硬件配置
-
3台RH2288v5服务器组建全闪集群
-
RH2288v5服务器单节点配置:
2 * Intel Gold 6133
2 * 32G DDR4 内存
1 * 200G S3700 SSD
8 * 4T P4500 U2 SSD
网络配置
- 双网卡内外网分离
- 双口万兆光
- public network:前端公共网络,南北向网络,用于连接Client和集群。
- cluster network:后端集群网络,东西向网络,用于连接Ceph内部各个存储节点。
- public network带宽bond 20G
- cluster network带宽10G
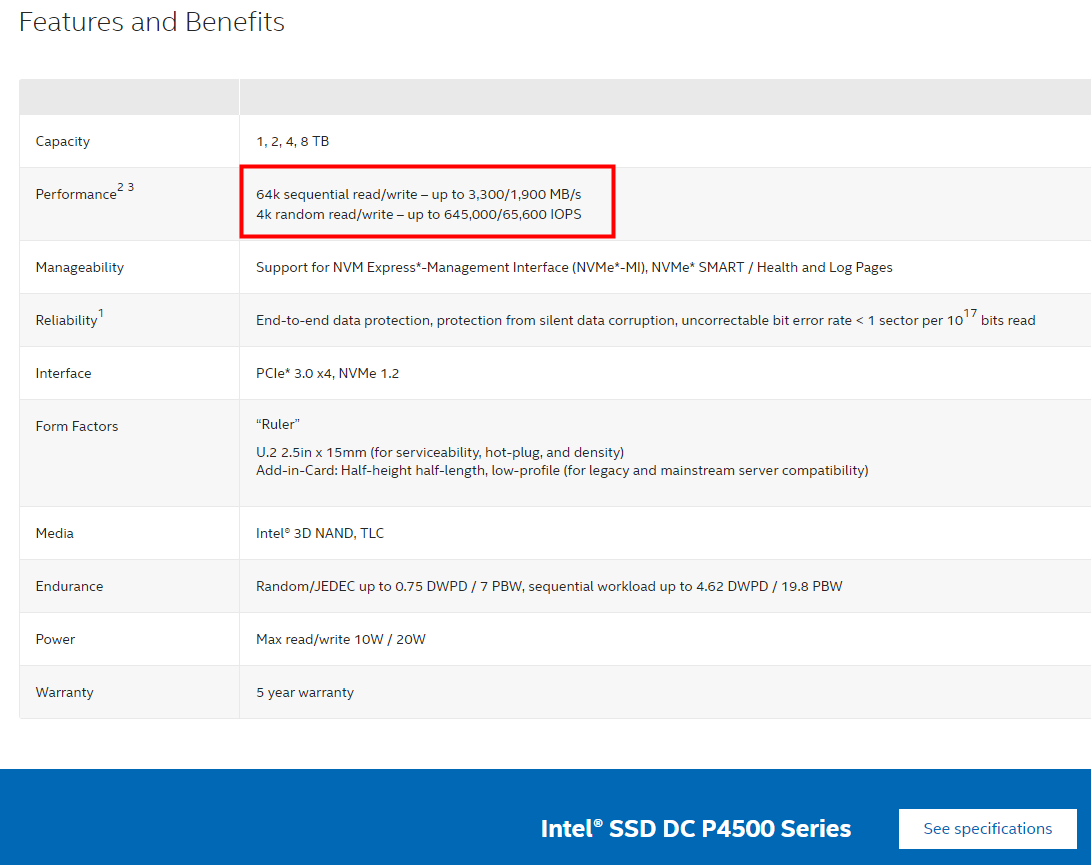
官方的硬盘参数
Ceph架构模式
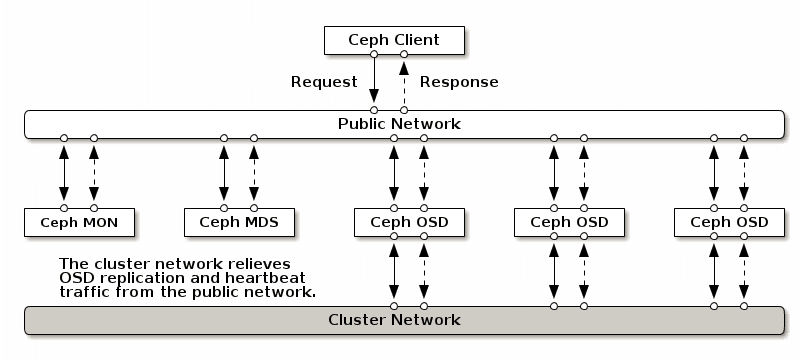
大部分Cpeh集群按照官网方式搭建出来基本上都是将Client,Mgr,RDB,Mon等放在同一个网段,其中数据恢复,复制等都走的一个网段,影响用户服务质量与其他速度。
OSD之间有大量的数据拷贝操作,这样分拆为两张网络,提高了性能。两网分离,也提高了安全性。
为什么要做内外网分离
Ceph 的客户端,如RBD,会直接和 OSD 互联,以上传和下载数据,这部分是直接提供对外下载上传能力的;Ceph 一个基本功能是提供数据的冗余备份,OSD 负责数据的备份,跨主机间的数据备份当然要占用带宽,而且这部分带宽是无益于 Ceph 集群的吞吐量的。只有一个网络,尤其是有新的存储节点加入时,Ceph 集群的性能会因为大量的数据拷贝而变得很糟糕。建立内网是为了降低 OSD 节点间数据复制对 Ceph 整体的影响,那么只要在 OSD 节点上加内网就可以了,上图非常清晰的描述了内网和外网覆盖的范围。
做内外网分离,必不可少的前提条件是 OSD 服务器上必须有两张可用的网卡,并且网络互通,确保这点我们就可以开始了。所以对于性能有一定要求的用户,还是有必要配置内外网分离的。
Ceph配置文件修改
#注意:每个osd都需要填上对应节点的IP地址,需要提前规划好,哪些osd号数是属于哪个节点的
[global]
.....................
public_network = 172.20.18.0/24
cluster_network = 172.20.8.0/24
.....................
[osd.0]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.1]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.2]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.3]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.4]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.5]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.6]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.7]
host = ra0328-ceph-c1-p1
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[osd.8]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.9]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.10]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.11]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.12]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.13]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.14]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.15]
host = ra0325-ceph-c1-p2
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[osd.16]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.17]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.18]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.19]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.20]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.21]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.22]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[osd.23]
host = ra0322-ceph-c1-p3
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
[client.rgw.ra0328-ceph-c1-p1]
rgw_frontends = "civetweb port=80"
public_addr = 172.20.18.41
cluster_addr = 172.20.8.15
[client.rgw.ra0325-ceph-c1-p2]
rgw_frontends = "civetweb port=80"
public_addr = 172.20.18.42
cluster_addr = 172.20.8.16
[client.rgw.ra0322-ceph-c1-p3]
rgw_frontends = "civetweb port=80"
public_addr = 172.20.18.43
cluster_addr = 172.20.8.17
故障测试
- public_network:前端公共网络,南北向网络,用于PVE连接Ceph集群。
- cluster_network:后端集群网络,东西向网络,用于连接Ceph内部各个存储节点,osd to osd。
测试过程
-
第一台节点断开cluster_network网线,发现集群并没有将第一台节点的osd设置为down,任然为up。
-
警告信息:8982 slow ops, oldest one blocked for 4375 sec(堵塞无法写了)
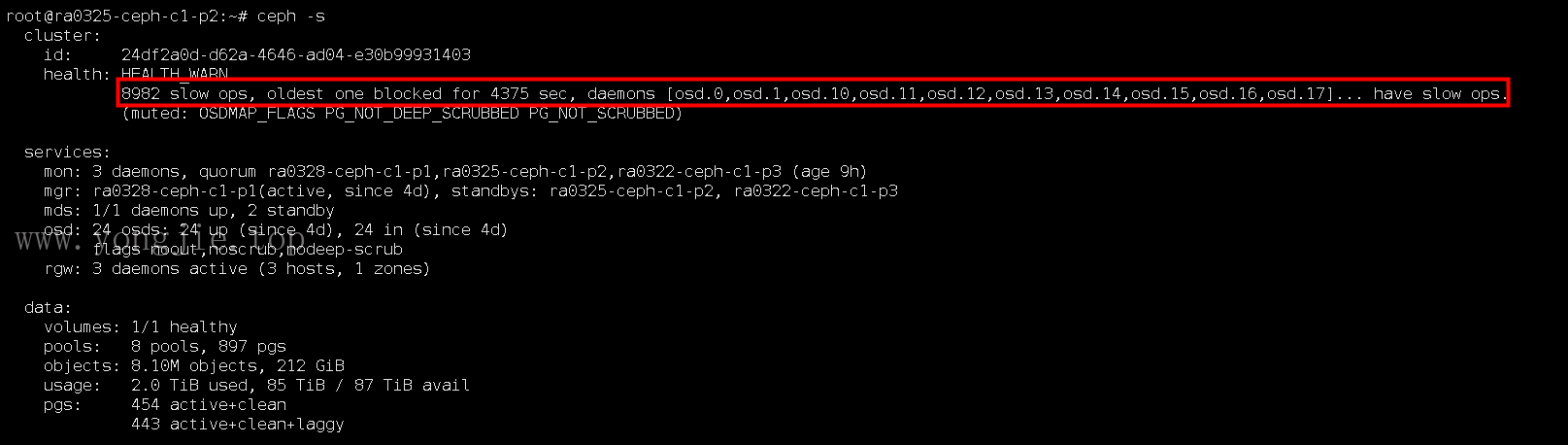
-
日志报错:
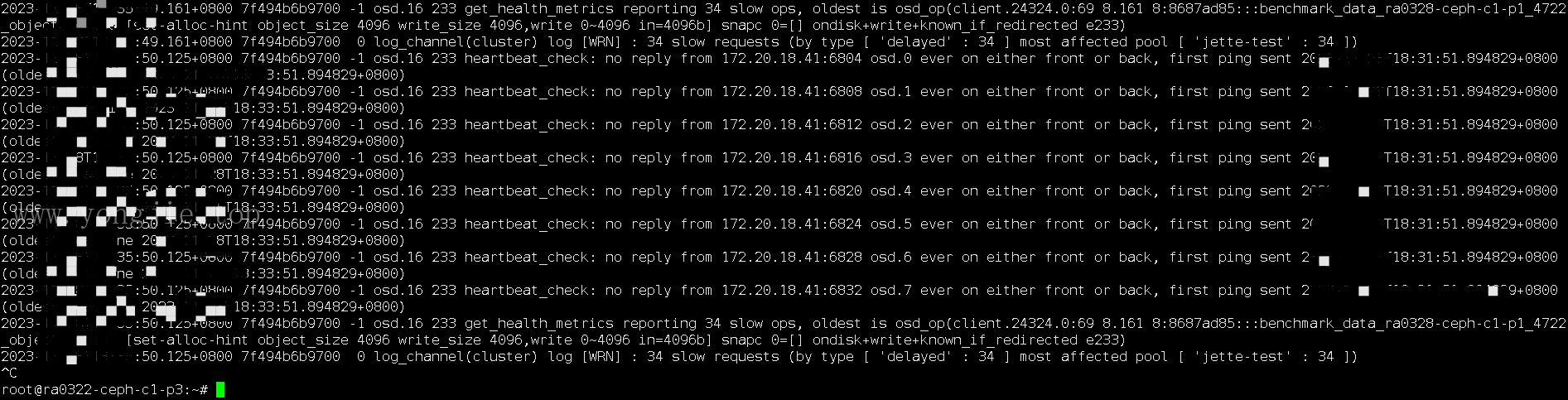
-
PVE挂载克隆失败报错:
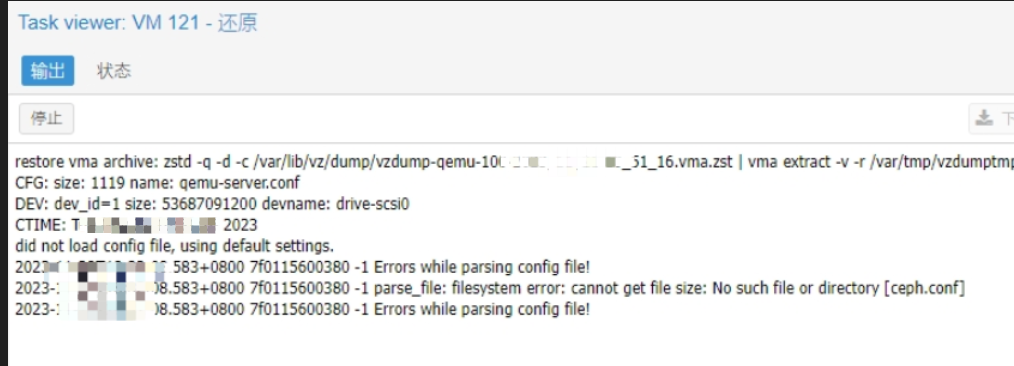
-
使用ceph自带压测工具(rados bench),也是不可写入的,这里忘记截图了
结论
- 因为osd之间的心跳包走的是public_network,所以osd一直为up,也就不会将osd剔除,会认为是健康正常的。
- 跨节点osd与osd之间因网络中断无法复制数据副本,又因为osd为up,所以cluster_network就会堵塞大量的IO排队不断重试,导致集群hang死无法写入,不可用。
- 唯一的解决办法是手动将osd设置为down,然后从集群中out,才能恢复正常读写。(这个方案显然不可行)
最终解决方案
经过上述验证决定,为了保证故障的可用性,三节点容忍任意故障一台节点。不采用此双网络的模式,与原来的模式不变,public_network和cluster_network都使用同一网段。

