官方文档:https://docs.ceph.com/en/mimic/start/quick-ceph-deploy/
系统调优
执行完debian-init.sh脚本后,仍需针对性的调优
#修改网卡mtu
vim /etc/network/interfaces
mtu 9000
#cat /proc/sys/kernel/pid_max查看修改建议:设置系统可生成最大线程数为4194303。
echo 4194303 > /proc/sys/kernel/pid_max
#通过cat /proc/sys/fs/file-max查看修改建议:设置系统所有进程一共可以打开的文件数量,设置为cat /proc/meminfo | grep MemTotal | awk '{print $2}' 所查看到的值。
echo ${file-max} > /proc/sys/fs/file-max
说明:${file-max}为cat /proc/meminfo | grep MemTotal | awk '{print $2}' 所查看到的值
echo 65918092 > /proc/sys/fs/file-max
#默认值:128 kb修改完后是否需要重启:否。现象:预读可以有效的减少磁盘的寻道次数和应用程序的I/O等待时间。通过/sbin/blockdev --getra /dev/sdb查看修改建议:通过数据预读并且记载到随机访问内存方式提高磁盘读操作,调整为8192 kb。
/sbin/blockdev --setra 8192 /dev/sdc
/sbin/blockdev --setra 8192 /dev/sdg
/sbin/blockdev --setra 8192 /dev/sdf
/sbin/blockdev --setra 8192 /dev/sde
#默认值:CFQ修改完后是否需要重启:否现象:要根据不同的存储器来设置Linux I/O 调度器从而达到优化系统性能。修改建议:I/O调度策略,HDD设置为deadline,SSD设置为noop。对所有服务器上的所有数据盘都要修改。
HDD盘:
echo deadline > /sys/block/sdc/queue/scheduler
echo deadline > /sys/block/sdg/queue/scheduler
echo deadline > /sys/block/sdf/queue/scheduler
echo deadline > /sys/block/sde/queue/scheduler
#默认值:128修改完后是否需要重启:否现象:通过适当的调整nr_requests 参数可以提升磁盘的吞吐量修改建议:调整硬盘请求队列数,设置为512。对所有服务器上的所有数据盘都要修改。
echo 512 > /sys/block/sdc/queue/nr_requests
echo 512 > /sys/block/sdg/queue/nr_requests
echo 512 > /sys/block/sdf/queue/nr_requests
echo 512 > /sys/block/sde/queue/nr_requests
echo 512 > /sys/block/sdd/queue/nr_requests
echo 512 > /sys/block/sdb/queue/nr_requests
三台机器都执行
vim /etc/hosts
10.16.0.61 cluster-ceph-01
10.16.0.62 cluster-ceph-02
10.16.0.63 cluster-ceph-03
Ceph存储基本架构:
Ceph存储根据其类型,可分为块存储,对象存储和文件存储。Ceph基于对象存储,对外提供三种存储接口,故称为统一存储。
Ceph的底层是RADOS(分布式对象存储系统),RADOS系统主要由两部分组成,分别是OSD和MON。
MON负责监控整个集群,维护集群的健康状态,维护展示集群状态的各种图表,如OSDMap、MonitorMap、PGMap和CRUSHMap。
OSD则用于存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查等。一般情况下一块硬盘对应一个OSD。
存储池:
很多不同用户因不同目的把对象存储在不同的存储池里,而它们都坐落于无数的OSD之上。
对象保存在不同的存储池(Pool)中,它是对象存储的逻辑组,对应不同的用户。存储池管理着归置组数量、副本数量、和存储池规则集。
归置组:
归置组(PGPlacementGroup)是对象池的片段,Ceph根据对象的Oid和一些其他信息做计算操作,映射到归置组,无数的对象被划分到不同的归置组。PG是一个逻辑概念,它在数据寻址时类似于数据库中的索引。
每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移。
OSD:
最后PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上,最终把PG中的所有对象存储到OSD节点上。
部署集群前,必看:
每台物理服务器不需要做raid。
分别分配4块给OSD使用,但是每个OSD的数据盘都得有一个journal分区,提升性能。
monitor组件需要提前手动创建目录,并挂载SSD的磁盘。
注意:不能跟OSD数据盘混用,不能放到系统盘运行。
所以3个节点都需要额外添加一块200G SSD盘,分成5个区,每个分区40G,4个分区给journal分区使用,1个分区给monitor组件使用。
根据官方的解释:
一个OSD进程对应一个逻辑磁盘。所以你有多块磁盘的话,则需要创建多个OSD进程(可以在同一服务器上),或者组建RAID0。
每个数据分区都需要一个journal分区,每次写入数据时,其实是先写入journal分区,ack请求,然后再写回数据分区。因此,为了提升性能,推荐使用SSD作为journal,
一个osd进程可以使用多个磁盘,在代码里,其实只需要一个目录,至于这个目录放在哪,是一个虚拟磁盘,还是多个磁盘组成的raid,只要能格式化成本地文件系统就可以用。数据分区和日志分区的比例,最好是根据数据分区磁盘的性能和日志分区磁盘的性能差别。
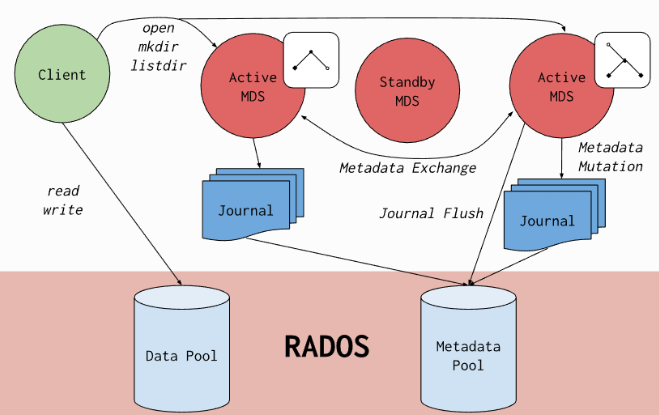
提前手动创建mon、mds组件的目录,并挂载SSD磁盘,提前分好区

生产环境 Wal 和 db 分区大小建议 按 4TB 一个 OSD,1TB 需要 40GB 的空间存放 DB,4TB 需要大于 160GB 的 SSD 存放 DB SSD 空间足够时,单个 WAL 分区分 60GB、单个 DB 分区分 180GB。 如果 SSD 空间不够时,WAL 分区分 40GB、单个 DB 分区分 60GB

journal介绍参考文档:https://www.cnblogs.com/gzxbkk/p/7725103.html
ceph所有优化文档:https://www.cnblogs.com/ashjo009/p/13526349.html
注意:BlueStore存储不支持journal。Filestore模式才支持journal
bluestore和filestore区别文档:https://blog.csdn.net/weixin_43618070/article/details/87931284
#由于4个分区给journal分区使用,1个分区给mon,4个分区给block-wal,4个分区给block-db。
由于每个节点的OSD有4个,所以其它的都要有4个分区
每个节点的db要480G,4个db分区,每个db分区120G。
每个节点的wal要160G,4个wal分区,每个wal分区40G。
每个节点的journal要180G,4个journal分区,每个journal分区给45G
#磁盘分区,创建lvm。后续方便扩容,bluestore模式忽略此步骤
#第一个journal分区
mkfs.xfs /dev/sdf
parted /dev/sdf mklabel gpt yes
parted /dev/sdf mkpart primary 0% 25%
pvcreate /dev/sdf1
vgcreate -s 64M journal01 /dev/sdf1
lvcreate -l 100%FREE -n lv1 journal01
mkfs.xfs /dev/journal01/lv1
#第二个journal分区
parted /dev/sdf mkpart primary 25% 50%
pvcreate /dev/sdf2 -y
vgcreate -s 64M journal02 /dev/sdf2
lvcreate -l 100%FREE -n lv2 journal02
mkfs.xfs /dev/journal02/lv2
#第三个journal分区
parted /dev/sdf mkpart primary 50% 75%
pvcreate /dev/sdf3 -y
vgcreate -s 64M journal03 /dev/sdf3
lvcreate -l 100%FREE -n lv3 journal03
mkfs.xfs /dev/journal03/lv3
#第四个journal分区
parted /dev/sdf mkpart primary 75% 100%
pvcreate /dev/sdf4 -y
vgcreate -s 64M journal04 /dev/sdf4
lvcreate -l 100%FREE -n lv4 journal04
mkfs.xfs /dev/journal04/lv4
#给db和wal分区,必须要,SSD盘
#db分区01
mkfs.xfs /dev/sdg
parted /dev/sdg mklabel gpt yes
parted /dev/sdg mkpart primary 0% 25%
pvcreate /dev/sdg1 -y
vgcreate -s 64M db01 /dev/sdg1
lvcreate -l 100%FREE -n lv1 db01
mkfs.xfs /dev/db01/lv1
#db分区02
parted /dev/sdg mkpart primary 25% 50%
pvcreate /dev/sdg2 -y
vgcreate -s 64M db02 /dev/sdg2
lvcreate -l 100%FREE -n lv2 db02
mkfs.xfs /dev/db02/lv2
#db分区03
parted /dev/sdg mkpart primary 50% 75%
pvcreate /dev/sdg3 -y
vgcreate -s 64M db03 /dev/sdg3
lvcreate -l 100%FREE -n lv3 db03
mkfs.xfs /dev/db03/lv3
#db分区04
parted /dev/sdg mkpart primary 75% 100%
pvcreate /dev/sdg4 -y
vgcreate -s 64M db04 /dev/sdg4
lvcreate -l 100%FREE -n lv4 db04
mkfs.xfs /dev/db04/lv4
#wal分区01
mkfs.xfs /dev/sdf
parted /dev/sdf mklabel gpt yes
parted /dev/sdf mkpart primary 0% 25%
pvcreate /dev/sdf1
vgcreate -s 64M wal01 /dev/sdf1
lvcreate -l 100%FREE -n lv1 wal01
mkfs.xfs /dev/wal01/lv1
#wal分区02
parted /dev/sdf mkpart primary 25% 50%
pvcreate /dev/sdf2 -y
vgcreate -s 64M wal02 /dev/sdf2
lvcreate -l 100%FREE -n lv2 wal02
mkfs.xfs /dev/wal02/lv2
#wal分区03
parted /dev/sdf mkpart primary 50% 75%
pvcreate /dev/sdf3 -y
vgcreate -s 64M wal03 /dev/sdf3
lvcreate -l 100%FREE -n lv3 wal03
mkfs.xfs /dev/wal03/lv3
#wal分区04
parted /dev/sdf mkpart primary 75% 100%
pvcreate /dev/sdf4 -y
vgcreate -s 64M wal04 /dev/sdf4
lvcreate -l 100%FREE -n lv4 wal04
mkfs.xfs /dev/wal04/lv4
#检查磁盘
lsblk
#注意,需要执行下面步骤的生成集群配置文件,才可以擦除磁盘。切换ceph用户执行,擦除节点数据盘,确保磁盘号不要出错,否则的话,容易把系统盘都给格式化了。下面的zap命令,集群正常运行有数据时慎用,会销毁磁盘中已经存在的分区表和数据
ceph-deploy disk zap cluster-ceph-01 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/db01/lv1 /dev/db02/lv2 /dev/db03/lv3 /dev/db04/lv4 /dev/wal04/lv4 /dev/wal03/lv3 /dev/wal02/lv2 /dev/wal01/lv1
ceph-deploy disk zap cluster-ceph-03 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/journal04/lv4 /dev/journal03/lv3 /dev/journal02/lv2 /dev/journal01/lv1 /dev/db01/lv1 /dev/db02/lv2 /dev/db03/lv3 /dev/db04/lv4 /dev/wal04/lv4 /dev/wal03/lv3 /dev/wal02/lv2 /dev/wal01/lv1
ceph-deploy disk zap cluster-ceph-02 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/journal04/lv4 /dev/journal03/lv3 /dev/journal02/lv2 /dev/journal01/lv1 /dev/db01/lv1 /dev/db02/lv2 /dev/db03/lv3 /dev/db04/lv4 /dev/wal04/lv4 /dev/wal03/lv3 /dev/wal02/lv2 /dev/wal01/lv1
存储条带大小与性能详情
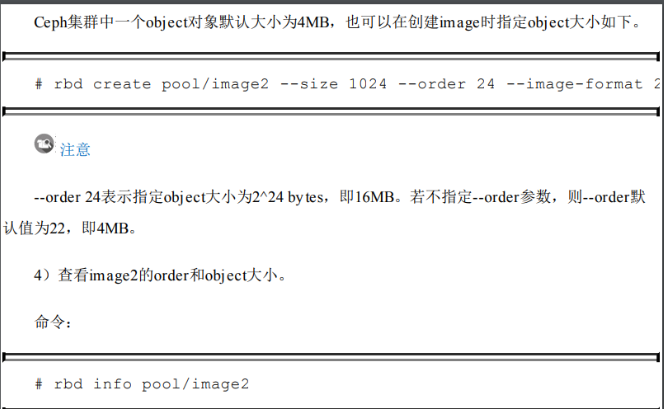
object-size(cephfs),order(rbd,默认为22):默认对象大小为4MB。
可以随时修改
rbd_default_order = 22这个配置项决定了切块的大小,默认值为22,参考了这篇文章我得到了order和size的几个关系:
| order | size |
|---|---|
| 23 | 8M |
| 22 | 4M |
| 21 | 2M |
| 20 | 1M |
http://www.xuxiaopang.com/2016/10/13/easy-ceph-RBD/
https://ivanzz1001.github.io/records/post/ceph/2019/01/05/ceph-src-code-part5_1
https://www.idcat.cn/ceph条带化介绍.html

只在任意一个节点操作,安装集群
安装完成后,如需添加某个组件的配置,直接修改配置文件,推送到各个节点,重启对应的组件。
#注意,以下安装都使用root部署
mkdir /var/lib/ceph/ceph-cluster -p
#注意:3个节点的源一定要一致,版本一致
wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | apt-key add -
echo deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-16.2.10/ buster main > /etc/apt/sources.list.d/ceph.list
#生产环境使用该版本,不支持debian10
echo deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-luminous/ $(lsb_release -sc) main > /etc/apt/sources.list.d/ceph.list
#安装ceph-deploy工具,把上面的源注释掉。装完之后,再注释掉deloy工具的源。注意,只有16.2.9版本才有deploy工具
#deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific/ buster main
deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-16.2.9/ buster main
apt-get update
apt-cache ceph-deploy
apt-get install ceph-deploy -y
chown -R ceph.ceph /var/lib/ceph
mkdir ceph-cluster
cd /var/lib/ceph/ceph-cluster
#装完deloy工具之后,把luminous版本的源注释。因为pacific源里没有工具包,只有ceph组件包
deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific/ buster main
#deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-16.2.9/ buster main
#注意:需要修改以下这个文件,否则deploy默认下载的是mimic。需要指定版本就替换成相应的版本号
find / -name "*ceph_deploy*"
vim /usr/lib/python2.7/dist-packages/ceph_deploy/install.py
#将args.release = 'mimic' 修改成 args.release = 'pacific'
#安装common、mon组件,三个节点都安装.如果不手动提前安装,deploy安装超过5分钟就会失败,所以提前安装。
apt update
apt install ceph ceph-osd ceph-mds ceph-mon radosgw ceph-mgr -y
ceph-mon --version
ceph --version
#生成集群配置文件、密钥等信息。使用ceph普通用户执行
ceph-deploy new --cluster-network 10.16.0.0/22 --public-network 10.16.0.0/22 cluster-ceph-01 cluster-ceph-03 cluster-ceph-02
#注意:配置文件的最底部要留有最少一个空行
#修改config文件,#注意:配置文件的最底部要留有最少一个空行
vim /usr/local/ceph-cluster/ceph.conf
[global]
fsid = edac8814-b42a-4axxxxx1
public_network = 0.0.0.0/0
cluster_network = 0.0.0.0/0
mon_initial_members = cluster-ceph-01, cluster-ceph-03, cluster-ceph-02, cluster-ceph-04, cluster-ceph-05
mon_host = 10.16.0.61,10.16.0.63,10.16.0.62,10.16.0.64,10.16.0.66
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_poll_default_size = 2
osd_pool_default_min_size = 1
mon_clock_drift_allowed = 2
mon_clock_drift_warn_backoff = 30
mon_allow_pool_delete = true
ms_dispatch_throttle_bytes = 2097152000
mon_max_pool_pg_num = 300000
mon_max_pg_per_osd = 3000
mon_osd_down_out_interval = 3600
mon_osd_min_down_reporters = 3
mon_osd_report_timeout = 900
osd_heartbeat_interval = 10
osd_heartbeat_grace = 60
[osd]
osd_op_thread_timeout = 90
osd_op_thread_suicide_timeout = 2000
filestore_op_thread_timeout = 180
filestore_op_thread_suicide_timeout = 2000
osd_recovery_thread_timeout = 120
osd_recovery_thread_suicide_timeout = 2000
osd_scrub_begin_hour = 0 #scrub操作的起始时间为0点
osd_scrub_end_hour = 5 #scrub操作的结束时间为5点#ps: 该时间设置需要参考物理节点的时区设置
osd_scrub_chunk_min = 1 #标记每次scrub的最小数
osd_scrub_chunk_max = 1 #标记每次scrub的最大数据块
osd_scrub_sleep = 3 #标记当前scrub结束,执行下次scrub的等待时间,增加该值,会导致scrub变慢,客户端影响反而会减小
osd_max_write_size = 512
osd_op_threads = 16
osd_disk_threads = 4
osd_map_cache_size = 1024
osd_map_cache_bl_size = 128
osd_client_message_size_cap = 1073741824
objecter_inflight_ops = 819200
bluestore_min_alloc_size_hdd = 8192
bluestore_min_alloc_size_ssd = 4096
bluestore_cache_size = 64424509440 #每个OSD的最高内存由这个参数决定,当这个参数为0,则会使用下面hdd、ssd的配置。需要根据服务器内存而定!
bluestore_cache_kv_max = 5368709120
bluestore_cache_size_hdd = 5368709120
bluestore_cache_size_ssd = 5368709120
bluestore_rocksdb_options = compression=kNoCompression,max_write_buffer_number=64,min_write_buffer_number_to_merge=32,recycle_log_file_num=64,compaction_style=kCompactionStyleLevel,write_buffer_size=4MB,target_file_size_base=4MB,max_background_compactions=16,level0_file_num_compaction_trigger=64,level0_slowdown_writes_trigger=128,level0_stop_writes_trigger=256,max_bytes_for_level_base=6GB,compaction_threads=8,flusher_threads=4,compaction_readahead_size=2MB
filestore_queue_max_ops = 50000
filestore_queue_max_bytes = 2199023255552
filestore_queue_committing_max_ops = 50000
filestore_split_multiple = 8
filestore_merge_threshold = 40
filestore_fd_cache_size = 1024
filestore_op_threads = 32
[client]
rbd_cache_enabled = true
[mgr]
mgr modules = dashboard
[client.rgw.cluster-ceph-01]
rgw_frontends = "civetweb port=80"
[client.rgw.cluster-ceph-03]
rgw_frontends = "civetweb port=80"
[client.rgw.cluster-ceph-02]
rgw_frontends = "civetweb port=80"
[client.rgw.cluster-ceph-04]
rgw_frontends = "civetweb port=80"
[client.rgw.cluster-ceph-05]
rgw_frontends = "civetweb port=80"
#注意:配置文件的最底部要留有最少一个空行
OSD 会尽可能的使用已配置的内存空间大小,但不会达到 该缓存空间 配置的最大值,因为 OSD本身也会消耗一些内存,通常还有一些内存碎片 和 分配器 占用部分内存
华为云ceph调优文档:https://support.huaweicloud.com/tngg-kunpengsdss/kunpengcephblock_05_0013.html
参数解释:
https://blog.csdn.net/weixin_40548182/article/details/109570239
https://www.cnblogs.com/ashjo009/p/13526349.html
https://people.redhat.com/bhubbard/nature/default/rados/configuration/bluestore-config-ref/
#注意,3个节点的用户id必须一致
useradd -d /var/lib/ceph -m ceph
passwd ceph
vim /etc/passwd
#把ceph用户的/bin/sh改成/bin/bash
id改成64045
vim /etc/group
id改成64045
chmod u+w /etc/sudoers
echo "ceph ALL=(root) NOPASSWD:ALL" >> /etc/sudoers
chmod 0440 /etc/sudoers
usermod -e 2099-09-09 ceph
chage -l ceph
chown -R ceph.ceph /var/lib/ceph
chown -R ceph.ceph /etc/ceph/
su - ceph
ssh-keygen
ssh-copy-id ceph@cluster-ceph-03
ssh-copy-id ceph@cluster-ceph-02
ssh-copy-id ceph@cluster-ceph-01
#加了下面这些配置,在root用户copy-id密钥,root用户和ceph用户也能使用免密登录目标ceph用户。也就是说,在root用户ssh-copy-id之后,就不需要切换ceph用户重复copy-id了。
cat > .ssh/config <<'EOF'
Host cluster-ceph-01
Hostname cluster-ceph-01
User ceph
Host cluster-ceph-02
Hostname cluster-ceph-02
User ceph
Host cluster-ceph-03
Hostname cluster-ceph-03
User ceph
EOF
scp .ssh/config root@cluster-ceph-02:/root/.ssh/
scp .ssh/config root@cluster-ceph-03:/root/.ssh/
chmod 600 ~/.ssh/config
#执行安装集群,注意输入密码,交互式
ceph-deploy install cluster-ceph-01 cluster-ceph-03 cluster-ceph-02
#安装monitor组件,使用ceph用户。注意:配置文件的Public network网段必须要有子网掩码,否则会报错。0.0.0.0/0 没有授权免密登录,注意输入密码,交互式
ceph-deploy mon create-initial
#验证mon组件是否正常,注意:system里后面的是主机名
ps -ef |grep ceph-mon
systemctl status ceph-mon@cluster-ceph-01.service
#admin密钥分发给所有节点
ceph-deploy admin cluster-ceph-01 cluster-ceph-03 cluster-ceph-02
#授权ceph用户所有节点,否则会执行ceph命令失败
apt-get install acl -y
setfacl -m u:ceph:rw /etc/ceph/ceph.client.admin.keyring
#验证集群状态、版本信息
ceph versions
#查看各组件的状态,mon组件3台节点加入就会有显示主机名
ceph -s
#解决ceph -s里的health: HEALTG_WARN
警告信息:mons are allowing insecure global_id reclaim
执行命令:
ceph config set mon auth_allow_insecure_global_id_reclaim false
#安装mgr组件(管理守护进程)
apt -y install ceph-mgr
#查看mgr版本
ceph-mgr --version
#初始化mgr组件,注意输入密码
ceph-deploy mgr create cluster-ceph-01 cluster-ceph-03 cluster-ceph-02
#各个节点验证mgr进程和服务状态
ps -ef |grep ceph-mon
systemctl status ceph-mgr@cluster-ceph-01.service
ceph -s
ceph versions
#所有节点安装公共组件common
apt -y install ceph-common
#初始化OSD节点
ceph-deploy install --no-adjust-repos --nogpgcheck cluster-ceph-01 cluster-ceph-03 cluster-ceph-02
#安装OSD节点运行环境
ceph-deploy install --release pacific cluster-ceph-01
ceph-deploy install --release pacific cluster-ceph-03
ceph-deploy install --release pacific cluster-ceph-02
#列出OSD节点磁盘
ceph-deploy disk list cluster-ceph-02
ceph-deploy disk list cluster-ceph-03
ceph-deploy disk list cluster-ceph-01
#第一个节点部署OSD组件,,BlueStoe模式,注意wal、db的分区名字。4个osd就要执行4次
ceph-deploy osd create --data /dev/sdc --block-wal /dev/wal01/lv1 --block-db /dev/db01/lv1 --bluestore cluster-ceph-01
ceph-deploy osd create --data /dev/sdg --block-wal /dev/wal02/lv2 --block-db /dev/db02/lv2 --bluestore cluster-ceph-01
ceph-deploy osd create --data /dev/sdf --block-wal /dev/wal03/lv3 --block-db /dev/db03/lv3 --bluestore cluster-ceph-01
ceph-deploy osd create --data /dev/sde --block-wal /dev/wal04/lv4 --block-db /dev/db04/lv4 --bluestore cluster-ceph-01
#查看状态
systemctl status ceph-osd@0
systemctl status ceph-osd@1
systemctl status ceph-osd@2
systemctl status ceph-osd@3
ceph osd tree
ps -ef | grep ceph
#第二个节点部署OSD组件,BlueStoe模式
#查看状态
#第三个节点部署OSD组件,BlueStoe模式
#查看状态
#验证集群
ceph osd out osd.3
#看到归置组状态变为active+clean,迁移完成(Control-c 退出。)
ceph -w
systemctl stop ceph-osd@3
ceph osd purge 3 --yes-i-really-mean-it
ceph osd tree
#移除OSD(osd.3)后重新加到集群
#删除对应的PV
pvscan
vgremove ceph-176cb958-26de-41d5-b9fb-5f9fc4ae13f2 -y
#使用ceph用户执行,擦除数据盘,注意别搞错盘
ceph-deploy disk zap cluster-ceph-01 /dev/sde
#添加OSD到集群
ceph-deploy osd create --data /dev/sde --block-wal /dev/wal04/lv4 --block-db /dev/db04/lv4 --bluestore cluster-ceph-01
ceph osd tree
#安装dashboard
apt install ceph-mgr-dashboard -y
#创建mgr目录并生成证书
mkdir mgr-dashboard
cd mgr-dashboard
openssl req -new -nodes -x509 -subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 -keyout dashboard.key -out dashboard.crt -extensions v3_ca
#开启dashboard插件
ceph mgr module enable dashboard --force
#配置监听ip,此处必须设置监控地址为0.0.0.0,而不能是直接IP地址,因为其监控的是所有本地地址包括IPV4和IPV6,同时也不能禁用IPV6地址
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0
#配置监听端口
ceph config set mgr mgr/dashboard/server_port 8444
#禁用ssl
ceph config set mgr mgr/dashboard/ssl false
#设置用户和密码,注意:必须创建文件,把密码写入文件里,读取文件的方式设置密码,否则创建失败。一定要加管理员角色,否则没权限
cat > password.txt <<'EOF'
xxxxxxxxx
EOF
ceph dashboard ac-user-create admin -i password.txt administrator
#删除用户命令,可忽略此步骤
ceph dashboard ac-user-delete admin
#重启dashboard插件
ceph mgr module disable dashboard
ceph mgr module enable dashboard --force
#查看mgr输出地址
ceph mgr services
#开启prometheus监控
ceph mgr module enable prometheus
ceph mgr services
#访问dashboard地址即可
#prometheus添加监控项,注意格式,alias: ceph不能修改,否则会导致promethes无法创建
vim prometheus-additional.yaml
- job_name: 'ceph'
relabel_configs:
- source_labels: ["cluster"]
replacement: "ceph"
action: replace
target_label: "clusters"
static_configs:
- targets: ['10.16.0.61:9283']
labels:
alias: ceph
grafana模板地址:https://grafana.com/grafana/dashboards/?search=Ceph
#grafana模板导入
2842
#添加告警规则
vim kubernetes-prometheusRule.yaml
- name: ceph.rules
rules:
- alert: CephTargetDown
expr: up{job="ceph"} == 0
for: 10m
#for: 1m
labels:
severity: critical
cluster_name: ceph
annotations:
description: CEPH target down for more than 2m, please check - it could be a either exporter crash or a whole cluster crash
summary: CEPH exporter down
- alert: CephErrorState
expr: ceph_health_status > 1
for: 5m
labels:
cluster_name: ceph
severity: critical
annotations:
description: Ceph is in Error state longer than 5m, please check status of pools and OSDs
summary: CEPH in ERROR
- alert: CephWarnState
expr: ceph_health_status == 1
for: 30m
labels:
cluster_name: ceph
severity: warning
annotations:
description: Ceph is in Warn state longer than 30m, please check status of pools and OSDs
summary: CEPH in WARN
- alert: OsdDown
expr: ceph_osd_up == 0
for: 30m
labels:
cluster_name: ceph
severity: warning
annotations:
description: OSD is down longer than 30 min, please check whats the status
summary: OSD down
expr: ceph_pg_total - ceph_pg_active > 0
for: 5m
labels:
cluster_name: ceph
severity: critical
annotations:
description: Some groups are unavailable on {{ $labels.cluster }}. Please check their detailed status and current configuration.
summary: PG UNAVAILABLE [{{ $value }}] on {{ $labels.cluster }}
- alert: CephOsdReweighted
expr: ceph_osd_weight < 1
for: 1h
labels:
cluster_name: ceph
severity: warning
annotations:
description: OSD {{ $labels.ceph_daemon}} on cluster {{ $labels.cluster}} was reweighted for too long. Please either create silent or fix that issue
summary: OSD {{ $labels.ceph_daemon }} on {{ $labels.cluster }} reweighted - {{ $value }}
- alert: Disk(s) Near Full
expr: (ceph_osd_stat_bytes_used / ceph_osd_stat_bytes) * 100 > 85
for: 2m
labels:
severity: critical
cluster_name: ceph
annotations:
summary: "Disk(s) Near Full"
description: "This shows how many disks are at or above 85% full. Performance may degrade beyond this threshold on filestore (XFS) backed OSD's."
#部署servciemonitor监控ceph
vim prometheus-cephService.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: ceph
name: ceph
namespace: monitoring
spec:
clusterIP: None
ports:
- name: api
port: 9283
protocol: TCP
targetPort: 9283
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: ceph
name: ceph
namespace: monitoring
subsets:
- addresses:
- ip: 10.16.0.61
nodeName: 10.16.0.61
ports:
- name: api
port: 9283
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: ceph
name: ceph
namespace: monitoring
spec:
endpoints:
- interval: 10s
port: api
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
k8s-app: ceph
#修改配置文件,修改rgw的默认端口,默认为7480,修改成80端口
#将配置文件推送到各个节点
#部署rgw环境
#安装rgw组件,s3对象存储
#创建radosgw的管理员用户
#查看用户AK
#把AK写入文件里,导入文件的形式授权给dashboard
#安装s3命令
#安装mds组件,cephfs文件存储
#生成配置文件,输入rados用户的Access Key、Secret Key。S3 Endpoint [s3.amazonaws.com] 输入ip加端口
port template for accessing a bucket [%(bucket)s.s3.amazonaws.com] 输入ip加端口
Use HTTPS protocol [Yes]: no 取消https
Test access with supplied credentials? [Y/n] n
Save settings? [y/N] y
其它保持默认
s3cmd --configure
#测试s3命令创建桶、上传、下载、删除、桶存储大小
#创建文件系统的存储池,nfs需要使用
#创建多个fs,加上mds_namespace参数
#生成客户端的密钥,后面挂载该文件存储需要使用key
#获取挂载的密钥,保存好密钥
#任意客户端创建目录,测试挂载该文件系统。注意:name=cephfs要和ceph里的文件系统名字一致
#每个节点都必须安装nfs-ganesha插件,否则其它客户端无法使用nfs挂载。
#客户端挂载测试
#安装setfattr命令
#安装rbd命令
#创建块设备使用的pool,块设备可以给其它机器挂载使用,相当于磁盘。
#初始化pool
#创建块设备,200G容量。单位是MB
#关闭exclusive-lock, object-map, fast-diff, deep-flatten,否则客户端无法挂载该块设备
#使用其它机器挂载,可以是物理机、虚拟机等等。前提是需要安装对应版本的ceph-common软件
#查看磁盘,可以格式化挂载使用
#客户端取消挂载块设备,rdb
#增加块大小
#缩小块大小,需要加上参数,否则报错