1、查看当前集群磁盘使用率
目前集群已使用54T的数据,一共32块硬盘。
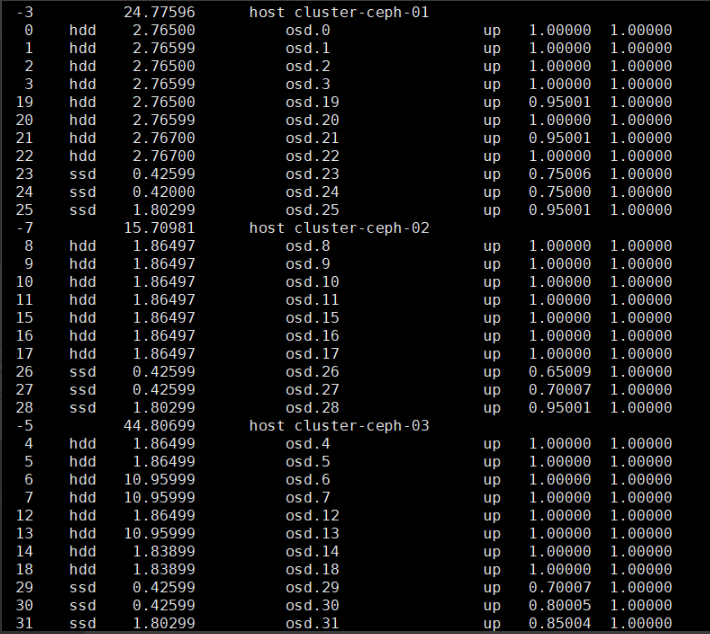
2、新增节点的硬盘数为12块,32+12=44(块),大约占总盘数的27%。因此可算出,54T的27%大约为15T,新增该节点后,大约会有15T数据需要重平衡。最准确的方式是新增节点之后,马上查看集群状态,查看具体多少数据重平衡,就可以比较准确的预估时间。
#新增节点之后,通过命令查看集群重平衡的pgs数量以及百分比
ceph -s
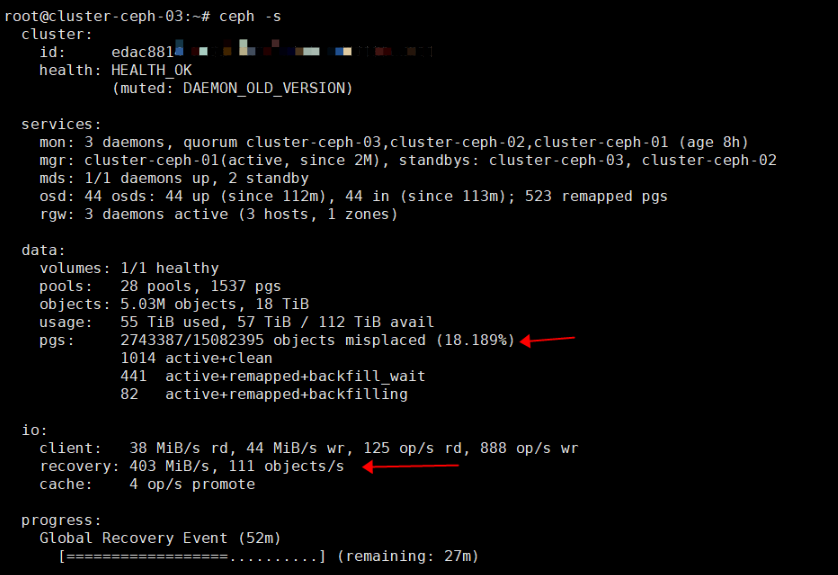
15T数据重平衡,按照400MiB/s的速度,则需要大约11小时。
重平衡的速度取决于对osd的设置,为了避免影响服务的可用性,我设置了业务优先,只用50%的速度,如果全部osd全速运行,则会导致所有client端不可用、io超时等情况。
3、以下为osd配置参数解释
默认配置参数:
“osd_max_backfills”: “1”, “osd_recovery_sleep”: “0”, “osd_recovery_max_active”: “3”, “osd_recovery_max_single_start”: “1”,
推荐配置参数:
级别:
5%是业务优先,对业务影响最小; 100%恢复优先,对业务影响最大; 其他介于二者之间;
| 级别 | osd_max_backfills | osd_recovery_max_active | osd_recovery_max_single_start | osd_recovery_sleep | osd_min_pg_log_entries | osd_max_pg_log_entries |
|---|---|---|---|---|---|---|
| 5% | 1 | 1 | 1 | 1 | 1 | 2 |
| 25% | 50 | 5 | 5 | 0.25 | 1 | 2 |
| 50% | 50 | 5 | 5 | 0.15 | 1 | 2 |
| 75% | 50 | 5 | 5 | 0 | 1 | 2 |
| 100% | 50 | 5 | 5 | 0 | 1500 | 10000 |
osd_min_pg_log_entries 正常情况下PGLog的记录的条数,
osd_max_pg_log_entries 异常情况下pglog记录的条数,达到该限制会进行trim操作
参数解析:
-
osd_max_backfills :
一个osd上最多能有多少个pg同时做backfill。其中osd出去的最大backfill数量为osd_max_backfills ,osd进来的最大backfill数量也是osd_max_backfills ,所以每个osd最大的backfill数量为osd_max_backfills * 2;
-
osd_recovery_sleep:
出队列后先Sleep一段时间,拉长两个Recovery的时间间隔;
以下二个参数,网上解释大多有误导,结合代码以及官方材料分析为:
- osd_recovery_max_active:
每个OSD上同时进行的所有PG的恢复操作(active recovery)的最大数量
- osd_recovery_max_single_start:
OSD在某个时刻会为一个PG启动恢复操作数; 这两个参数需要结合在一起分析: a.假设我们配置osd_recovery_max_single_start为1,osd_recovery_max_active为3,那么,这意味着OSD在某个时刻会为一个PG最多启动1个恢复操作,而且最多可以有3个恢复操作同时处于活动状态。 b.假设我们配置osd_recovery_max_single_start为2,osd_recovery_max_active为3,那么,这意味着OSD在某个时刻会为一个PG最多启动2个恢复操作,而且最多可以有3个恢复操作同时处于活动状态。例如第一个pg启动2个恢复操作,第二个pg启动1个恢复操作,第三个pg等待前两个pg 恢复操作完进行新的恢复。
执行命令格式:
ceph tell osd.* injectargs ‘参数 数字或百分比’
ceph tell osd.* injectargs ‘–osd-max-backfills 8’
4、注意事项
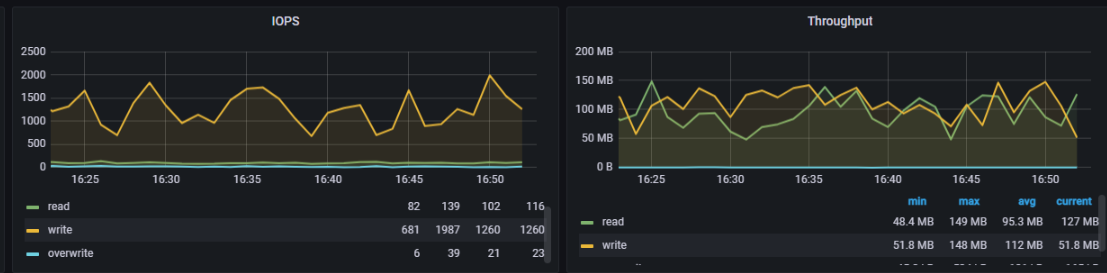
数据重平衡过程中,需要观察Grafana监控面板,读写是否正常,如果读写比未重平衡之前偏低很多,可以把重平衡的速度再限制低一点
下图示例,触发重平衡之后与未重平衡之前,读写依旧保持正常: