
cgroup 泄露
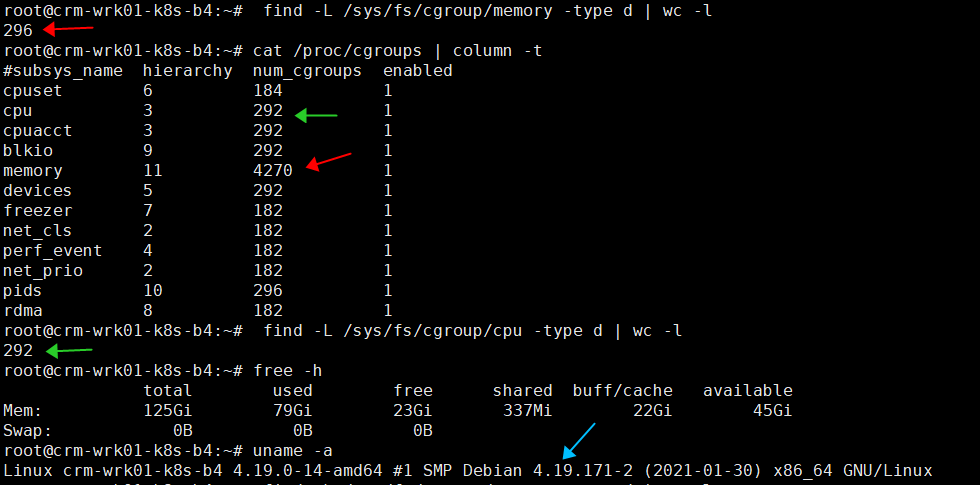
Linux操作系统查看 cgroup 数量:
cat /proc/cgroups | column -t
#subsys_name hierarchy num_cgroups enabled
cpuset 6 184 1
cpu 3 292 1
cpuacct 3 292 1
blkio 9 292 1
memory 11 4270 1
devices 5 292 1
freezer 7 182 1
net_cls 2 182 1
perf_event 4 182 1
net_prio 2 182 1
pids 10 296 1
rdma 8 182 1
cgroup 子系统目录下面所有每个目录及其子目录都认为是一个独立的 cgroup,所以也可以在文件系统中统计目录数来获取实际 cgroup 数量,通常跟 /proc/cgroups 里面看到的应该一致:
find -L /sys/fs/cgroup/memory -type d | wc -l
296
当 cgroup 泄露发生时,这里的数量就不是真实的了,低版本内核限制最大 65535 个 cgroup,并且开启 kmem 删除 cgroup 时会泄露,大量创建删除容器后泄露了许多 cgroup,最终总数达到 65535,新建容器创建 cgroup 将会失败,报 no space left on device
k8s现象
创建 Pod 失败,运行时报错 no space left on device
内核 Bug
memcg 是 Linux 内核中用于管理 cgroup 内存的模块,整个生命周期应该是跟随 cgroup 的,但是在低版本内核中(已知3.10),一旦给某个 memory cgroup 开启 kmem accounting 中的 memory.kmem.limit_in_bytes 就可能会导致不能彻底删除 memcg 和对应的 cssid,也就是说应用即使已经删除了 cgroup (/sys/fs/cgroup/memory 下对应的 cgroup 目录已经删除), 但在内核中没有释放 cssid,导致内核认为的 cgroup 的数量实际数量不一致,我们也无法得知内核认为的 cgroup 数量是多少。
关于 cgroup kernel memory,在 kernel.org 中有如下描述:
2.7 Kernel Memory Extension (CONFIG_MEMCG_KMEM)
-----------------------------------------------
With the Kernel memory extension, the Memory Controller is able to limit
the amount of kernel memory used by the system. Kernel memory is fundamentally
different than user memory, since it can't be swapped out, which makes it
possible to DoS the system by consuming too much of this precious resource.
Kernel memory accounting is enabled for all memory cgroups by default. But
it can be disabled system-wide by passing cgroup.memory=nokmem to the kernel
at boot time. In this case, kernel memory will not be accounted at all.
Kernel memory limits are not imposed for the root cgroup. Usage for the root
cgroup may or may not be accounted. The memory used is accumulated into
memory.kmem.usage_in_bytes, or in a separate counter when it makes sense.
(currently only for tcp).
The main "kmem" counter is fed into the main counter, so kmem charges will
also be visible from the user counter.
Currently no soft limit is implemented for kernel memory. It is future work
to trigger slab reclaim when those limits are reached.
这是一个 cgroup memory 的扩展,用于限制对 kernel memory 的使用,但该特性在老于 4.0 版本中是个实验特性,存在泄露问题,在 4.x 较低的版本也还有泄露问题,应该是造成泄露的代码路径没有完全修复,推荐 4.3 以上的内核。
造成容器创建失败
这个问题可能会导致创建容器失败,因为创建容器为其需要创建 cgroup 来做隔离,而低版本内核有个限制:允许创建的 cgroup 最大数量写死为 65535,如果节点上经常创建和销毁大量容器导致创建很多 cgroup,删除容器但没有彻底删除 cgroup 造成泄露(真实数量我们无法得知),到达 65535 后再创建容器就会报创建 cgroup 失败并报错 no space left on device,使用 kubernetes 最直观的感受就是 pod 创建之后无法启动成功。
dockerd 日志报错示例:
error: OCI runtime create failed: container_linux.go:348: starting container process caused \"process_linux.go:279: applying cgroup configuration for process caused \\\"mkdir /sys/fs/cgroup/memory/kubepods/burstable/pod79fe803c-072f-11e9-90ca-525400090c71/b98d4aea818bf9d1d1aa84079e1688cd9b4218e008c58a8ef6d6c3c106403e7b: no space left on device\\\"\": unknown"
kubelet 日志报错示例:
no space left on device
新版的内核限制为 2^31 (可以看成几乎不限制): cgroup_idr_alloc() 传入 end 为 0 到 idr_alloc(), 再传给 idr_alloc_u32(), end 的值最终被三元运算符 end>0 ? end-1 : INT_MAX 转成了 INT_MAX 常量,即 2^31。所以如果新版内核有泄露问题会更难定位,表现形式会是内存消耗严重,新版内核已经修复,推荐 4.3 以上。
规避方案
如果你用的低版本内核(比如 CentOS 7 v3.10 的内核)并且不方便升级内核,可以通过不开启 kmem accounting 来实现规避,但会比较麻烦。
kubelet 和 runc 都会给 memory cgroup 开启 kmem accounting,所以要规避这个问题,就要保证kubelet 和 runc 都别开启 kmem accounting,下面分别进行说明:
runc
runc创建的容器都默认开启了 kmem accounting,后来社区也注意到这个问题,并做了比较灵活的修复,给 runc 增加了 “nokmem” 编译选项,缺省的 release 版本没有使用这个选项, 自己使用 nokmem 选项编译 runc 的方法:
cd $GO_PATH/src/github.com/opencontainers/runc/
make BUILDTAGS="seccomp nokmem"
docker-ce v18.09.1 之后的 runc 默认关闭了 kmem accounting,所以也可以直接升级 docker 到这个版本之后。
kubelet
如果是 1.14 版本及其以上,可以在编译的时候通过 build tag 来关闭 kmem accounting:
KUBE_GIT_VERSION=v1.14.1 ./build/run.sh make kubelet GOFLAGS="-tags=nokmem"
如果是低版本需要修改代码重新编译。kubelet 在创建 pod 对应的 cgroup 目录时,也会调用 libcontianer 中的代码对 cgroup 做设置,在 pkg/kubelet/cm/cgroup_manager_linux.go 的 Create 方法中,会调用 Manager.Apply 方法,最终调用 vendor/github.com/opencontainers/runc/libcontainer/cgroups/fs/memory.go 中的 MemoryGroup.Apply 方法,开启 kmem accounting。这里也需要进行处理,可以将这部分代码注释掉然后重新编译 kubelet。
总结:
- 建议升级系统内核4.3以上
- 其次重新编译kubelet组件,关闭 kmem accounting
- 超大规模集群,cgroup数量才有可能达到65535