是 runc,当然也可以使用其他 oci
- 然后生成 netns,设置网络
- 把这些网络塞给 sandbox
- 设置 sandbox 的文件系统
- 用 OCI 拉起 pod
首先 sandbox 是 CRI 规范中的一环,CRI 规范规定了容器启动之前必须要有个 sandbox。sandbox 可以理解为沙箱,这个沙箱其实就是为了整合网络资源和存储资源,K8S集群里pod里面的根容器。
假设只使用容器这个概念,那么每启动一个容器,就要给它设置网络资源,以及设置存储资源,如果该容器挂了十次,那么重启十次就要重复设置十次网络以及十次存储资源,那有没有更好的方法能让容器挂掉重启之后不那么频繁的创建资源呢?
所以就是把一个或多个容器集成一个 Pod,让在同一个 Pod 里的多个容器去共享这一个 Pod 中的网络资源和存储资源(cgroup 之类的资源不共享),这样容器挂了十次,但是只要pod不挂不删除,那它里面的网络资源或者存储资源就还在,下次新创建的容器只需要简单地加入进去就可以享用资源了。
其实 sandbox 就是网络资源以及存储资源的承载,实际上这个 sandbox 就是一个容器,它在 k8s 里被叫做 “pause”,它是一段 c 代码,就是单纯地死循环 pause 方法,该方法是让程序直接陷入睡眠,也不消耗 cpu。
也就是说,这 pause 是一个极度稳定的一条进程,k8s 把这个 pause 容器作为一个 pod 启动之前的 sandbox,具备启动快切稳定的特点,然后把创建的网络资源存储资源等挂到这个 pause 容器里头,然后等 pod 中的其他容器启动后再和这个 pause 共享网络和存储,这样就避免了重复创建网络和存储资源了。(这就是根容器!)
CNI 网络插件被调用的过程:
func main() {
// ......
netdir := os.Getenv(EnvNetDir)
// ......
netconf, err := libcni.LoadConfList(netdir, os.Args[2])
// ......
var cniArgs [][2]string
args := os.Getenv(EnvCNIArgs)
if len(args) > 0 {
cniArgs, err = parseArgs(args)
// ......
}
ifName, ok := os.LookupEnv(EnvCNIIfname)
if !ok {
ifName = "eth0"
}
netns := os.Args[3]
netns, err = filepath.Abs(netns)
// ......
// Generate the containerid by hashing the netns path
s := sha512.Sum512([]byte(netns))
containerID := fmt.Sprintf("cnitool-%x", s[:10])
cninet := libcni.NewCNIConfig(filepath.SplitList(os.Getenv(EnvCNIPath)), nil)
rt := &libcni.RuntimeConf{
ContainerID: containerID,
NetNS: netns,
IfName: ifName,
Args: cniArgs,
CapabilityArgs: capabilityArgs,
}
switch os.Args[1] {
case CmdAdd:
result, err := cninet.AddNetworkList(context.TODO(), netconf, rt)
if result != nil {
_ = result.Print()
}
exit(err)
case CmdCheck:
err := cninet.CheckNetworkList(context.TODO(), netconf, rt)
exit(err)
case CmdDel:
exit(cninet.DelNetworkList(context.TODO(), netconf, rt))
}
}
该文件主要流程较为简单:
- 获取一些环境变量
- 获取网络插件配置(从 /etc/cni/net.d)
- 获取网卡名(这个网卡名会交给 CNI 网络插件, 网络插件中会把这个名字作为每个 pod 里的默认网卡, 默认就叫 eth0)
- 获取 netns(这个就是在 containerd 中生成的属于这条 pod 的网络命名空间, 不过在 cnitool 中是从命令行参数中获取的, 想通过 cnitool 测试网络插件就得自己先创建一个 netns 然后作为参数传进来)
- 生成 containerID
- 生成容器运行时的相关信息
- 根据命令行参数来判断,调用 Add 还是 Check 还是 Del,这里以 Add 为例,cni 这个 repo 的主要代码的 AddNetworkList 方法(在 CRI 中也会调用这个 repo 的这个方法)
- 可以看到这个 AddNetworkList 接收的参数主要就是 netconf 和 rf 俩, 其中 netconf 是从 /etc/cni/net.d 中读取出来的每个插件自己 copy 过去的配置文件, rt 是容器的运行时信息, 这些运行时信息在 cnitool 中是瞎创建的, 在 k8s 中由 CRI 创建
func (c *CNIConfig) addNetwork(ctx context.Context, name, cniVersion string, net *NetworkConfig, prevResult types.Result, rt *RuntimeConf) (types.Result, error) {
// ......
return invoke.ExecPluginWithResult(ctx, pluginPath, newConf.Bytes, c.args("ADD", rt), c.exec)
}
- 顺着 AddNetworkList 往下看, 其实最终就是把从 opt/cni/bin 下拿到的二进制文件给 exec 一下
- 把容器运行时的信息, 包括 containerId, netns path, 网卡设备名字等作为环境变量, 然后还再把从 /etc/cni/net.d 中读取到的以及上一次执行的插件结果(上面说过插件可以是个 list)作为标准输入
- 这样实现 CNI 插件的人在插件代码中就可以通过这两种方式去获取一些必要的信息了
- 最后执行完毕后回到 cnitool 中:
case CmdAdd:
result, err := cninet.AddNetworkList(context.TODO(), netconf, rt)
if result != nil {
_ = result.Print()
}
exit(err)
- 可以看到拿到了 result 之后直接 Print 了, 也就是说把插件执行结果作为标准输出了, 之后 CRI Runtime 就可以通过标准输出上的东西拿到插件执行结果从而进行一些后续操作
综上所述,所以只需要安装cni-containerd-cni的包,默认自带了CRI、CNI、RUNC
https://github.com/containerd/containerd/blob/main/docs/getting-started.md
containerd-1.6.23-linux-amd64.tar.gz
CRI https://github.com/cri-o/cri-o/blob/main/install.md#readme
CNI https://github.com/containernetworking/plugins/releases
runc https://github.com/opencontainers/runc/releases
cri-containerd-cni-1.6.23-linux-amd64.tar.gz
需要手动部署的有:
Containerd
CRI
CNI
RunC
注意:cri-containerd-cni版本解压后默认包含runc,但是缺乏相关依赖,建议自行安装并覆盖默认的 runc
说明:
1.ctr是containerd自带的CLI命令行工具,crictl是k8s中CRI(容器运行时接口)的客户端,k8s使用该客户端和containerd进行交互;
2.ctr和crictl命令具体区别如下,也可以–help查看。下面可以看出,crictl缺少对具体镜像的管理能力,可能是k8s层面镜像管理可以由用户自行控制,能配置pod里面容器的统一镜像仓库,镜像的管理可以有habor等插件进行处理。
| 命令 | ctr | crictl |
|---|---|---|
| 查看运行的容器 | ctr task ls/ctr container ls | crictl ps |
| 查看镜像 | ctr image ls | crictl images |
| 查看容器日志 | 无 | crictl logs |
| 查看容器数据信息 | ctr container info | crictl inspect |
| 查看容器资源 | 无 | crictl stats |
| 启动/关闭已有的容器 | ctr task start/kill | crictl start/stop |
| 运行一个新的容器 | ctr run | 无(最小单元为pod) |
| 修改镜像标签 | ctr image tag | 无 |
| 创建一个新的容器 | ctr container create | crictl create |
| 导入镜像 | ctr image import | 无 |
| 导出镜像 | ctr image export | 无 |
| 删除容器 | ctr container rm | crictl rm |
| 删除镜像 | ctr image rm | crictl rmi |
| 拉取镜像 | ctr image pull | crictl pull |
| 推送镜像 | ctr image push | 无 |
| 在容器内部执行命令 | 无 | crictl exec |
部署containerd
下载压缩包:
https://github.com/containerd/containerd/releases
由于默认压缩包解压的出来是自带目录路径的,所以把压缩包解压到根目录,自动放到对应的路径了
tar zxf cri-containerd-cni-1.6.23-linux-amd64.tar.gz -C /
#查看文件是否存在
cat /etc/cni/net.d/10-containerd-net.conflist
cat /etc/systemd/system/containerd.service
cat /etc/crictl.yaml
ll /opt/cni/bin
ll /opt/containerd/cluster
ll /usr/local/bin/containerd*
# 生成配置文件
mkdir -p /etc/containerd && containerd config default > /etc/containerd/config.toml
# 编辑配置文件,修改如下配置
vim /etc/containerd/config.toml
# 使用systemd作为Cgroup的驱动程序
SystemdCgroup = true
# 将镜像地址替换为国内阿里云
# sandbox_image = "registry.k8s.io/pause:3.6"
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
# 重新加载配置文件,设置开机自启并立即启动
systemctl daemon-reload
systemctl enable --now containerd
systemctl status containerd.service
#查看版本
containerd -version
ctr version
crictl version
#安装runc,因为自带的runc缺少依赖,执行命令报错
#下载命令可执行文件
https://github.com/opencontainers/runc/releases
https://github.com/opencontainers/runc/releases/download/v1.1.9/runc.amd64
#覆盖默认的 runc
cp -rf runc.amd64 /usr/local/sbin/runc
chmod +x /usr/local/sbin/runc && runc -v
删除containerd方式
rm -rf /etc/cni
rm /etc/systemd/system/containerd.service
rm /etc/crictl.yaml
rm -rf /opt/cni/
rm -rf /opt/containerd/
rm -rf /usr/local/bin/containerd*
rm /usr/local/sbin/runc
rm /usr/local/bin/ctr
