Ceph节点故障触发重平衡,导致IO堆积,大量SLOW OPS卡死OSD,引起虚拟机无法写入解决方法
由于1台节点主板电压不稳,突然暴毙。大概有40T数据,此节点宕机后,触发Ceph的重平衡机制,此时磁盘占用大量IO,然后影响到虚拟机的读写性能和可用性,最后导致Ceph堆积了大量IO在排队处理,造成虚拟机可能出现这些情况:IO路径闪断、操作系统瞬间无法写入、无法开机、IO资源争抢。
主要原因是:
- crushmap规则里面的故障域没有改成host,导致3副本都在同一台节点
- 故障节点硬盘可以不用格式化,禁止集群重平衡,重新把故障节点加入集群尝试激活旧的硬盘
- 把故障节点的硬盘格式化了,重新加入集群,导致丢失部分PG,而集群认为PG的ID是存在的,实际上,这些数据块并不在磁盘了,所以一直堆积着
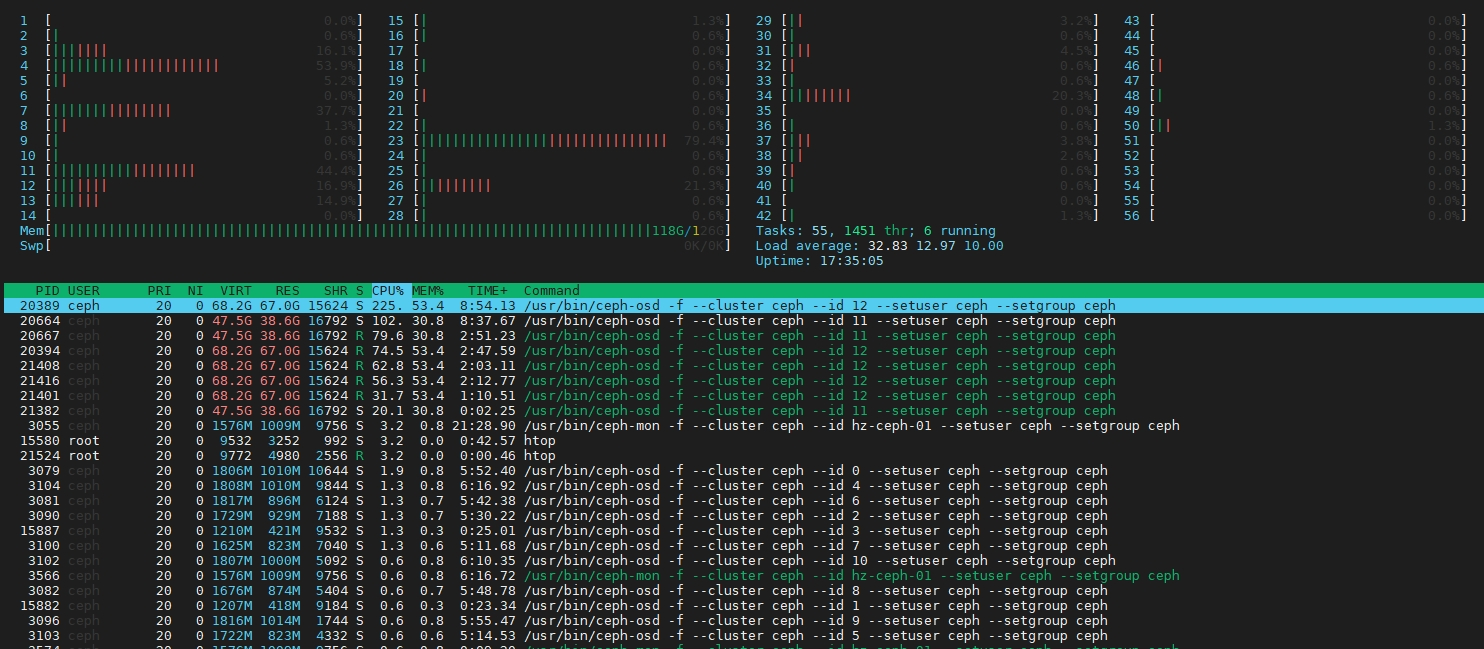
首先查看IO是否被阻塞,如果被阻塞了,证明前面有任务IO在排队,导致后面的也无法写入,没有流量进来。下图就是IO被堆积阻塞了,由于把旧的盘格式化,节点还是旧的系统,重新加入集群,主机名和IP都是一样的,导致去操作部分PG时,实际上数据块没有在磁盘了,一直hang住,堆积阻塞着,后面的任务IO无法处理。Ceph是处理完第一个IO完整的请求之后,才会处理第二个的
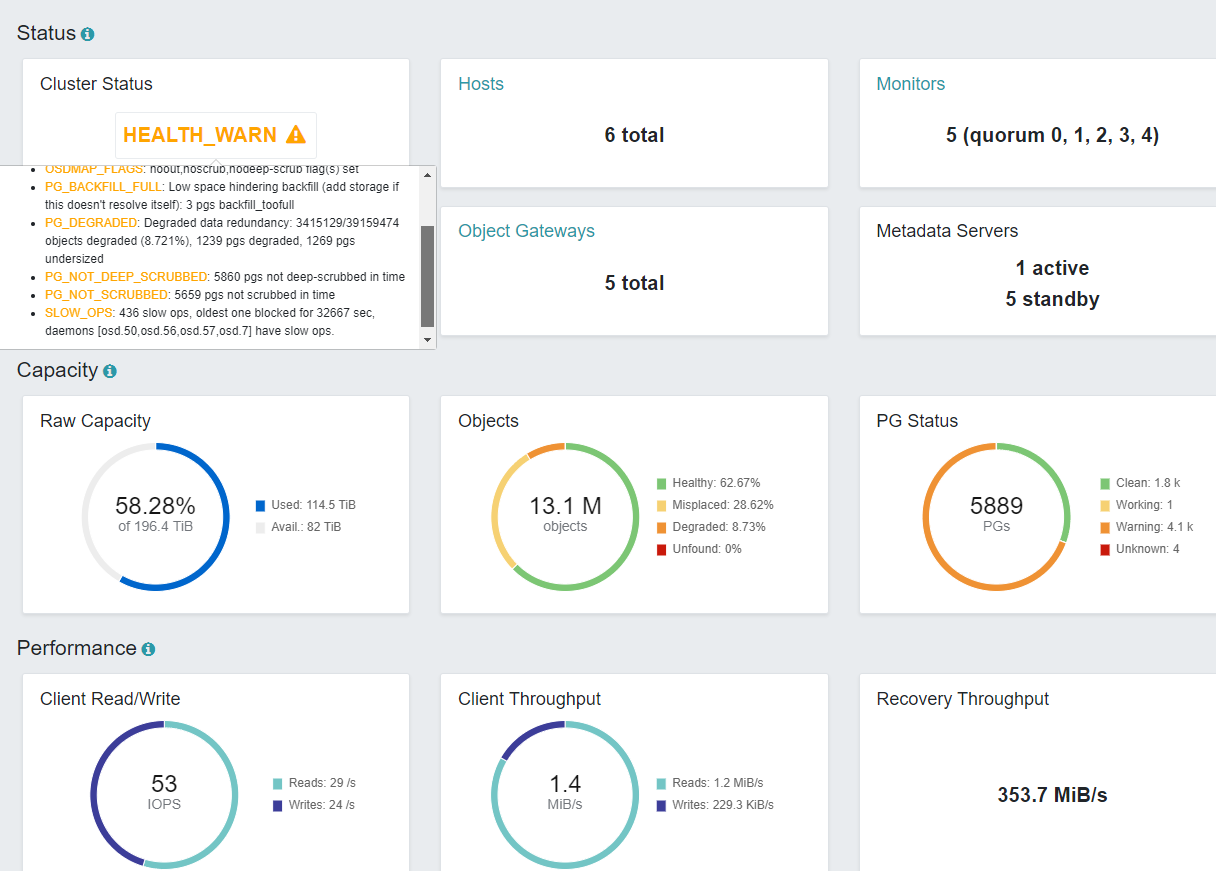


告警里面一堆的slow ops,就是那些空的数据块在卡着
PG_AVAILABILITY: Reduced data availability: 29 pgs
查看mon日志、mds日志、osd日志
tail -f -n 200 /var/log/ceph/
首先查看告警上面的PG是否存在,如果不存在了,那只能重建PG
ceph pg 6.14 query
Error ENOENT: i don't have pgid 6.14
不存在这个PG了,只能重建,否则会一直卡着这些IO
逐个PG都要重建
ceph osd force-create-pg 19.15a --yes-i-really-mean-it
上面重建完PG之后,如果还有部分OSD处于slow ops,需要手动重启这几个OSD
先看日志有没有slow ops的提示,然后逐个OSD重启
tail -f -n 200 /var/log/ceph/ceph-osd.50.log
systemctl restart ceph-osd@50
然后集群就能恢复正常读写,处理IO了。但是还会出现unknown的PG,只能修复,修复不了只能回滚或删掉
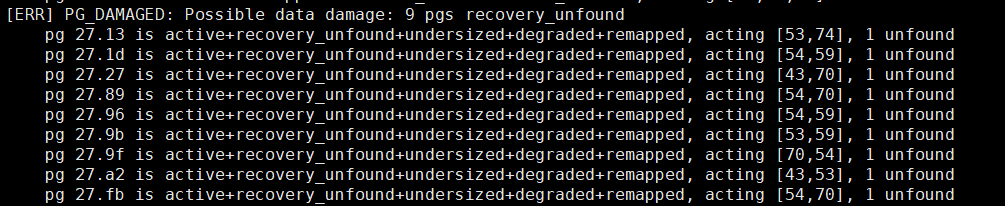
先看下unknown的pg是否实际存在?如果还有1个osd存在该pg副本的,则尝试修复,修复PG的在下面PG数据损坏有流程,比较麻烦。修复不了只能删掉
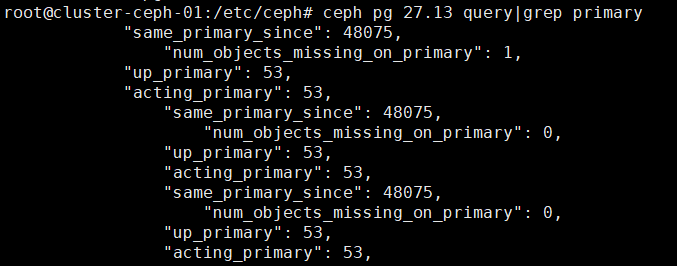
删除unknown的pg的命令
ceph pg 27.13 mark_unfound_lost delete
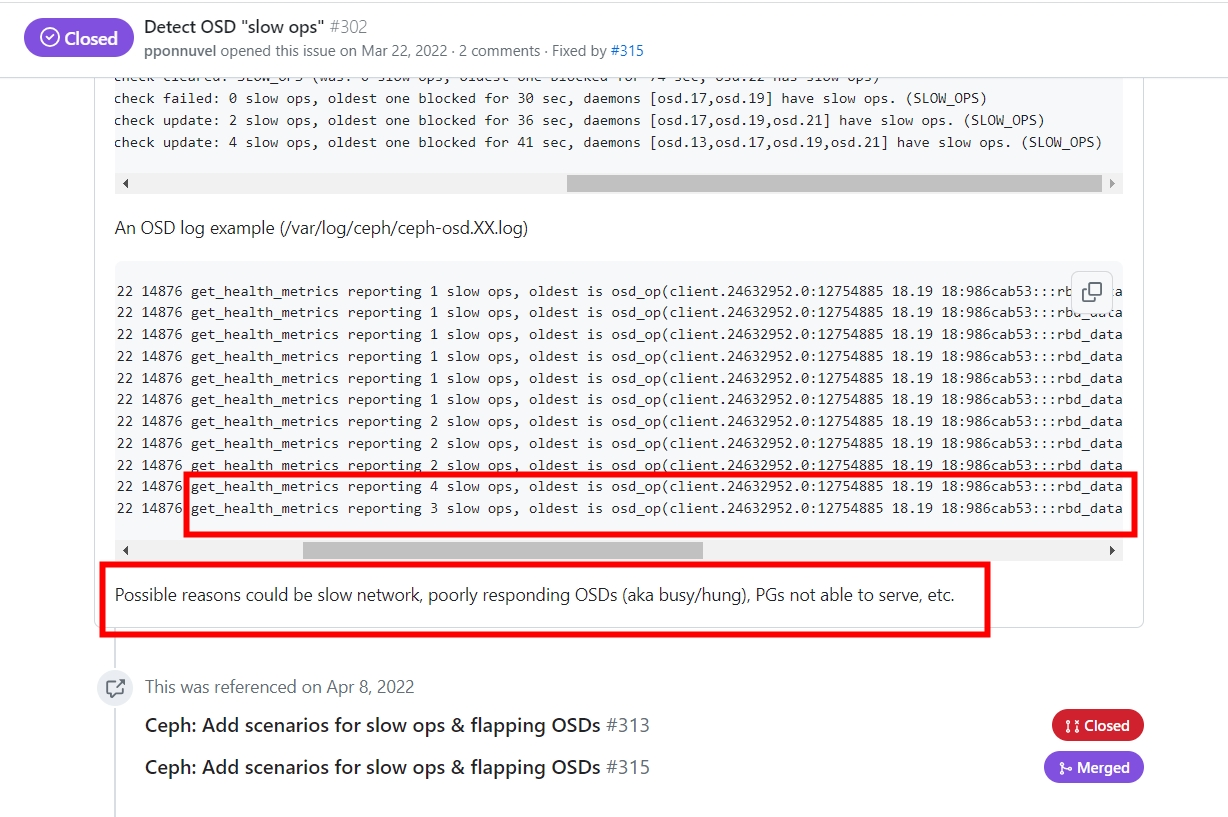
get_health_metrics reporting 3 slow ops的解决办法!
查看集群状态发现慢请求的osd告警:
OSD_SLOW_PING_TIME_BACK: Slow OSD heartbeats on back (longest 3160.225ms) OSD_SLOW_PING_TIME_FRONT: Slow OSD heartbeats on front (longest 3011.094ms)
SLOW_OPS: 4 slow ops, oldest one blocked for 970 sec, osd.11 has slow ops
osd日志发现:
osd.11 31902 get_health_metrics reporting 4 slow ops, oldest is osd_op(client.145746656.0:142372 17.ee 17:77588fb0:::rbd_data.3c1db779e4202a.0000000000000105:6 [sparse-read 0~1048576] snapc 0=[] ondisk+read+known_if_redirected e31902) log_channel(cluster) log [WRN] : 4 slow requests (by type [ ‘reached pg’ : 1 ‘delayed’ : 3 ] most affected pool [ ‘hz-c1-basic-wrk-pve-cache’ : 4 ])
相关慢ops的案例:
https://forum.proxmox.com/threads/ceph-sudden-slow-ops-freezes-and-slow-downs.111144/
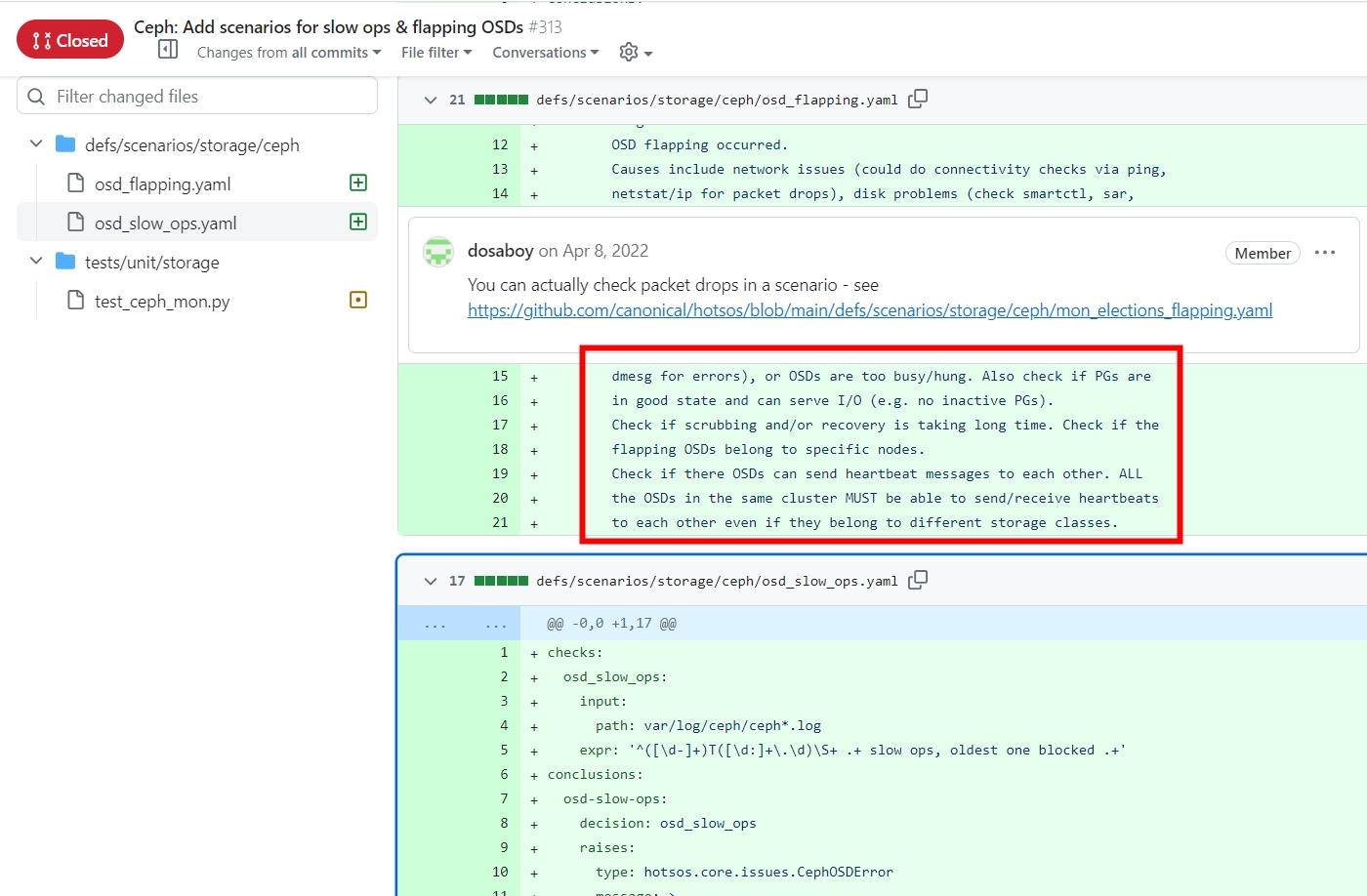
https://github.com/canonical/hotsos/issues/302
https://github.com/canonical/hotsos/pull/313/commits/f4f7c7d191f887f06af92f31bd1116320478f94f
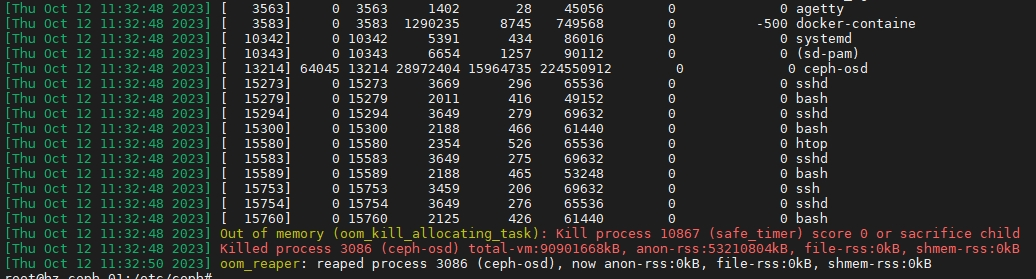
问题原因:因为osd是机械硬盘,导致nvme缓存层的大量IO卡住,卡住原因是由于nvme缓存盘线程较多,直接把整个节点的内存吃完,导致触发内核OOM。多个子操作执行速度慢,又导致IO等待时间增加,最后op_commit将操作结果写入osd机械硬盘存储,机械盘延迟较高,所以客户端新进去的流量,又触发NVME类型的osd缓存盘请求阻塞限流,引发多个osd震荡,最终节点CPU、内存突增OOM,以此恶性循环。
还有osd有逻辑坏道也会导致slow ops,延迟会非常高,虽然说不会有致命威胁,但会严重拉低性能。以下是逻辑坏道的警告信息:
[WRN] OSD_TOO_MANY_REPAIRS: Too many repaired reads on 1 OSDs** osd.32 had 13 reads repaired**
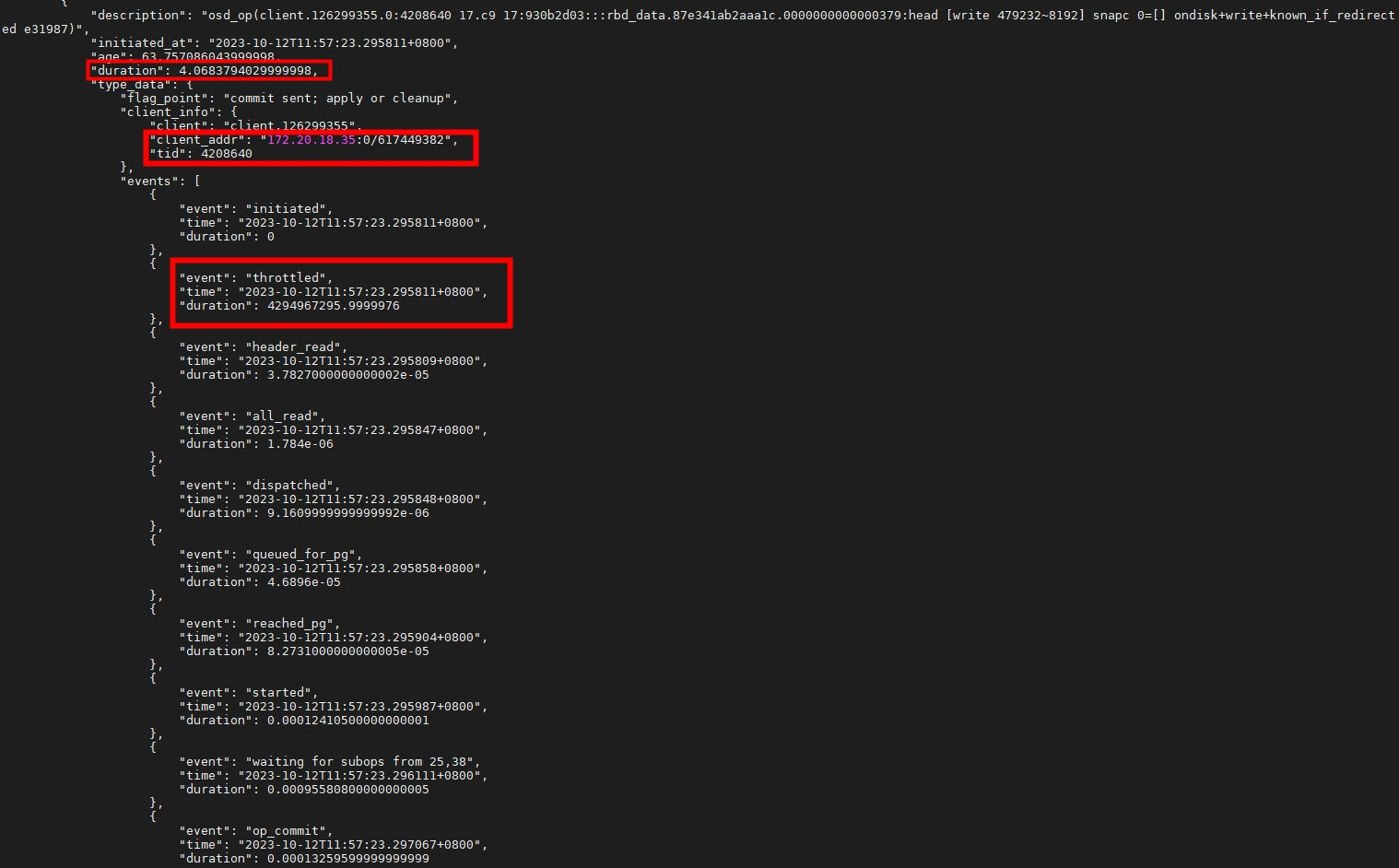
下图是op的全流程和时间:
通常整个流程是0.05秒,即是50毫秒以内才算正常。这里用了4秒多,有些甚至70秒,延迟非常严重
#查看op的完整流程
ceph daemon osd.11 dump_historic_ops_by_duration
#过滤一下时间
ceph daemon osd.11 dump_historic_ops_by_duration|grep duration
#查看osd的日志,找一下pg的号数对应的osd
ceph pg 6.e1 query|grep primary
#查看osd对应的磁盘io
iostat -xm 1

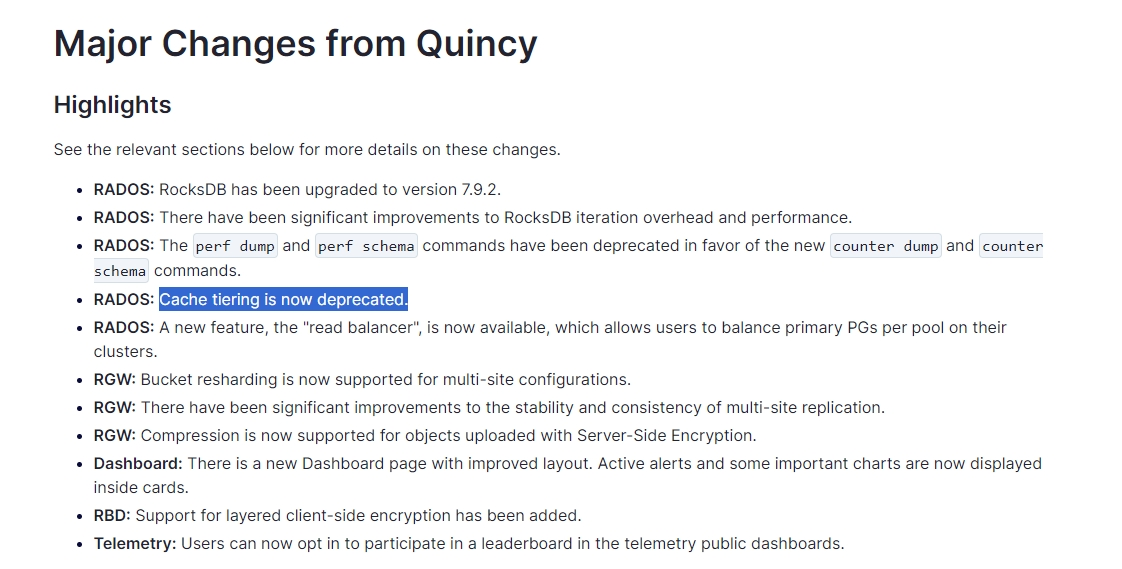
官方新版弃用了缓存层,不稳定有缺陷:
https://ceph.com/en/news/blog/2023/v18-2-0-reef-released/
https://github.com/feryw/linux-4.14.y/commit/3f376cc03766f2c1f98f63066700e7d1a3d94f0d
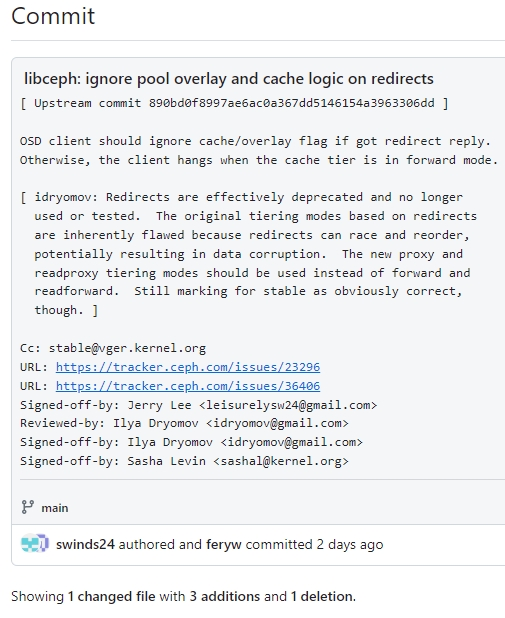
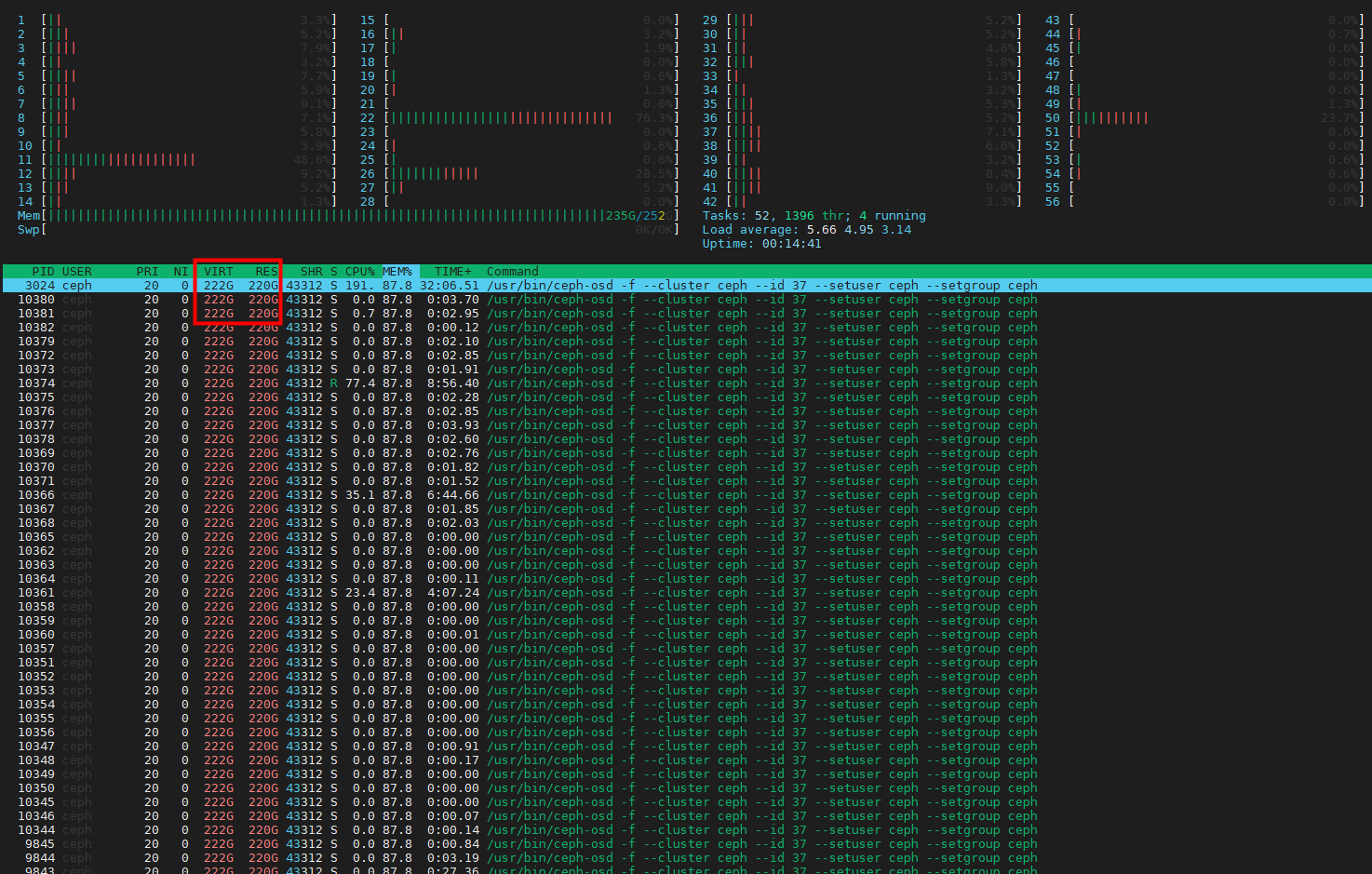
解决办法:
#把ping_time调整3000ms或5000ms
ceph tell osd.* injectargs '--mon_warn_on_slow_ping_time 3000'
#升级物理服务器内存256G
#调整osd的system参数
OOMScoreAdjust=-1000
Restart=always
systemctl daemon-reload
#上面的步骤实在不行,如果还是暴增内存。那么只能把缓存层给刷盘,删除了
ceph osd tier cache-mode hz-c1-basic-wrk-pve-cache readproxy --yes-i-really-mean-it
rados -p hz-c1-basic-wrk-pve-cache cache-flush-evict-ail
#删除 overlay,这样客户端不会再访问缓存层
ceph osd tier remove-overlay hz-c1-basic-wrk-pve
#最后删除 缓存池
ceph osd tier remove hz-c1-basic-wrk-pve hz-c1-basic-wrk-pve-cache