前因后果
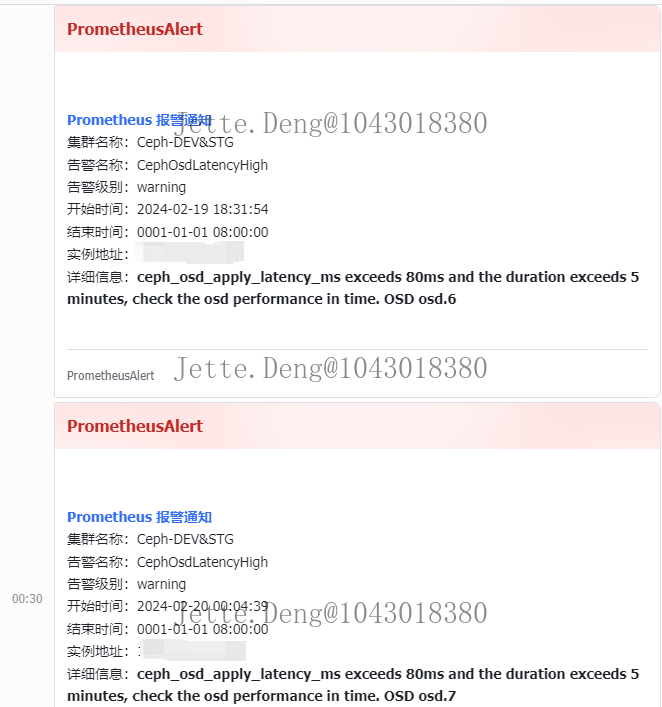
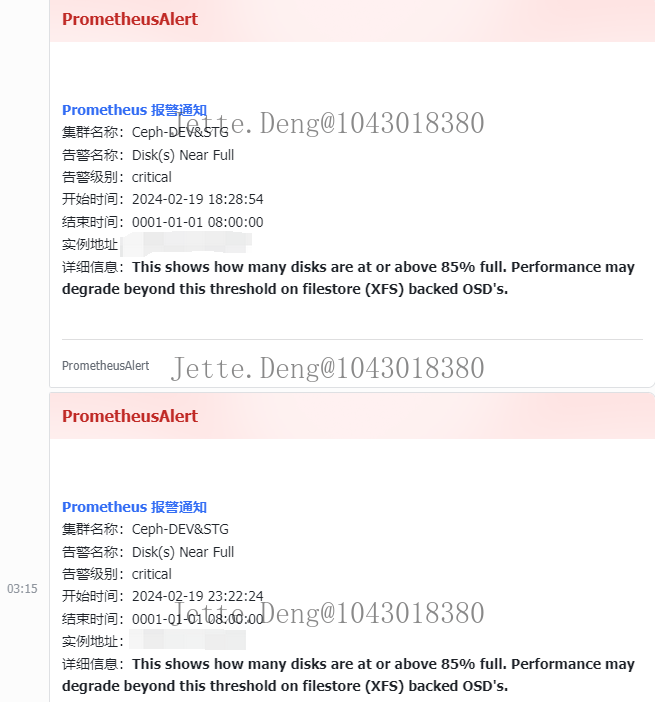
- 从18:30开始就已经出现了告警,osd磁盘超85%、osd提交延迟超过80ms,然后查看了集群状态,是缓存层比较使用的容量较多,所以缓存层的osd使用量超85%,然后执行了刷盘操作,只需耐心等待数据落盘到后端osd存储即可,然后就没管它了。直到21:00后还发现持续有告警,发现不太对劲,再去查看集群状态,发现osd使用量还在增长,osd数量也在增长,存储池一直有大量读写,然后顺藤摸瓜找到该池所被使用的PVE,最终发现是调用PVE接口有持续的并发克隆操作导致
相关告警和日志信息:



解决过程
-
手动在PVE停止克隆并删除释放资源,发现还会循环的调用克隆操作,可以判断是有程序在调用PVE接口。两个怀疑点,一是否被入侵刷接口搞破坏,二是否后端代码调用导致。
-
直接限制该存储池配额上限为10T实际容量,3副本为30T,所以43T超出配额,该池会无法写入,VM操作系统Hang住、read-only,等解除配额后会恢复,另外IO高也会导致这种情况,所以性能、状态、重要信息监控非常重要。此限制操作是为了避免牵连其它存储池,所有项目环境一锅端就GG了。
-
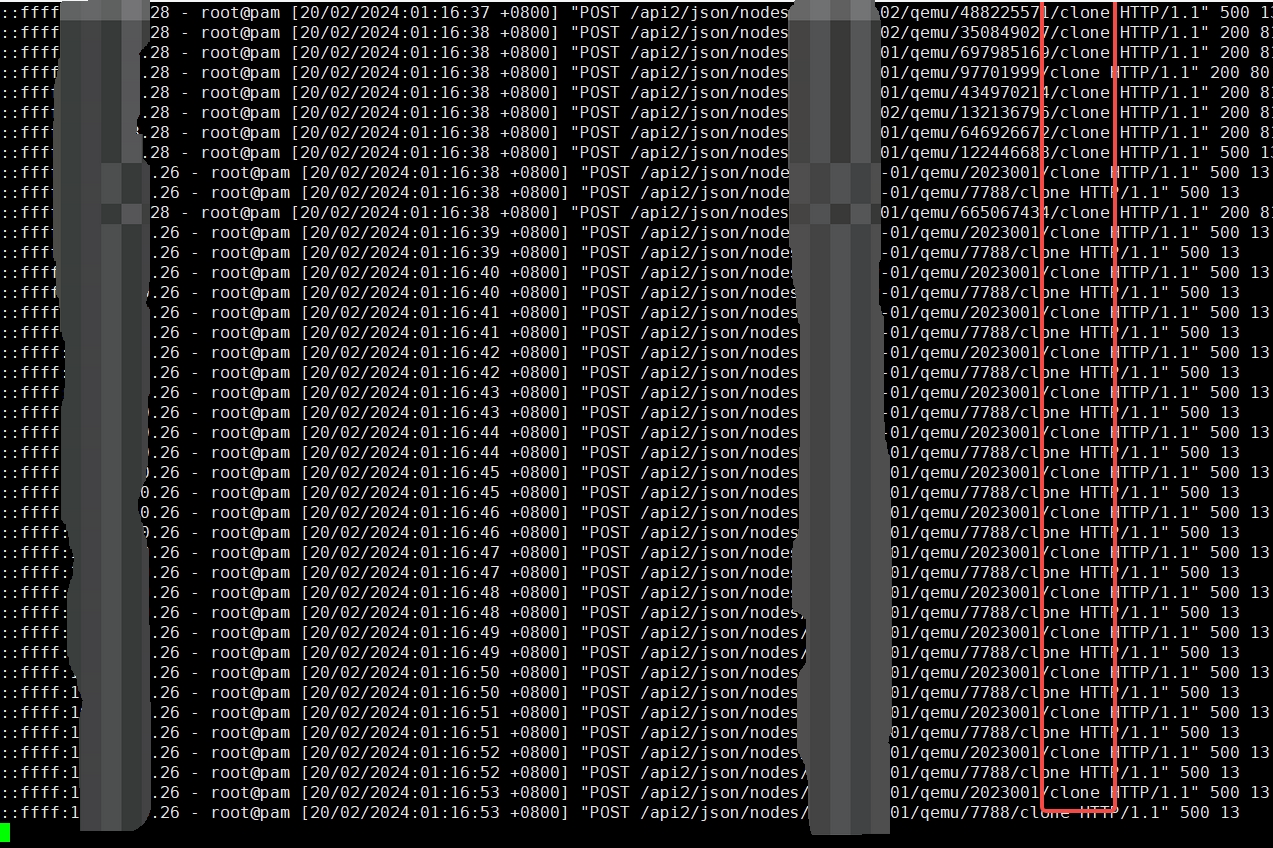
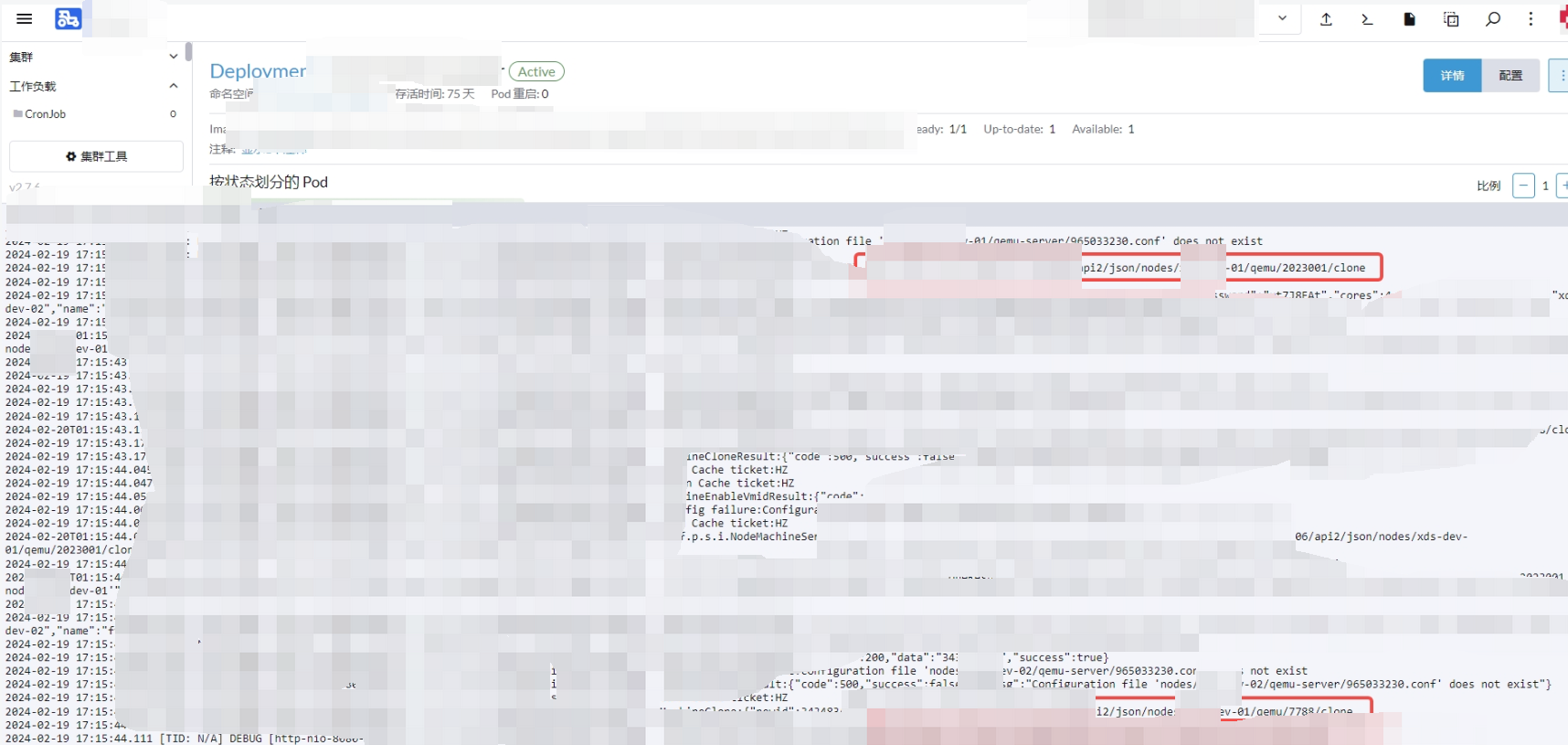
由于限制了,所以Ceph暂时得到缓解,此时已经快凌晨1点,本想着休息睡觉第二天反馈给项目组检查代码逻辑流程,但找不出原因又不甘心睡不着,然后继续定位问题。先是查看PVE操作系统内核日志、进程等,找是否有异常问题,发现并无异常。然后查看了PVE访问日志,发现了2个集群的K8S节点一直在POST刷接口克隆操作,随后到K8S集群找到了罪魁祸首,停掉之后立马恢复。此时凌晨3点,上床睡觉。
-
第二天反馈给项目组,随后bug解决修复。原因是旧的脏数据导致,正常克隆完成后,会去修改对应数据状态为已克隆,现在因为脏数据的存在,导致正常克隆后没有修改数据的状态为已克隆,所以就一直去重复克隆,将对应数据清除恢复。
解决方案
-
检查业务流程是否需要优化
-
避免/禁止使用root账户调用PVE
-
避免/禁止调用PVE大批量并发克隆
-
避免/禁止只会克隆,而不会删除/释放VM或磁盘。用完就释放,避免造成浪费
-
测试环境系统盘无特殊需求,尽量使用40G以下。目前80G系统盘的VM数量较多,需调整系统盘大小,避免浪费存储空间
总结
-
监控重要性:假设没有监控,第二天睡醒,Ceph存储全爆了,部分项目和内部功能测试环境、性能压测环境的VM都会受影响,内核Read-only。这就会拖慢部分项目的开发进度、测试进度。
-
运维响应积极性
-
敏锐判断力
-
如果是生产环境业务快速增长,那么正确的做法是立马上架服务器,横向扩容,尽量低成本实现高性能。尽可能既要又要

